SQL基础语法笔记教程整理
- 一关系型数据库和SQL
- 1 SQL语言主要有3个主要的组成部分
- 2 主键和外键
- 3 数据类型
- 3 空值
- 二简单增删改查
- 1 查列名有空格的情况
- 查询顺序SQL执行顺序2
- 2 增
- 3 改
- 4 删
- 1 查列名有空格的情况
- 三别名
- 1 计算字段
- 2 直接量
- 3 算数运算
- 4 别名
- 四使用函数
- 1 字符函数
- LEFTRIGHT
- LTRIMRTRIM
- SUBSTRING
- 2 日期时间函数
- GETDATE
- DATEPART
- DATEDIFF
- 3 数值函数
- ROUND
- RAND
- PI
- 4 转换函数
- CAST函数
- ISNULL函数很有用
- 1 字符函数
- 五排序函数
- 1 添加排序
- 2 降序
- 3 根据多列
- 4 根据计算字段
- 5 排序补充内容
- 六基于列的逻辑-CASE
- 1 IF-THEN-ELSE逻辑
- 2 CASE-简单格式
- 3 CASE-查询格式
- 七基于行的逻辑
- 1 应用查询条件
- 2 限制行-TOP
- 3 TOP和ORDER BY结合
- 八布尔逻辑
- 1 OR
- 2 使用圆括号
- 3 NOT操作符
- 4 BETWEEN操作符
- 5 IN操作符
- 9 布尔逻辑-IS NULL
- 九模糊匹配
- 1 LIKE和搭配
- 2 通配符
- 3 按照读音匹配
- 十汇总数据
- 1消除重复
- 2 聚合函数
- COUNT函数可以有3中不同方式使用它
- 3 分组数据-GROUP BY
- 4 基于聚合查询条件-HAVING
- 十一组合表
- 1 内连接来组合表-Inner Join
- 2 外连接
- 左连接LEFT JOIN
- 3 自连接
- 4 创建视图
- 视图的优点
- 十二补充
- 1 子查询
- 2 索引
- 参考
最近从图书馆借了本介绍SQL的书,打算复习一下基本语法,记录一下笔记,整理一下思路,以备日后复习之用。
PS:本文适用SQL Server2008语法。
一、关系型数据库和SQL
实际上准确的讲,SQL是一门语言,而不是一个数据库。
什么是SQL呢?简而言之,SQL就是维护和使用关系型数据库中的的数据的一种标准的计算机语言。
1.1 SQL语言主要有3个主要的组成部分。
- DML(Data Manipulation Language)数据操纵语言。这个模块可以让我们检索、修改、增加、删除数据库中的数据。
- DDL(Data Definition Language)数据定义语言。是的我们能够创建和修改数据库本身。如:DDL提供
ALTER语句,他让我们可以修改数据库中表的设计。 - DCL(Data Control Language)数据控制语言,用于维护数据库的安全。
在SQL术语中,记录(record)和字段(field)实际上就称为行(row)和列(column)。
1.2 主键和外键
主键之所以有必要:
- 首先使你唯一标识表中单独的一行。主键确保了唯一性。
- 可以很容易的将一个表和另一个表关联。
- 主键一般就会自动默认创建索引,提高了查询速度。
外键就是说A表中的某个字段,同时是B中的主键,那么这个字段就是A表中的外键。希望A表中的这个外键的值必须是B中已经存在的值。
1.3 数据类型
一般来讲,有3中重要的数据类型:
- 数字(Numeric)
- 字符(Character)
- 以及日期/时间(Date/Time)
bit是数字型,它只允许两个值,0和1。
字符类型区别1:
| 类型 | 长度 | 说明 |
|---|---|---|
char |
固定长度 | |
nchar |
固定长度 | 处理unicode数据类型(所有的字符使用两个字节表示) |
varchar |
可变长度 | 效率没char高 灵活 |
nvarchar |
可变长度 | 处理unicode数据类型(所有的字符使用两个字节表示) |
- 1字节=8位
- bit就是位,也叫比特位,是计算机表示数据最小的单位。
- byte就是字节,1byte=8bit,1byte就是1B;
- 一个字符=2字节;
1.3 空值
空值不等于空格或空白。使用NULL表示空值。
二、简单增删改查
2.1 查(列名有空格的情况)
SELECT [ last name] FROM Customers用方括号将有空格的列名括起来。
PS: MySql中用重音符`(~)按键。Oracle用双引号。
查询顺序,SQL执行顺序2:
Select -1>选择列,-2>distinct,-3>top 1>…From 表 2>…Where 条件 3>…Group by 列 4>…Having 筛选条件 6>…Order by 列2.2 增
INSERT INTO tablename (columnlist) VALUES (RowValues1) (RowValues2) (repeat any number of times)2.3 改
UPDATE table SET column1=expression1,column2=expression2(repeat any number of times) WHERE condition2.4 删
DELETE FROM table WHERE condition删除前可以验证一下:
SELECT COUNT(*) FROM table WHERE condition如果想要删除所有的行,可以:
DELETE FROM table或者
TRUNCATE TABLE tableTRUNCATE TABLE优势在于速度更快,但是不提供记录事务的结果。
另外一个不同点是,TRUNCATE TABLE重新设置了用于自增型的列的当前值,DELETE不会。
三、别名
关键字:AS
3.1 计算字段
使用计算字段可以做如下的事情:
- 选择特定的单词或者数值
- 对单个或者多个列进行计算
- 把列和直接量组合在一起。
3.2 直接量
这个直接量和表中的数据没有任何关系,就是为了说明所用,下面这种类型的表达式就叫做直接量(literal value)。
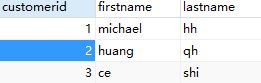
SELECT '直接量' AS `类型`,firstname,lastname FROM `customers` ;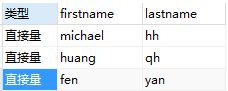
如图,结果中直接量就在一列中了。
3.3 算数运算
例子1:
SELECT num*price AS total FROM orders例子2:
SELECT firstname+' '+lastname AS 'fullname' FROM users在MySql中连接要是用CONCAT函数:
SELECT OrderID,FirstName,LastName,
CONCAT(FirstName,' ',LastName) AS 'fullname'
FROM orders3.4 别名
1)列的别名
SELECT firstname AS fn FROM customers2) 表的别名
SELECT firstname FROM customers AS cu说明:
- 列的别名是为了显示用的,别名会作为查询结果的表头,不能在WHERE中使用列的别名,会出错!!!
- 表的别名确实是为了方便操作用的,可以在WHERE中使用列的别名进行!
四、使用函数
函数要有一组圆括号跟在关键字后边,圆括号告诉我们,这是一个函数!
4.1 字符函数
LEFT&RIGHT
LEFT(CharacterValue,NumberOfCharacters)
含义:选择CharacterValue字段的左边NumberOfCharacters几个字符。
ps:RIGHT是右边几个字符。
LTRIM&RTRIM
LTRIM(CharacterValue)
可以删除左边开始的空格。RTRIM作用类似。
SUBSTRING
SUBSTRING(CharacterValue,StartPositon,NumberOfCharacters)
含义:选择从开始位置(包括),N个长度的字符。
SELECT SUBSTRING('thewhitegoat',4,5) AS 'The Answer'返回:white
4.2 日期/时间函数
GETDATE
SELECT GETDATE()返回当前日期和时间。
PS:在MySql中,等价函数是NOW,在Oracle中是CURRENT_DATE。
DATEPART
能够分析具体的日期,并且返回诸如该日期是该月中的第几天,或者该年份中的第几周等信息。
DATEPART(datepart,DateValue)datepart可以是许多不同的值,如下都是有效值:
- year
- quarter
- month
- dayofyear
- day
- week
- weekday
- hour
- minute
- second
DATEDIFF
可以让我们得到任意两个日期之间相差的天数(或周数、月数等)。
DATEDIFF(datepart1,startdate1,startdate2)| DATEDIFF Function Expression | Resulting Value |
|---|---|
| DATEDIFF(day,’7/8/2009’,’8/14/2009’) | 37 |
| DATEDIFF(week,’7/8/2009’,’8/14/2009’) | 5 |
| DATEDIFF(month,’7/8/2009’,’8/14/2009’) | 1 |
| DATEDIFF(year,’7/8/2009’,’8/14/2009’) | 0 |
PS:MySql中,DATEDIFF函数只允许我们计算两个日期之间的天数,如果想要得到一个正数,结束的日期通常要作为第一个参数:
DATEDIFF(enddate,startdate)Oracle中没有等价函数
4.3 数值函数
ROUND
允许我们四舍五入。
ROUND(numericvalue,decimalpalaces)RAND
用来产生随机数
RAND([seed])没有参数时,它会返回0-1之间的一个随机数。
SELECT RAND() AS 'Random Value'可选参数seed有的情况下,每次将返回相同的值。这让我想起了Python中的Random包。看来很多时候,一些东西是共通的啊。
PI
PI()函数
如果想要对它保留两位小数,可以通过复合函数进行:
SELECT ROUND(PI(),2)将会返回:3.14
4.4 转换函数
CAST函数
允许我们把数据从一种类型转换成另一种类型。
CAST(expression AS DateType)例子:
SELECT '2009-04-11' AS 'Original Date', CAST('2009--04-11' AS DATETIME) AS 'Converted Date'ISNULL函数,很有用
可以把NULL值转换成一个有意义的值。
SELECT Description, ISNULL(Color,'Unknown') AS 'Color' FROM Products五、排序函数
5.1 添加排序
SELECT columnlist FROM tablelist ORDER BY columnlist默认是升序,ASC,因此,上面等价于:
SELECT columnlist FROM tablelist ORDER BY columnlist ASC5.2 降序
使用DESC关键字:
SELECT columnlist FROM tablelist ORDER BY columnlist DESC5.3 根据多列
SELECT FirstName, LastName FROM Customers ORDER BY LastName, FirstName注意:列的顺序很重要,首先按照LastName排序,然后按照FirstName排序。
5.4 根据计算字段
SELECT LastName+','+FirstName AS 'Name' FROM Customers ORDER BY Name因此,从这儿可以知道,列别名不可以用在WHERE中,但可以用在ORDER BY中。
例子
SELECT FirstName,LastName FROM Customers ORDER BY LastName+FirstName AS 'Name'5.5 排序补充内容
当数据升序时,出现顺序是如下:
NULL->数字->字符
注意:此时,该列中的数字其实是按照字符来算的,因此,升序时,23也是排在5之前的。
六、基于列的逻辑-CASE
6.1 IF-THEN-ELSE逻辑
包含列和CASE表达式的SELECT语句,大概如下:
SELECT column1, column2, CaseExpression FROM table6.2 CASE-简单格式
SELECT CASE ColumnOrExpression WHEN value1 THEN result1 WHEN value2 THEN result2 (repeat WHEN-THEN any number of times) [ELSE DefaultResult] ENDCASE表达式对于把不好理解的值转换成有意义的描述是很有用的。
SELECT CASE CategoryCode WHEN 'F' THEN 'Fruit' WHEN 'V' THEN 'Vegetable' ELSE 'other' END AS 'Category', ProductDescription As 'Description' FROM Products6.3 CASE-查询格式
SELECT CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 (repeat WHEN-THEN any number of times) [ELSE DefaultResult] END这种格式允许在关键字WHEN后边放置较为复杂的条件表达式。
相关问题:
- StackOverFlow-SQL Server: CASE WHEN OR THEN ELSE END => the OR is not supported
七、基于行的逻辑
7.1 应用查询条件
终于派到WHERE出场了,注意写法顺序,再写一遍:
Select -1>选择列,-2>distinct,-3>top 1>…From 表 2>…Where 条件 3>…Group by 列 4>…Having 筛选条件 6>…Order by 列7.2 限制行-TOP
SELECT TOP Number Columnlist FROM table7.3 TOP和ORDER BY结合
关键字TOP的另一个用途是,把它和ORDER BY子句结合起来,基于特定分类,得到带有最大值的一定数量的行。
假设你想看到Shakespeare所著的销量最多的书。
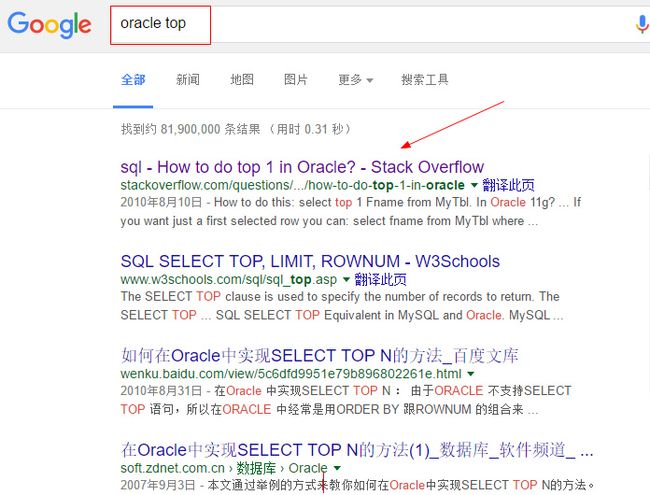
SELECT TOP1 Title AS 'Book Title', CurrentMonthSales AS 'Quantuty Sold' FROM Books WHERE Author='Shakespeare' ORDER BY CurrentMonthSales DESCps: 学会利用google搜索,例如,我想要知道oracle中类似top作用的关键字是什么,可以:
八、布尔逻辑
关键字:AND/OR/NOT/BETWEEN/IN/IS/NULL
8.1 OR
OR子句意味着,如果确定任意条件为真,那么就该选中该行。
SELECT userid,name,phone FROM users WHERE age<18 OR age>608.2 使用圆括号
SELECT CustomerName, Sate, QuantityPurchased FROM Orders WHERE State ='IL' OR State='CA' AND QuantityPurchased>8本来想要的结果是对来自IL或者CA的客户,同时,只看数量大于8的订单。但是上面执行的结果不是这样的,因为,SQL总是会先处理AND操作符!!!然后才会处理OR操作符。所以,上述语句中,先看到AND并执行如下的条件
State= 'CA'
AND QuantityPurchased>8因此,要用括号来规定顺序:
SELECT CustomerName, Sate, QuantityPurchased FROM Orders WHERE (State ='IL' OR State='CA') AND QuantityPurchased>88.3 NOT操作符
NOT操作符表示对后边的内容否定或者取反。
SELECT CustomerName,State FROM Orders WHERE NOT (State='IL' OR Sate='NY')这个其实可以用AND改写的!!!
NOT操作符在逻辑上不是必须的。
8.4 BETWEEN操作符
SELECT CustomerName, Sate, QuantityPurchased FROM Orders WHERE QuantityPurchased BETWEEN 8 AND 108.5 IN操作符
假设你想看到IL或者NY的行:
SELECT * FROM Orders WHERE State='IL' OR State='CA'可以改写成:
SELECT * FROM Orders WHERE State IN ('IL','CA')8.9 布尔逻辑-IS NULL
为了将某字段NULL值的行或0的行包括进来:
SELECT * FROM Products WHERE weight=0 OR weight IS NULL或者
SELECT * FROM Products WHERE ISNULL(weight,0)=0九、模糊匹配
9.1 LIKE和%搭配
%通配符可以表示任意的字符,它可以表示0个,1个,任意多个字符。
9.2 通配符
除了%以外,还有下划线(_)、方括号起来的characterlist,以及用方括号括起来的脱字符号(^)加上characterlist。
- 下划线表示一个字符
- [characterlist]表示括号中字符的任意一个
- [^characterlist]表示不能是括号中字符的任意一个
例子:
SELECT FirstName, LastName FROM Actors WHERE FirstName LIKE '[CM]ARY'检索以C或者M开头并以ARY结尾的所有行。
9.3 按照读音匹配
SOUNDEX和DIFFERENCE
十、汇总数据
10.1消除重复
使用DISTINCT
SELECT DISTINCE name,age
FROM users如果age不同,即使name相同,那么这一行就不会被删除重复。
10.2 聚合函数
COUNT\SUM\AVG\MIN\MAX,他们提供了对分组数据进行计数、求和、取平均值、取最小值和最大值等方法。
SELECT AVG(Grade) AS 'Average Quiz Score' MIN(Grade) AS 'Minimum Quiz Score' FROM Grades WHERE GradeType='Quiz'COUNT函数可以有3中不同方式使用它。
1.COUNT函数可以用来返回所有选中行的数目,而不管任何特定列的值。
例如:下面语句返回GradeType为’HomeWork’的所有行的数目:
SELECT COUNT(*) AS 'Count of Homework Rows' FROM Grades WHERE GradeType='HomeWork'这种*方式,会计数所有行的个数,即使其中有NULL。
2.第二种方式指定具体的列
SELECT COUNT(Grades) AS 'Count of Homework Rows' FROM Grades WHERE GradeType='HomeWork'第一种方式返回3,这一种方式返回2,为什么???因为,这种方式要满足Grades这一列有值,NULL值的行不会计数。
3.使用关键字DISTINCT。
SELECT COUNT(DISTINCT FeeType) AS 'Number of Fee Types' FROM Fees这条语句计数了FeeType列唯一值的个数。
10.3 分组数据-GROUP BY
SELECT GradeType AS 'Grade Type', AVG(Grade)AS 'Average Grade' FROM Grades GROUP BY GradeType ORDER BY GradeType感觉像EXCEL中的分类汇总功能。
如果想把Grade为NULL值的当做0,那么可以用:
SELECT GradeType AS 'Grade Type', AVG(ISNULL(Grade,0))AS 'Average Grade' FROM Grades GROUP BY GradeType ORDER BY GradeType- GROUP BY子句中的列的顺序是没有意义的;
- ORDER BY子句中的列的顺序是有意义的。
10.4 基于聚合查询条件-HAVING
当针对带GROUP BY的一条SELECT语句应用任何查询条件时,人们必须要问查询条件是应用于单独的行还是整个组。
实际上,WHERE子句是单独的执行查询条件。SQL提供了一个名为HAVING的关键字,它允许对组级别使用查询条件。
例子:
查看选修了类型为选修“A”,平均成绩在70分以上的学生姓名,平均成绩。
SELECT Name, AVG(ISNULL(Grades,0)) AS 'Average Grades' FROM Grades WHERE GradeType='A' GROUP BY Name HAVING AVG(ISNULL(Grades,0))>70 ORDER BY Name修要修类型为A,那么,这是这对行的查询,因此这里要用WHERE。
但是,还要筛选平均成绩,那么,这是一个平均值,建立在聚合函数上的,并不是单独的行,这就需要用到关键字HAVING。需要先将Student分组,然后把查询结果应用到基于全组的一个聚合统计上。
WHERE只保证我们选择了GradeType是A的行,HAVING保证平均成绩至少70分以上。
注意:如果想要在结果中添加GradeType的值,如果直接在SELECT后边添加这个列,将会出错。这是因为,所有列都必须要么出现在GROUP BY中,要么包含在一个聚合函数中。
SELECT Name, GradeType, AVG(ISNULL(Grades,0)) AS 'Average Grades' FROM Grades WHERE GradeType='A' GROUP BY Name,GradeType HAVING AVG(ISNULL(Grades,0))>70 ORDER BY Name十一、组合表
11.1 内连接来组合表-Inner Join
通过书中的描述,我感觉内连接更像是用来将主键表、外键表连接起来的工具。
例如:
A表:
| userid | name | age |
|---|---|---|
| 1 | michael | 26 |
| 2 | hhh | 25 |
| 3 | xiang | 20 |
B表:
| orderid | userid | num | price |
|---|---|---|---|
| 1 | 1 | 2 | 3 |
| 2 | 2 | 6 | 6 |
| 3 | 1 | 5 | 5 |
如上表格,那么要连接这两个表格,查询订单1的客户姓名,年龄,订单号:
方式一:
SELECT name,age,orderid FROM A,B WHERE A.userid=B.userid AND orderid=1方式二,使用现在的内连接实现:
SELECT name,age,orderid FROM A INNER JOIN B ON A.userid=B.userid AND orderid=1ON关键字指定两个表如何准确的连接。
内连接中表的顺序:FROM 子句指定了A表,INNER JOIN 子句指定B表,我们调换A,B顺序,所得到的结果相同的!只是显示列的顺序可能会不同而已。
不建议使用方式一的格式。关键字INNER JOIN ON的优点在于显示地表示了连接的逻辑,那是它们唯一的用途。WEHERE的含义不够明显。因为它是条件的意思啊,不是连接的!
11.2 外连接
外连接分为左连接(LEFT OUTER JOIN)、右连接(RIGHT OUTER JOIN)、全连接(FULL OUTER JOIN)。
OUTER是可以省略的。
左连接(LEFT JOIN)
SELECT name,age,orderid FROM A LEFT JOIN B ON A.userid=B.userid AND orderid=1外连接的强大之处在于,主表中的数据必然都会保留,从表中列没有值的情况,用NULL补充。
LEFT JOIN 左边的表为主表,右边的表为从表。
11.3 自连接
自连接必然用到表的别名。
SELECT A.name,B.name as ManagerName FROM worker as A LEFT JOIN worker as B ON A.managerid=B.id11.4 创建视图
CREATE VIEW ViewName AS SelectStatement [WITH CHECK OPTION]视图中不能包含ORDER BY子句。
[WITH CHECK OPTION]表示对视图进行UPDATE,INSERT,DELETE操作时任然保证了视图定义时的条件表达式。
删除视图:
DROP VIEW ViewName修改视图:
ALTER VIEW ViewName AS SelectStatement视图的优点
- 简化用户的操作
- 使用户以多角度看待同一数据
- 对重构数据库提供了一定程度的逻辑独立性
- 对机密数据提供安全保护
十二、补充
12.1 子查询
可以用3种主要的方式来指定子查询,总结如下:
- 当子查询是tablelist的一部分时,它指定了一个数据源。
- 当子查询是condition的一部分时,它成为查询条件的一部分。
- 当子查询是columnlist的一部分时,它创建了一个单个的计算的列。
12.2 索引
索引是一种物理结构,可以为数据库表中任意的列添加索引。
索引的目的是,当SQL语句中包含该列的是偶,可以加速数据的检索。
索引的缺点是,在数据库中,索引需要更多的存储硬盘。另一个负面因素是,索引通常会降低相关的列数据更新速度。这是因为,任何时候插入或者修改一行记录时,索引都必须重新计算该列中的值的正确的排列顺序。
可以对任意的列进行索引,但是只能指定一个列作为主键。指定一个列作为主键意味着两件事情:首先这个列成为了索引,其次保证这列包含唯一的值。
CREATE INDEX Index2
ON MyTable (ColumnFour)删除一个索引:
DROP INDX Index2 ON MyTable参考:
- SQL总结(一)基本查询
- SQL Server 常用高级语法笔记
- 史上最全的SQL Server复习笔记一
- varchar和Nvarchar区别 ↩
- SQL总结(一)基本查询 ↩