RBM总结
Boltzmann Machine其实是一种无向图,里面的节点是互相连接的,但不一定是全连接,也即不是每个节点都两两相连,连接着的两个节点之间就有一个权值。为理解方便就假设节点只能取值为0或者1,有些节点值是已知的,有些是未知的,把已知的节点集合记为V,未知的节点集合记为H,这样就把所有节点分成两个集合,其实集合V就可以认为是visible层,集合H就可以认为是hidden层。如果hidden层中的节点都不互相连接,visible层中的节点也都不互相连接,那么就成为了RBM模型。
为了理解方便,考虑训练样本是一些二值图像,将其进行向量化,得到二值向量的一个集合作为训练集,这些训练集就可以构建一个两层的成为RBM的网络,对于这些像素值就可以关联为visible层中的节点,因为它们像素值是”可见的”(像素值已知),特征的检测器就关联为hidden层中的节点。根据Hopfiled(了解神经网络的应该没什么人不知道他了,Hopfiled Network)在1982年给出的一个能量函数的定义,定义一个函数来标记hidden中的某一个节点h和visible层中的某一个节点v之间的能量:

而网络给每个visible层节点分配的概率值就是把所有可能的与它相连的hidden层节点的概率值相加,也即:
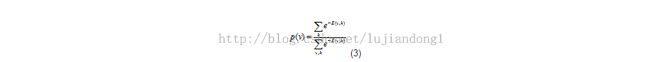
在传统的神经网络中就可以知道,网络分配给每个训练样本的概率值是可以调节的,通过对weight和bias的调整来使该样本的能量降低并提高其它样本的能量,就可以使这个概率值变大,这其实从(2)式也可以看出,随着能量递增,概率值是递减的。
Hinton提出了一个较为快速的方法,他先把所有的visible层节点的状态设置为一个向量,使用(5)式得到所有hidden层节点的概率值,并根据这个概率值将节点设置为1或者0(将概率值与一个随机生成的(0,1)之间的浮点数去比较,大于该随机数则该节点状态量置为1,否则为0),再由(6)式返回计算visible层节点值(也即重构过程)
在使用CD时,必须注意要把hidden节点值置为二值化形式(0或1),而不是直接采用其概率值本身,因为这样做的话,在进行重构的时候,每个hidden节点就和visible节点的真实值发生了联系,这会导致违反如下基本规则:每个hidden节点最多只能有一个状态量,也即它不能既是0又是1。然而,在最后一次更新hidden节点时,就不可以使用二值状态量了,因为此时已经没有什么是依赖于”哪个状态量被选中”,也即哪个状态为0或为1并不造成什么影响,所以应该是使用(5)式所得的概率值本身,以避免不必要的采样噪声,在使用CDn时只有最后一次更新才可以如此使用概率值本身。
总结:CD采样:v1,h1,v2,h2-----v1-输入的采样数据(可以是浮点数,整数,好像应该归一化到[0,1]),v1通过RBM网络映射到h1
h1必须转化到0,1,即h1必须为整型,h1通过RBM进行重构得到v2,也必须是0,1(整型),v2再通过RBM映射到h2,可以是double型