python爬虫学习--pixiv爬虫(3)--关注用户作品爬取
国际榜的爬取算是我们爬取pixiv的一小步
接下来就是爬取关注用户的作品
首先我们来看一下正在关注的页面

这个userdata中有我们目前需要的所有信息,我们的第一个目标就是将这些信息全部提出来...
为了方便...我们可以先将这个页面以htm的格式保存在本地...
# coding:utf-8
import re
from bs4 import BeautifulSoup
webfile = open('C:\Users\monburan\Desktop\user.htm','r') #先打开这个文件
soup = BeautifulSoup(webfile)
user_data = soup.find_all(class_="userdata") #用bs分析界面,将userdata提取出来
到这里都是我们之前一直用着比较熟练的部分
正在关注界面没有排名和序号之类的东西,前面我们用for来解决的问题不能在这里用了
也就是不能用re.search来每次获取一条数据了...
这次我们可以用re.findall来代替它,re.findall可以获取字符串中所有匹配的字符串...并返回一个list
uname_list = re.findall(re.compile('data-user_name="(.*?)"',re.S),str(user_data))
uid_list = re.findall(re.compile('data-user_id="(.*?)"',re.S),str(user_data))
先获取我们最需要的用户id和用户名这两个list[]...
这堆乱糟糟的东西瞅着都闹心,已知一个页面内有48个userdata那我们就先处理下这些信息,顺便将这些用户作品页的url构造出来
for i in range(0,48):
user_name = uname_list[i]
user_id = uid_list[i]
user_page = 'http://www.pixiv.net/member_illust.php?id=' + user_id
print user_name , user_id + '\n->' + user_page
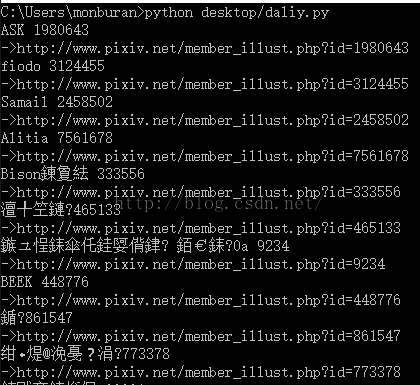
这样我们需要的信息就好了...
pixiv的关注页面一次只能显示48个用户..如果超过了就超过了我们爬取的范围了...所以我们要解决这个问题
http://www.pixiv.net/bookmark.php?type=user&rest=show&p=2
通过观察url这时我们就可以写出来如何抓取后面页数的的功能了
![]() 这里有我的关注数
这里有我的关注数
user_num = re.search(re.compile('(\d+)',re.S),str(soup.find_all(class_="unit-count")))
if int(user_num.group(1))/48!=0:
u_p = int(user_num.group(1))/48 + 1
else :
u_p = int(user_num.group(1))/48u_p就可以表示页数
我们先选一个用户的作品页看一下好了...

这里是他的作品数...每页显示20幅作品...需要4页这样的话只爬取一个界面肯定不能爬取全部...
我们将页面翻至第二页...这个时候我们发现浏览器的url也有了点小变化
我们分析type控制了这个页面对应图片的种类p控制了页数
这样我们就可以继续我们信息采集的工作了...为了方便...还是将网页保存到本地再分析
webfile1 = open('C:\Users\monburan\Desktop\person.htm','r')
soup = BeautifulSoup(webfile1)
pic_num = re.search(re.compile('(\d+)',re.S),str(soup.find(class_="count-badge")))
print int(pic_num.group(1))
if (int(pic_num.group(1))%20)!=0:
p = (int(pic_num.group(1))/20) + 1
else :
p = int(pic_num.group(1))/20还是用类似刚才的方法就可以将页数处理出来
到这里我们就可以想办法将这些代码加到前几天写的那个pixiv的里面去了
先在__init__里面加入需要的变量
self.p_your_follow_url = 'http://www.pixiv.net/bookmark.php?type=user' #关注页面url
Choice_Pixiv()这里添加到我们新功能的选项
if (self.p_choice == '2'):
try:
p_page = opener.open(self.p_your_follow_url)
p_your_follow = p_page.read().decode('UTF-8')
except urllib2.URLError,e:
if hasattr(e,"reason"):
print "连接错误:",e.reason
创建一个方法Pixiv_Your_Follow()
def Pixiv_Your_Follow(self,opener,p_your_follow):
soup = BeautifulSoup(p_your_follow)
user_num = re.search(re.compile('(\d+)',re.S),str(soup.find_all(class_="unit-count")))
print '共有' + str(user_num.group(1)) + '位正在关注的画师...'
if int(user_num.group(1))/48!=0:
u_p = int(user_num.group(1))/48 + 1
else :
u_p = int(user_num.group(1))/48
for i in range(1,u_p+1):
f_url = 'http://www.pixiv.net/bookmark.php?type=user&rest=show&p=' + str(i)
创建一个User_Data()用它来处理获取的画师信息,并将这些信息汇集成我们进行图片爬取的信息
def User_Data(self,opener,f_url):
soup = BeautifulSoup(opener.open(f_url))
uname_list = re.findall(re.compile('data-user_name="(.*?)"',re.S),str(soup.find_all(class_="userdata")))
uid_list = re.findall(re.compile('data-user_id="(.*?)"',re.S),str(soup.find_all(class_="userdata")))
for h in range(0,len(uid_list)):
user_name = uname_list[h]
user_id = uid_list[h]
user_page = 'http://www.pixiv.net/member_illust.php?id=' + user_id
os.mkdir(r'E:/pixivdata/'+user_id+'/')
user_info = BeautifulSoup(opener.open(user_page))
pic_num = re.search(re.compile('(\d+)',re.S),str(user_info.find(class_="count-badge")))
print '画师:' + user_name + '共有' + pic_num.group(1) + '幅作品'
if (int(pic_num.group(1))%20)!=0: #计算当前有多少关注页
p = (int(pic_num.group(1))/20) + 1
else :
p = int(pic_num.group(1))/20
为了方便我们这里再在Tools()里写一个方法用来放分类找url的功能...
def Pic_Style_M(self,soupfile):
single = re.findall(re.compile('<.*?work\s_work\s".*?href="(.*?)">',re.S),soupfile)
multiple = re.findall(re.compile('<a.*?work\s_work\smultiple\s.*?href="(.*?)">',re.S),soupfile)
video = re.findall(re.compile('<a.*?work\s_work\sugoku-illust\s.*?href="(.*?)">',re.S),soupfile)
manga = re.findall(re.compile('<a.*?work\s_work\smanga\smultiple\s.*?href="(.*?)">',re.S),soupfile)
return single,multiple,manga,video
这里就要写一些循环来将这些画师作品页中的url提取出来并加以分析进行下载
for i in range(1,p+1):
pic_s = self.tool.Pic_Style_M(str(BeautifulSoup(opener.open(user_page + '&type=all&p=' + str(i)))))
single = pic_s[0]
multiple = pic_s[1]
manga = pic_s[2]
video = pic_s[3]
print '第'+str(i)+'页共有' + str(len(single)) + '张单图'
for j in range(0,len(single)):
p_num = '1'
p_url = self.tool.removesomething('http://www.pixiv.net/' + single[j])
p_id = re.search(re.compile('(\d+)',re.S),p_url)
self.Download_Pic(p_num,opener,p_url,p_id.group(1),user_id)
print '第'+str(i)+'页共有' + str(len(multiple)) + '套多图'
for k in range(0,len(multiple)):
p_num = 'more'
p_url = self.tool.removesomething('http://www.pixiv.net/' + multiple[k])
p_id = re.search(re.compile('(\d+)',re.S),p_url)
self.Download_Pic(p_num,opener,p_url,p_id.group(1),user_id)
print '第'+str(i)+'页共有' + str(len(manga)) + '套漫画'
for l in range(0,len(manga)):
p_num = 'more'
p_url = self.tool.removesomething('http://www.pixiv.net/' + manga[l])
p_id = re.search(re.compile('(\d+)',re.S),p_url)
self.Download_Pic(p_num,opener,p_url,p_id.group(1),user_id)
if len(video)=0 :
print '没有动图...'
else:
print'第'+str(i)+'页共有' + str(len(video)) + '张动图,主动放弃...'
最后加以完善...
def User_Data(self,opener,f_url):
soup = BeautifulSoup(opener.open(f_url))
uname_list = re.findall(re.compile('data-user_name="(.*?)"',re.S),str(soup.find_all(class_="userdata")))
uid_list = re.findall(re.compile('data-user_id="(.*?)"',re.S),str(soup.find_all(class_="userdata")))
for h in range(0,len(uid_list)):
user_name = uname_list[h]
user_id = uid_list[h]
user_page = 'http://www.pixiv.net/member_illust.php?id=' + user_id
os.mkdir(r'E:/pixivdata/'+user_id+'/')
user_info = BeautifulSoup(opener.open(user_page))
pic_num = re.search(re.compile('(\d+)',re.S),str(user_info.find(class_="count-badge")))
print '画师:' + user_name + '共有' + pic_num.group(1) + '幅作品'
if (int(pic_num.group(1))%20)!=0:
p = (int(pic_num.group(1))/20) + 1
else :
p = int(pic_num.group(1))/20
massage1 = [] #用来存放爬取下来的单图url
massage2 = [] #用来存放爬取下来的多图url
massage3 = [] #用来存放爬取下来的漫画url
for i in range(1,p+1):
pic_s = self.tool.Pic_Style_M(str(BeautifulSoup(opener.open(user_page + '&type=all&p=' + str(i)))))
single = pic_s[0]
multiple = pic_s[1]
manga = pic_s[2]
video = pic_s[3]
print '第'+str(i)+'页共有' + str(len(single)) + '张单图'
for j in range(0,len(single)):
p_num = '1'
p_url = self.tool.removesomething('http://www.pixiv.net/' + single[j])
p_id = re.search(re.compile('(\d+)',re.S),p_url)
massage1.append(p_url+'\n')
self.Download_Pic(p_num,opener,p_url,p_id.group(1),user_id)
print '第'+str(i)+'页共有' + str(len(multiple)) + '套多图'
for k in range(0,len(multiple)):
p_num = 'more'
p_url = self.tool.removesomething('http://www.pixiv.net/' + multiple[k])
p_id = re.search(re.compile('(\d+)',re.S),p_url)
massage2.append(p_url+'\n')
self.Download_Pic(p_num,opener,p_url,p_id.group(1),user_id)
print '第'+str(i)+'页共有' + str(len(manga)) + '套漫画'
for l in range(0,len(manga)):
p_num = 'more'
p_url = self.tool.removesomething('http://www.pixiv.net/' + manga[l])
p_id = re.search(re.compile('(\d+)',re.S),p_url)
massage3.append(p_url +'\n')
self.Download_Pic(p_num,opener,p_url,p_id.group(1),user_id)
if len(video)== 0 :
print '没有动图...'
else:
print'第'+str(i)+'页共有' + str(len(video)) + '张动图,主动放弃...'
singledata = open('E:/pixivdata/'+user_id+'/single.txt','w') #将信息保存下来
singledata1.writelines(massage1)
singledata1.close()
multipledata = open('E:/pixivdata/'+user_id+'/multiple.txt','w')
multipledata.writelines(massage2)
multipledata.close()
mangadata3 = open('E:/pixivdata/'+user_id+'/manga.txt','w')
mangadata3.writelines(massage2)
mangadata3.close()