2012网易校园招聘笔试题
第一部分(必做):计算机科学基础
1、长为N的字符串中匹配长度为M的子串的算法复杂度是()
A. O(N) B. O(M+N) C. O(N+logM) D. O(M+logN)
答:B
分析:我查了查,O(M + N)。KMP能做到。
这里:http://blog.csdn.net/meixr/article/details/6456896
2、以下排序算法中,哪些是稳定的排序算法(多选)()
A.冒泡 B.插入 C.合并 D.希尔 E.快速排序
答:ABC
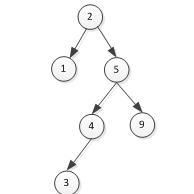
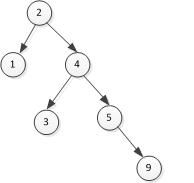
3、以下是一颗平衡二叉树,请画出插入键值3以后的这颗平衡二叉树。
分析:考察平衡二叉树的基本操作,插入3变成不平衡,需要节点5右旋一次,节点2左旋一次。。

4、给定两个整数集合A和B,每个集合都包含20亿个不同整数,请给出快速计算A∩B的算法,算法可使用外存,但是要求占用内存不能超过4GB。
答: 将集合A是的整数,根据n%10不同,分别装入10个文件中,依次命名为a0,a1……,a9。同理,将集合B分别装入10个文件中,依次命名为b0,b1,……,b9。那么A和B编号不同的文件中,一定不会有相同的整数。只需分另求出a0与b0中共有的元素、a1与b1中共有的元素……
利用bitmap,将bitmap清0,读入文件ai,依次处理每个数,即将bitmap的第(n/10)位置1。然后读入文件bi,依次处理每个数,即:若bitmap第(n/10)位为1,则这个数属于A∩B
5、请给出从N个无序的整数中计算机最小的K个整数的算法,并给出时间复杂度,其中K<<N,要求时间复杂度尽可能的低,不要求K个整数排序。
答:堆排序。将N个数中的前K个建立一个小顶堆。每读入一个新的整数,就把它插入到堆中,调整堆,但是每次调整都只调整前K个元素。从第K+1个位置开始的元素都忽略。时间为NlogK
6、假设一个有8个1024字页面的逻辑地址空间,映射到一个有32帧的物理内存结构中,逻辑地址有多少位?
答:13
逻辑地址 = 逻辑页号 + 页内偏移
逻辑页面数为8,因此逻辑页号长度为3,页面的大小为1024,因此页面偏移的长度为10.
如果求物理地址多少位,则是15
解:因为页面数为8=2^3,故需要3位二进制数表示。每页有1024个字节,1024=2^10,于是页内地址需要10位二进制数表示。32个物理块,需要5位二进制数表示(32=2^5)。
(1)页的逻辑地址由页号和页内地址组成,所以需要3+10=13位二进制数表示。
(2)页的物理地址由块号和页内地址的拼接,所以需要5+10=15位二进制数表示。
7、关于网络ISO各层协议的问题,把左右相对应。
| 应用层 |
|
网卡 |
| 表示层 |
|
路由IP |
| 会话层 |
|
交换机 |
| 网络层 |
|
TCP/UDP |
| 传输层 |
|
HTTP/DNS |
| 数据链路层 |
|
ASCII |
| 物理层 |
|
PRC,SQL |
答:貌似连线题?
(1)网卡的作用就是把数据进行串并转换(串连数据是比特流形式的,存在与本计算机内部,而计算机与计算机之间是通过帧形式的数据来进行数据传输的),MAC子层规定了如何在物理线路上传输的frame,LLC的作用是识别不同协议类型然后进行encapsulation(封包), 所以精确的说,网卡工作在数据链路层的MAC子层.
(2)路由IP属于网络层
(3)ISO的术语称之为中继(relay)系统。根据中继系统所在的层次,可以有以下五种中继系统:
1.物理层(即常说的第一层、层L1)中继系统,即转发器(repeater)。
2.数据链路层(即第二层,层L2),即网桥或桥接器(bridge)。
3.网络层(第三层,层L3)中继系统,即路由器(router)。
4.网桥和路由器的混合物桥路器(brouter)兼有网桥和路由器的功能。
5.在网络层以上的中继系统,即网关(gateway).
我们经常说到的以太网交换机实际是一个基于网桥技术的多端口第二层网络设备,即数据链路层
(4)TCP/UDP属于传输层
(5)HTTP/DNS属于应用层
(6)表示层位于OSI分层结构的第六层,它的主要作用之一是为异种机通信提供一种公共语言,以便能进行互操作。这种类型的服务之所以需要,是因为不同的计算机体系结构使用的数据表示法不同。例如,IBM主机使用EBCDIC编码,而大部分PC机使用的是ASCII码。在这种情况下,便需要会话层来完成这种转换。ASCII属于表示层
(7)PRC,SQL属于哪一层呢?
8、关于Bridge模式,Observer模式,Strategy模式,Mediator模式,以上哪种模式可以使得算法的使用者忽视算法的具体实现?
答:Bride模式
(1)Bridge模式 的用意是"将抽象化(Abstraction)与实现化(Implementation)脱耦,使得二者可以独立地变化"。
(2)Observer模式定义对象间的一对多的依赖关系,当一个对象的状态发生改变时, 所有依赖于它的对象都得到通知并被自动更新。
(3)Strategy模式 定义一系列算法,把他们封装起来,并使他们可以互相替换。
将策略加以封装为一个物件,而不是将策略写死在某个类中,如此一来,策略可以独立于客户端,随时增加变化、增加或减少策略,即使是修改每个策略的内容,也不会对客户端程式造成影响。
(4)Mediator模式 用一个中介对象来封装一系列关于对象交互行为。
9、数据库系统提供两种不同类型的语言,分别是自含式语言和嵌入式语言,来供数据库管理员及开发者管理,查询和更新。
10、数据库理论中取出右侧关系中所有与左侧关系的任一元组都不匹配的元组,用空值填充所有来自左侧关系的属性,再把产生的元组加到自然连接的结果上,这种连接运算称为?
答:左外连接
表的联结、运算符学习笔记
1.等值联结
两个表的相同列的值必须相等。
等值联结也称为 简单联结 或 内联结
2.非等值联结
非等值联结是包含非等号运算符的联结条件
3.外联结
通过外联结返回不直接匹配的记录。
外联结运算符只能出现在表达式的一侧,即缺少信息的那一侧。他将从一个表中返回在另一个表中没有直接匹配的行。
包含外联结的条件不能用IN 运算符,也不能通过OR运算符链接到另一个条件。
4.自联结
自己联结自己的一种联结形式
5.交叉联结:
返回两个表的交叉乘积 这与两个表之间的笛卡尔乘积是相同的 CROSS JOIN
6.自然联结:
NATURAL JOIN 子句是以两个表中具有相同名称的所有列为基础。
它选择两个表中那些在所有匹配的列中值相等的行。
如果列具有相同的名称 但是数据类型不同,就会返回一个错误。
7.USING子句
如果几个列具有相同的名称,但是数据类型不匹配,则可以使用USING 子句来修改NATURAL JOIN子句 以指定要用于等值联结的列。
在多个列匹配时,使用USING子句只匹配一个列。
在引用列中不要使用表名或别名
对于使用Using限制只用一个相同列来关联的,where条件当中出现的相同的列则必须限定为某一个表的列 否则因产生歧义而抛出错误
8.使用ON子句创建联结
自然联结的联结条件基本上是具有相同名称的所有列的等值联结。
要制定任意条件或指定要联结的列,可以使用ON子句。
联结条件与其他搜索条件分开。
9 INNER 与 OUTER 联结
在SQL:99标准中,只返回匹配行的两个表之间的联结叫做:内联结。
两个表之间的联结不但返回内联结结果而且返回左(或右)表不匹配行的结果。
两个表之间的联结不但返回内联结结果而且返回左联结和右联结不相匹配的结果,这样的联结就是完全外联结
关于左/右外联结的理解:
由于左右两个表完全匹配的情况称为 内联结,那么左外联结则可以理解为除了匹配的结果外,还将列出左表匹配以外的记录。
右外联结则是除了显示两表匹配的结果,还将显示右表除匹配结果以外的记录。
11. 下列关于索引创建的一般性原则,错误的是(D、E)
A. 在经常用作连接的列上创建索引
B. 在经常用作排序的列上创建索引
C. 在经常搜索的列上及where子句的列上创建索引
D. 在定义为text,image和bit数据类型的列上创建索引
E. 在根据范围搜索的列上创建索引
一般来说,不应该创建索引的的这些列具有下列特点:第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
12、关于数据库事务,什么是事务?简述事务的几个基本特性。并由低到高写出事务的几个隔离级别。
分析:数据库事务ACID特性:原子性、一致性、隔离性、持久性。。
隔离级别:未授权读取、授权读取、可重复读取、序列化
第二部分:C/C++必做题
1.哈希表的实现方式有哪几种,实现一种 hash_insert
答:直接寻址法、平方取中法、数字分析法、折叠法、随机数法、除留余数法。。
2.写一个程序,打印出以下的序列。
(a),(b),(c),(d),(e)........(z)
(a,b),(a,c),(a,d),(a,e)......(a,z),(b,c),(b,d).....(b,z),(c,d).....(y,z)
(a,b,c),(a,b,d)....(a,b,z),(a,c,d)....(x,y,z)
....
(a,b,c,d,.....x,y,z)
#include<iostream>
#include<vector>
#include<string>
#include<iterator>
using namespace std;
using std::iterator;
void CombineRescure(vector<char> &str,vector<char>::iterator pStr,vector<char> &result,int count);
void Combine(vector<char> str,int n)
{
if(str.empty())
return;
vector<char> result;
CombineRescure(str,str.begin(),result,n);
}
void CombineRescure(vector<char> &str,vector<char>::iterator pStr,vector<char> &result,int count)
{
if(count==0)
{
cout<<"(";
//copy(result.begin(),result.end(),ostream_iterator<char,char>(cout,","));
for(int i=0;i<result.size();i++)
{
cout<<result[i];
if(i!=result.size()-1)
cout<<",";
}
cout<<"),";
return;
}
if(pStr!=str.end())
{
result.push_back(*pStr);
CombineRescure(str,pStr+1,result,count-1);
result.erase(result.end()-1);
CombineRescure(str,pStr+1,result,count);
}
}
int main()
{
vector<char> str;
for(int i=0;i<4;i++)
{
str.push_back('a'+i);
}
for(int i=1;i<=str.size();i++)
{
Combine(str,i);
cout<<endl;
}
return 0;
}
3.给出示例代码,如何限制一个类只在堆上分配和栈上分配
之前转载的那篇《C++内存管理》最后一章节——《对象内存大会战》有详细地描述。我转录如下:
禁止产生堆对象:
那么怎样禁止产生堆对象了?我们已经知道,产生堆对象的唯一方法是使用new操作,如果我们禁止使用new不就行了么。再进一步,new操作执行时会调用operator new,而operator new是可以重载的。方法有了,就是使new operator为private,为了对称,最好将operator delete也重载为private。现在,你也许又有疑问了,难道创建栈对象不需要调用new吗?是的,不需要,因为创建栈对象不需要搜索内存,而是直接调整堆栈指针,将对象压栈,而operator new的主要任务是搜索合适的堆内存,为堆对象分配空间,
禁止产生栈对象:
前面已经提到了,创建栈对象时会移动栈顶指针以“挪出”适当大小的空间,然后在这个空间上直接调用对应的构造函数以形成一个栈对象,而当函数返回时,会调用其析构函数释放这个对象,然后再调整栈顶指针收回那块栈内存。在这个过程中是不需要operator new/delete操作的,所以将operator new/delete设置为private不能达到目的。当然从上面的叙述中,你也许已经想到了:将构造函数或析构函数设为私有的,这样系统就不能调用构造/析构函数了,当然就不能在栈中生成对象了。
4.大概是下面这个样子吧,但愿我没把函数调用的地方记错。。。
#include <iostream> using namespace std; class A { public: virtual void Fun(int number = 10) { std::cout << "A::Fun with number " << number<<endl; } }; class B: public A { public: virtual void Fun(int number = 20) { std::cout << "B::Fun with number " << number<<endl; } }; int main() { B b; A &a = b; a.Fun(); system("pause"); return 0; //虚函数动态绑定:B,缺省实参是编译时确定的。。。为10 }
打印结果:B::Fun with number 10
#include <iostream> using namespace std; class A { public: A(int j):i(j) { fun1(); } ~A() { } virtual void fun2() { i++; } void fun1() { i *= 10; } int i; }; class B:public A { public: B(int j):A(j) { fun2(); } ~B() { } void fun2() { i += 2; } void fun1() { i *= 100; } }; int main() { A* p = new B(1); cout<<p->i<<endl; delete p; system("pause"); };
打印结果:12
5改错如下:
#include <iostream> using namespace std; class A { public: A(); ~A(); int i = 0; static int j = 0; const int k = 0; const static char *p = "Hello world"; static void fun(); }; A::A() { } A::~A() { } static void fun() { }
10.3是C++各种成员变量的初始化问题。
主要是staitc,const,static const的问题;这里有详细地解答
http://blog.csdn.net/yjkwf/article/details/6067267
在C++中,static静态成员变量不能在类的内部初始化。在类的内部只是声明,定义必须在类定义体的外部,通常在类的实现文件中初始化,如:double Account::Rate=2.25;static关键字只能用于类定义体内部的声明中,定义时不能标示为static
在C++中,const成员变量也不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。
const数据成员 只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类的声明中初始化const数据成员,因为类的对象没被创建时,编译器不知道const数据成员的值是什么。
const数据成员的初始化只能在类的构造函数的初始化列表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现,或者static cosnt。
class Test { public: Test():a(0){} enum {size1=100,size2=200}; private: const int a;//只能在构造函数初始化列表中初始化 static int b;//在类的实现文件中定义并初始化 const static int c;//与 static const int c;相同。 }; int Test::b=0;//static成员变量不能在构造函数初始化列表中初始化,因为它不属于某个对象。 cosnt int Test::c=0;//注意:给静态成员变量赋值时,不需要加static修饰符。但要加cosnt