简单解释性语言解释器设计
语言设计要点
数字,字符串,列表,布尔
数字:
以[0~9]或'-'开头
不区分整数,浮点数
字符串:
以双引号""包含
串内可是任意字符,可写可读
列表:
以方括号[]包含,以逗号,分隔
元素可是任意类型
元素类型可不一致
操作:
操作名+参数
基本原语:
make <string> <value>
将<value>绑定到<string>上
如果<value>的形式是包含两个列表元素的列表([<list1>, <list2>])的形式,也认为是一个函数
<list1>作为参数列表
<list2>作为操作列表
thing <string>
返回<string>所绑定的值
print <value>
输出<value>
input
返回一个从标准输入读取的值,读取一个值
inputline
返回一个从标准输入读取的值,读取一行
运算符
add, sub, mul, div, mod
<> <number> <number>
数值运算
and, or
<> <bool> <bool>
布尔运算
not
not <bool>
取反
if <bool> <list1> <list2>
如果<bool>为真,则执行<list1>,否则执行<list2>
cat <list1> <list2>
列表操作,将<list1>和<list2>合并成一个列表
join <list> <value>
将<value>作为<list>的最后一个元素加入到<list>中
first <list>
返回<list>的第一个元素
butfirst <list>
返回<list>除第一个元素外剩下的列表
函数定义和调用:
定义:
make <string> [<list1>, <list2>]
<string>为函数名
<list1>为参数列表
<list2>为操作列表
调用:
<functionName> <arglist>
<functionName>为make中定义的函数名,不需要双引号""
<arglist>是参数列表,<arglist>中的值和函数定义时的<list1>中名字进行一一对应绑定
一. 解释器构成
解释器主要由以下几个部分构成,分别是词法分析器,语法分析器,解释器,以及内存管理机制。
其构成见下图:
源代码经由词法分析器转换为token流,然后语法分析器将token流转换为单个语句的内部数据结构,该内部数据结构交由解释器解释执行。这里定义两张表,分别为函数入口表和变量映射表。均在执行make语句的时候由解释器插入新的表项。内存管理机制管理变量映射表,通过垃圾回收机制收回相关变量的内存空间。

二.内存模型
1. 基本类型存储
目标语言的基本类型有数字,字符串,列表,布尔。下面给出各个类型在内存中的存储和相关方法。
1) 数字型
数字型不区分浮点和整数,在内存中一律占四个字节。使用第一个bit表示是浮点型还是整数型。然后根据相应的方法得到值。
相关方法:
Bool judge(NUM *point);
判断NUM变量是int型还是float型。
Int getIntNum(NUM *point);
point为num类型存储地址。返回int型变量的值。
Float getFloatNum(NUM *point);
返回float型变量的值。
getNewFloatNum(float num);
获得新的地址空间存放新的float型num变量,返回首地址。
getNewIntNum(int num);
获得新的地址空间返回新的int型num变量,返回首地址。
2) 字符串型
字符串型不定长。在首地址处给出四个字节表示长度。
相关方法:
getStrLength(STR *point);
point 为str型存储地址。因为字符串首地址的四个字节存放了字符串长度,因此返回getNum(NUM *point);即为字符串长度。
getNewStr(int length);
获得length+4长度的地址空间存放STR,返回首地址。
setStr(STR *point, string str);
将point所指内存地址空间赋为给出的字符串str。
String getStr(STR *point);
返回point所指的地址空间的string值。
3) 列表
列表在开始地址给出四个字节表示列表元素个数。每一项占四个字节,为相对应的变量token地址。
相关方法:
Int getListLength(LIST *point);
返回point所指列表长度。方法与返回STR变量类型长度相同。
getNewList(int length);
在内存中申请4*length+4的内存地址用来存放STR,返回首地址。因为列表中存放的是每一项值所对应的token的地址,每一项地址都为4个字节,所以这里要乘以4。加上的4代表存放列表长度所需空间。
addNewEle(token t);
从内存中申请length+1的内存空间存放新的token。删除原来的地址空间。然后将原来的列表和新的token移动到新的内存空间,在变量表中改变LIST值存放的地址。
SetList(LIST L1, LIST l2);
首先判断l1的长度是否和l2相同,如果不相同则申请和l2相同长度的内存空间给l1,然后复制l2的内存内容到l1中。否则直接复制。
GetElement(list l, int index);
返回index所对应的列表项的内容。
4) 布尔类型
使用4个字节存放bool类型的值。
相关方法:
GetBool(BOOL *point);
返回bool类型的值。
2.内存的申请和释放
相关方法
GetMemory(int length);
获得length长度的地址空间,返回首地址。
DeleteMemory(void *point, int length);
删除从point开始的长度为length的地址空间。
3. 垃圾回收机制
本解释器使用自动垃圾回收机制。在实现上采用与python相同的方法。为每一个变量设置其引用计数。
引用计数增加情况:
1)对象被创建:make <string> <value>
2)被作为参数传递给函数:<functionName> <arg>
3)被作为新的元素插入到list中:join <list> <value>
4)被作为第一个元素返回:first<arg>
5)被引用:thing<arg>
引用计数减少的情况:
1) 作为本地应用离开了其作用域,如上面的<functionName><argList>中function执行结束。则argList中的实参的引用计数减一。
2) 被赋值给其它变量:make<string><thing<arg>>;
垃圾回收线程每隔一段时间遍历引用计数列表,当引用计数为0时,删除对应变量,回收内存空间。另外对于局部变量,当对应函数结束时即进行销毁。
三.词法分析器设计
1. Token
词法分析器的主要功能是将程序输入转换为Token流,即词法单元。每一个Token的构成为(type, value),type表示单词类型,value表示单词具体的值,比如”3”这个常量经过词法分析就变成了(‘INT’, ’3’), 根据语言特点,这里列出token可能的类型和值。
| Type |
Value |
| STR |
字符串(”…”)以双引号包含,可读可写 |
| NUM |
数字类型,以[0~9]包含,不区分浮点整形 |
| BOOL |
true/false |
| NEG |
- |
| LEBACK |
[ |
| RIBACK |
] |
| COMMA |
, |
| QUOT |
“ |
| make |
make(绑定语句) |
| thing |
thing(返回绑定的值) |
| |
print(输出值) |
| input |
Input(从标准输入流输入一个值) |
| inputline |
Inputline(从标准输入流输入一行值 |
| add |
add |
| sub |
sub |
| mul |
mul |
| div |
div |
| mod |
mod |
| and |
and |
| or |
or |
| not |
not |
| if |
if |
| cat |
cat |
| join |
join |
| first |
first |
| butfirst |
butfirst |
| function |
不以引号包含的字符串 |
| Greater |
greater |
| less |
less |
| equal |
equal |
2.token的存储
这里设置一个列表token_list存储token,每当返回一个token即把该token放入该链表中。之后语法分析器只要遍历该list即可。
这里定义token的结构。
Type表示上面提到的token的类型,这里的value一律为值的地址。
3.词法分析器实现算法
词法分析器使用LL(1)实现。
所谓LL(1),第一个L表明自顶向下分析是从左向右扫描输入串,第2个L表明分析过程中将使用最左推导,1表明只需向右看一个符号便可决定如何推导,即选择哪个产生式(规则)进行推导。算法执行的过程是:读取单个字符,预测词法类型,调用相应函数取得词法value,返回token。当然对于单个字符可以直接返回token而不需要调用函数。采用递归调用的方式。
落实到我们要解释的语言,这里列出可能的读入字符和调用函数。
| [0-9] |
Match_num(stream, current); 往后遍历直到空格返回之前的字符串,如果在读到空格之前读到了非[0-9|.]字符,则返回error。Stream表示输入流,current表示当前字符id。下同。 |
| “ |
Match_string(stream, current); 往后遍历直到读到”返回中间的字符串,用双引号包围。如果达到EOF之前还没有读到”, 则返回error。 |
| - |
Return (NEG, ‘-‘); |
| [ |
Return (LEBACK, ‘[‘) ; |
| ] |
Return (RIBACK, ‘]’); |
| , |
Return(COMM,’,’); |
| = |
Return(EQUAL,’=’); |
| a |
Match ‘and’ or ‘add’ if not return Match_function(stream, current); |
| b |
See if match ‘butfirst’, else return Match_function(stream, current); |
| c |
See if match ‘cat’ , else return match_function(stream, current); |
| d |
See if match ‘div’, else return Match_function(stream, current); |
| e |
See if match ‘equal’ or ‘input’ or ‘if’, else return Match_function(stream, current); |
| f |
See if match ‘first’ or ‘false’, else return Match_function(stream, current); |
| G |
See if match ‘greater’ or ‘input’ or ‘if’, else return Match_function(stream, current); |
| i |
See if match ‘inputline’ or ‘input’ or ‘if’, else return Match_function(stream, current); |
| j |
See if match ‘join’, else return Match_function(stream, current); |
| L |
See if match ‘less’ or ‘input’ or ‘if’, else return Match_function(stream, current); |
| m |
See if match ‘make’ or ‘mul’ or ‘mod’, else return Match_function(stream, current); |
| o |
See if match ‘or’, else return Match_function(stream, current); |
| p |
See if match ‘print’, else return Match_function(stream, current); |
| s |
See if match ‘sub’, else return Match_function(stream, current); |
| t |
See if match ‘thing’ or ‘true’, else return Match_function(stream, current); |
4.对token中value的存储
上面已经提到token中存放的是value的地址,因此在做match_string, match_num, match_bool的时候首先需要申请内存将值存放,并将相应地址存放到token.value,然后返回。
为了保证词法分析效率,在做词法分析中不实现list,list的实现是在做语法分析的时候实现的。
四. 语法分析器设计
通过以上的词法分析器,我们已经把源代码转换为了token流。下一步是通过语法分析器分析语法并转换为便于解释器执行的内部数据结构。
1. 语法解析树
在开始设计语法分析器之前,有必要首先构造语法解析树,语法分析器根据解析树对语法进行分析,并转换为内部形式,以便于解释器解释执行。
因为目标语言语法简单,语句中元素相对固定。所以这里不使用传统的语法分析树,而是使用简化的语法分析树,使用每一个节点代表一个token,而从根部到叶子节点的一条通路即代表一类语句。通过遍历该树就可以分析出当前语句是否有语法错误,并且最后将语句转化为内部数据结构。根据我们语言的语法规则,我们可以获得以下的语法分析树。

2.内部命令数据结构
为了使解析后的数据便于解释器解释执行,应此需要将其装换为内部数据结构。这里设计内部数据结构如下。
其中的type表示命令类型,这里暂且设置为以上解析树从左到右的顺序从0到n编码。
value_list表示语句中除去了关键字如if,add后剩下的代表值的token的list。

3.list的实现
为了保证词法分析效率,在词法分析时并没有实现list。List的实现在语法分析中进行。下面给出match_list的伪代码。通过以下代码获得list的token。首先判断列表中的元素是否为基本数据类型,如果是,即加入列表中。只要有一个不是,就返回错误。
4.具体实现算法
在语法分析器的实现中,通过在上面的解析树上进行匹配。当然,这里并不构造解析树结构,而是在每个节点调用相应的函数进行匹配。如果匹配中在到达根节点之前发生匹配错误,即返回错误信息。否则返回相应的内部数据结构。另外需要注意greater,equal和less在匹配时需要注意两个基本数据结构的类型是否相同,如果不相同则返回错误,并且这里的数据类型仅包括STR和NUM, 对list和bool类型不做比较操作。这里以if语句为例具体说明。
If语句的语法规范为if <bool> list1 list2
因此匹配函数如下。
因此对每个语句匹配过程就是按照分析树对每个结点逐个匹配。其它语句匹配类似。
四. 解释器的实现
按照上面的方法,现在已经得到了通过语法检查的内部命令结构,可以对该指令结构进行解释。
解释的过程为首先根据struct的type决定语句类型,之后调用相应的解释函数进行解释。
下面具体列出对各种语句的解释执行方法。
1. make语句
make <string> <value>
将<value>绑定到<string>上
如果<value>的形式是包含两个列表元素的列表([<list1>, <list2>])的形式,也认为是一个函数。<list1>作为参数列表,<list2>作为操作列表。
为了实现make指令,需要定义两张表,一张为变量映射表,存放了变量名string和相对应的token的地址。另一张为函数入口表,存放了函数名和相对应list token的地址。当然也可以将两张表合为一张,但是为了查找方便,这里将其分别管理。为了提高查找效率,使用hash表实现这两张表。
这里定义两张表项的结构分别为:

下面给出do_make的代码。首先判断是否为函数,如果是则加入函数入口表,如果不是则加入变量映射表。在参数列表中我们不给出参数类型,只给出参数名,所以需要验证参数列表中的参数名是否都符合规范,符合规范的意思均要为字符串,且不能和语言已有的关键字同名。对于执行列表,因为是执行语句,所以可以不做判断,在执行时再做处理。另外如果在遍历函数列表时发现原来已有该函数名的定义,则自动更新该函数定义。
2. thing <string>
功能:返回<string>所绑定的值。
thing语句只需通过hash表提供的接口通过index查找,返回字符串对应的值token,如果hash表中查找不到该变量定义,则报NAME_NOT_DEFINED_ERROR。伪代码如下。

3. print <value>
功能:输出<value>
调用系统标准输出函数输出value 对应token的值。
伪代码如下:
4. input
调用系统标准输入函数获得一个字符,并判断该字符类型,如果该字符为[0-9]的数字,则返回NUM类型的token,否则返回字符串类型的token。

5. intputline
与input类似,不同的是不仅要判断是否为NUM类型,还要判断是否为BOOL,list类型。返回相对应token。
6. add, sub, mul, div, mod, and, or, not。
以上运算实现方式均相同,都是对操作数进行相应的运算。最后返回NUM型的token结果。
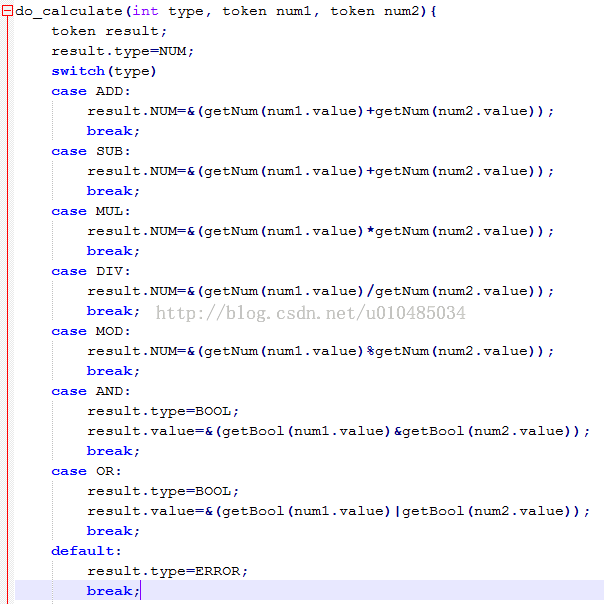
7. NOT操作
Not将value的值取反返回。

8. if <bool> <list1> <list2>
如果<bool>为真,则执行<list1>,否则执行<list2>
If操作首先对bool值进行判断,然后根据bool的值选择list1或者list2进行执行。

8. cat <list1> <list2>
列表操作,将<list1>和<list2>合并成一个列表。
这里需要使用列表分配函数从内存中分配能够容纳下list1和list2函数的空间,然后再将list1和list2的元素添加到该内存空间中。同时需要将list1原本的地址空间收回。

9. join <list> <value>
将<value>作为<list>的最后一个元素加入到<list>中。
同cat操作类似,需要再申请一块list内存空间,然后将value的值分配到给内存空间中。回收原本的内存空间。
9. first <list>
返回<list>的第一个元素。
从列表中获得第一个元素返回。

10. butfirst <list>
返回<list>除第一个元素外剩下的列表。
从内存中申请一块新的内存地址,然后将list中除了第一个token的其它token加入到该新的list中,返回该list。
11. 函数的定义
函数的定义在make的实现中已有说明,这里不再赘述。
12. 函数的调用
<functionName> <arglist>
<functionName>为make中定义的函数名,不需要双引号""
<arglist>是参数列表,<arglist>中的值和函数定义时的<list1>中名字进行一一对应绑定。
1)首先需要遍历函数列表查看是否已有该函数定义。
2)若是则进入下一步,建立一张临时变量表,将arglist中的局部变量放入该表中,当函数结束时删除该表。
3)按照参数列表执行列表中的语句。

13. 比较操作
比较操作包括大于 greater <基本数据类型> <基本数据类型> less<基本数据类型><基本数据类型> equal <基本数据类型><基本数据类型>在语法分析器进行语法分析时已经保证了两个操作数的类型相同,都为NUM型,或者都为STR型。对于STR的大小比较,与C语言中规则相同。
因此这里需要得到两个操作数的值,进行比较,然后返回BOOL类型的token即可。
Equal的伪代码如下,greater和less类似。

目标语言中并没有支持通过变量名进行比较,因此想要比较变量大小,要通过thing取得值。
到这里,我们的解释器已基本实现,当然在实现细节上可能会有很多问题,留待以后验证。