mysql 查询理解
1.单表主键查询:
语句:
select * fromgmvcsbase.base_file where id='29830957'
执行计划:
![]()
Id为base_file表的主键,
Select_type为simple表示简单的select,没有union和子查询
Table为base_file表示输出的行所用的表
Type为const表示表最多有一个匹配行,const用于比较primary key 或者unique索引。
Possible_keys提示使用哪些索引会在该表中找到行
Key表示实际使用的索引,实际使用的是主键索引
Key_len表示使用的索引部分的长度
Ref显示使用哪个列或常数与key一起从表中选择行
Rows表示执行查询的行数,数值越大越不好,说明没有用好索引
Extra包含MySQL解决查询的详细信息
执行图:

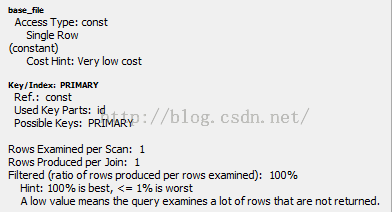
查询base_file表
Access Type访问类型Single Row单行
Cost Hint代价估算 Very low cost很低的代价
Key/Index:PRIMARY使用主键索引
Used Key Parts使用了主键索引的哪部分
Filtered过滤比率,100%过滤最好,小于1%最差
过滤比率低则表明查询检查了很多行数据,但是很多都不满足条件。
执行结果:
![]()
结论:
以上是MySQL单表主键查询的执行计划。结论自己理解吧。
2.单表唯一索引查询
语句:
select * from gmvcsbase.base_file where sid='c465202be7664ff5a11663f7fd1bff4b'
执行计划:
执行图:
执行结果:
结论:
单表唯一索引查询和单表主键查询在效率上几乎一样。由于唯一索引和主键索引是一对一的关系,索引找到唯一索引值即可直接找到主键值。
3.单表非唯一索引查询
语句:
select * from gmvcsbase.base_file where police_id='00003771' limit 10
执行计划:
Type为ref,如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),或者联接只使用键的最左边的前缀,则使用ref。
Possible_keys有很多,可以理解为任何包含police_id的索引都是possible_keys
实际使用的是index_user_id。
Rows有2999个,说明满足police_id=’00003771’的数据大概有2999条吧。
Extra使用索引条件
执行图:
Non-Unique Key Lookup非唯一索引查询
代价估算:Low if number of matching rows is small,higher as the numberof rows increases。
执行结果:
结论:
非唯一索引查询比主键索引查询和唯一索引查询要差一些。
思考不加limit情况会怎样,limit 2900,20会如何,order by start_capture_time会如何。
4.单表无索引查询
语句:
select * from gmvcsbase.base_file where device_serial='1615CF85CA08' limit 20
执行计划:
Type为ALL表示需要进行全表扫描,不使用索引,通常查询效率很差。
Rows为29971746,说明全表数据量大概这么多行吧。
Extra为Using where用于限制哪一个行匹配,在这里的匹配条件是:
device_serial='1615CF85CA08'
执行图:
29.97M rows就是全表扫描2997万行数据
代价估算:Very High,No usable indexes,must search every row。
This could also mean thesearch range is so broad that the index would be useless.
也有可能是查询范围太广,索引会没多大用处。
Key/Index空,没有使用
Attached Condition附加条件,device_serial='1615CF85CA08',貌似using where就是这个意思了,扫表的时候,判断这个条件是否满足。
Filtered为100%说明attachedCondition在这里不算过滤条件,因为这个确实没办法算嘛。
执行结果:
0秒不代表查询快,那是因为加了limit 20这个条件,如果不加,卡死。
结论:
全表扫描应该避免。
5.单表非唯一索引范围查询
语句:
select * from gmvcsbase.base_file
where start_capture_time>='2015-11-01' andstart_capture_time<'2015-11-02'
limit 20
执行计划:
Type为range 给定范围内的检索,使用一个索引来检查行。
Key为index_start_capture_time
Rows713248就是start_cpauture_time在2015-11-01和2015-11-02之间有这么多条数据。
Extra使用索引条件
执行图:
71万数据满足索引条件
range范围查询
代价估算:中等,部分索引扫描
执行结果:
结论:
用索引进行范围查询总比不用索引进行范围查询好吧。
思考,当查询start_capture_time大时间范围时,还会使用index_start_capture_time这个索引么。
6.单表非唯一索引范围+附加条件+order by查询
语句:
select fi.id,fi.sid,fi.name file_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi
where
fi.start_capture_time>= '2015-10-01 00:00:00' and fi.start_capture_time <= '2015-11-2309:25:39'
and fi.status=0
and(fi.workstation_type=1 or fi.workstation_type=0 orfi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
order by fi.start_capture_time desc limit0,20;
执行计划:
Extra使用索引条件查询,使用where查询。
执行图:
由图可知,此种查询首先会使用索引Index_start_capture_time进行范围查询,满足
fi.start_capture_time >= '2015-10-0100:00:00' and fi.start_capture_time <= '2015-11-23 09:25:39'
条件的是索引搜索范围。
每次按照时间顺序拿X条满足上面索引条件的记录,然后找到这些记录,判断这些记录是否满足where条件:
and fi.status=0
and (fi.workstation_type=1 orfi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
如果全部满足,则此条记录返回。
由于index_start_capture_time本身是有序的,而且index_start_capture_time本身就是索引条件,此处order by start_capture_time就不需要再排序了。此处需要加深理解。
执行结果:
结论:
单独的使用索引范围并且有limit查询时是很快的,但如果有where附加条件,那么问题就不一样了,比如说where附加条件实际情况不存在的情况,索引范围查询也会遍历满足索引条件的所有记录,然后才知道满足where附加条件的数据根本不存在。下一条给出示例。
7.单表非唯一索引范围+附加条件(附加条件不存在于实际数据中)+order by查询
语句:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
and fi.type='0' order by fi.start_capture_time desc limit 0,20;
执行计划:
和上例一模一样
执行图:
和上例基本一样,只是attachedcondition附加条件中多了一条and fi.type='0'媒体类型为其他。
执行结果:
查询耗时2.403秒,查询出结果为空即没有行满足查询条件。
结论:
要尽量避免此类情况的出现,如果有这类查询,需要做特殊处理吧。
8.单表非唯一索引范围+附加条件+order by(不按照索引条件)查询
语句:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
order by fi.capture_time desc limit 0,20;
执行计划:
Extra多了个Using filesort就是要排序的意思
执行图:
Using Filesort为True,意思是没法索引自然排序,必须要把数据全部查出来,然后再排序。
执行结果:
这个耗时跟上面的不存在条件查询差不多,因为两者都进行了全索引范围查询,不然的话不能保证排序是正确的
结论:
排序要慎用,尤其当查询的数据量大的时候,如果排序不能直接按照索引自然排,则查询会查所有,然后再排序和limit。
9.单表LIKE索引查询
语句1:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi
where
police_id like'00003771%'
limit 0,20;
语句2:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi
where
police_id like '%00003771%'
limit 0,20;
执行计划1:
使用索引index_user_id
执行计划2:
全表扫描
执行图1:
满足索引条件的有3000行数据,部分索引扫描
执行图2:
全表扫描,无法使用索引
执行结果1:
执行结果2:
结论:
貌似执行结果都蛮快,实际上那是因为加了limit条件而已。如果,limit条件改动,两者查询效率会有十分大的区别。
LIKE 可以使用索引前缀来加快查询速度,但是是有条件的,就是LIKE条件不能以%开头,必须是具体的数据。
10.单表聚合(count、sum、avg)查询
语句1:
select count(*) from gmvcsbase.base_file fiwhere
start_capture_time>='2015-11-01' andstart_capture_time<'2015-11-02'
start_capture_time有加索引
语句2:
select count(*) from gmvcsbase.base_file fiforce index(start_capture_time)where
capture_time>='2015-11-01' andcapture_time<'2015-11-02'
capture_time未加索引,全表扫描
语句3:
Select count(*) from gmvcsbase.base_file fiwhere
capture_time>='2015-11-01' andcapture_time<'2015-11-02'
执行计划1:
索引扫描
执行计划2:
全表扫描
执行计划3:
使用了索引index_user_createtime(police_id,capture_time)
执行图1:
因为有个start_capture_time加索引,所以count的时候就可以直接算索引条数即可,而且索引是有序的,这样就更快了。
执行图2:
全表扫描,需要扫描3000W条记录
代价估算非常高
执行图3:
此次查询使用了Fullindex Scan全索引扫描
执行结果1:
0.28秒
执行结果2:
24.242秒
执行结果3:
14.4秒
结论:
在进行聚合查询时,如果聚合查询的条件能有效使用合适的索引,则能很好地提高查询效率。
3000W条记录进行全表扫描耗时24.242秒,如此计算,每秒大概能扫描比对100W条记录,这是因为全表扫描是顺序读取数据而非随机读取数据,如果是随机读取,则耗时不可想象。
语句3走的是联合索引,而且police_id在前,start_capture_time在后,因此需要进行全索引扫描,效率上比直接索引查询慢,跟全表扫描的效率其实是同一个量级。
单表查询总结:
至此,单表查询就介绍到这里了,基本概念应该也比较清晰了,下面开始介绍多表联合查询。
11.主表left join外表,多对一或一对一关系,主键或唯一索引作匹配条件
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d %H:%i:%s')import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left joingmvcsbase.base_department dep ON fi.police_dep = dep.code
left joingmvcsbase.base_user user ON fi.police_id = user.police_id
where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
order by fi.start_capture_time desc limit0,20;
执行计划:
执行图:
Nested loop表示嵌套循环
Unique Key Lookup表示唯一索引查找,因为dep.code和user.police_id都是各自表中的主键,所以查询时能根据索引直接找到需要的行记录,而且匹配行数只有一行,速度很快。
执行流程如上图从上至下依次执行。
首先是base_file表,别名fi,使用索引index_start_capture_time和附加条件查询出需要的数据。
然后嵌套循环这些查询出的数据,根据police_code去查找base_department表(别名dep)中相应的部门名称name。
然后嵌套循环这些数据,根据police_id去查找base_user表(别名user)中的警员名称name。
最后将查询出的数据进行排序,由于是按照start_capture_time进行排序,而且在第一步的时候使用了index_start_capture_time,所以在第一步时已经是有序的数据了。
执行结果:
耗时0.016秒
结论:
这种查询的特点是base_file表为主表,需要根据base_file表中的某一字段(在外表中为主键或者唯一索引)去外表中获取对应行的信息。查询效率很高。
12.主表left join外表,多对一或一对一关系,主键或唯一索引作匹配条件,外表有额外条件
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left joingmvcswxs.tmis_filelabel label on fi.sid=label.WJBH
left join gmvcsbase.base_user user ONfi.police_id = user.police_id
left join gmvcsbase.base_department dep ONfi.police_dep = dep.code
where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
and fi.is_unusual=0 and fi.is_mark =1
and label.BZDM='0301'and label.is_delete=0
order by fi.start_capture_time desc limit0,20;
Base_file表和标注表是1对1的关系。Fi.sid是base_file表的唯一索引,label.WJBH是标注表的唯一索引。where条件中加入了filelabel表中的条件,BZDM标注类别,is_delete=0标注信息未删除。
执行计划:
首先查base_file表,然后嵌套循环查出警员名称,然后嵌套循环查出部门名称,然后嵌套循环按照and label.BZDM='0301' and label.is_delete=0过滤数据,将满足条件的前20条数据返回。
执行图:
跟执行计划流程基本吻合。
关键点看此图,这里有了附加条件,通过附加条件进行数据过滤,只有满足条件的数据才是我们需要的数据。
显然这里的order by也是自然就排好了的。
执行结果:
耗时0.265秒
结论:
很简单的理解,从base_file表找出了20条数据(按照start_capture_time已排序),遍历这20条数据,根据当前条数据的fi.police_id去user表查找user.name,相当于如下语句:
Select user.name from user whereuser.police_id=fi.police_id
将查找到的user.name加入该条数据中。
。。。。。。dep表同理。
关于label表也类似,相当于如下语句:
Select 1 from label where label.WJBH =fi.sid andlabel.BZDM='0301' and label.is_delete=0
此处fi.sid有具体的值,是常数,如果返回1,则表示这条记录满足条件,如果没返回1,则不满足条件,此条记录被过滤掉。
注意:假如label.BZDM=’某实际不存在的值’,结果应该能够理解。
假如order bycapture_time,结果也应该能够理解。无法自然排序的limit是在全部数据查出之后。
13.主表left join外表,多对多或一对多关系,外表附加条件
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left joingmvcswxs.tmis_match gl on fi.sid=gl.WJBH
left join gmvcsbase.base_user user ONfi.police_id = user.police_id
left join gmvcsbase.base_department dep ONfi.police_dep = dep.code
where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and fi.is_relation =1
and (fi.workstation_type=1 orfi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
and gl.SJLX='PECC'and gl.is_delete=0
group by fi.id
order by fi.start_capture_time desc limit0,20
这里由于是1对多关系,1条base_file表记录在tmis_match表中有对应多条记录。
根据left join规则,联表后,需要group by fi.id才能去除fi表重复的记录。
执行计划:
执行图:
注意gl表的流程,Non-Unique Key Lookup非唯一索引检索,因为是1对多关系,gl表中的WJBH不能成为唯一索引。
注意group的下面有个tmp table,说明gl表联表查询后形成了临时表,然后对这个临时表进行了group by fi.id操作,最后,将group by好的数据再按照start_capture_time进行排序。
注意,Low ifnumber of matching rows is small,higher as the number of rows increases。
使用了临时表,没有排序。
最后order by时,需要排序。
执行结果:
耗时2.262秒,好像还行,可以接受,但这是因为fi表中已经过滤了大部分数据,如果fi表中没法过滤大部分数据,那查询效率不敢想象。
结论:
一对多,多对多是不好优化的,最好在起始表就过滤大量数据,不然后续的临时表会非常大,对临时表进行分组,然后排序也会消耗大量资源(内存,时间)。
14.尝试使用exists进行13的优化
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left join gmvcsbase.base_user user ONfi.police_id = user.police_id
left join gmvcsbase.base_department dep ONfi.police_dep = dep.code
where fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and fi.is_relation =1
and (fi.workstation_type=1 orfi.workstation_type=0 or fi.workstation_type=101)
and fi.police_dep in('440100-00010','440101-00064','440101-00331','440101-00332')
and exists(select 1 fromgmvcswxs.tmis_match gl where gl.SJLX='PECC' and gl.is_delete=0 andfi.sid=gl.WJBH)
order by fi.start_capture_time desc limit0,20
想想为何这里没有groupby
执行计划:
DEPENDENT SUBQUERY独立子查询
执行图:
这张执行图就比较复杂了。
起始fi表查询中多了一个附加条件attached condition。
这里是需要去做判断,比如说我查到一条fi表记录,根据这条记录的sid去tmis_match表查找该sid是否满足上面条件,如果满足条件则此记录保留,如果不满足则丢弃。
针对gl表的子查询如上图所示,其实就是一条语句
select 1 from gmvcswxs.tmis_match gl wheregl.SJLX='PECC' and gl.is_delete=0 and gl.WJBH=fi.sid
这里的fi.sid是常数。由于走了索引,WJBH有加索引,所以子查询效率足够快。
返回1就是exists。可以推知,无需group by也无需order by也没有临时表。
执行结果:
0.156秒较上面的查询快了至少一个数量级。
结论:
一对多,多对多查询如果只查主表数据,不涉及到外表,则可以用exists来避免临时表,groupby和排序。
1.单表主键查询:
语句:
select * fromgmvcsbase.base_file where id='29830957'
执行计划:
Id为base_file表的主键,
Select_type为simple表示简单的select,没有union和子查询
Table为base_file表示输出的行所用的表
Type为const表示表最多有一个匹配行,const用于比较primary key 或者unique索引。
Possible_keys提示使用哪些索引会在该表中找到行
Key表示实际使用的索引,实际使用的是主键索引
Key_len表示使用的索引部分的长度
Ref显示使用哪个列或常数与key一起从表中选择行
Rows表示执行查询的行数,数值越大越不好,说明没有用好索引
Extra包含MySQL解决查询的详细信息
执行图:
查询base_file表
Access Type访问类型Single Row单行
Cost Hint代价估算 Very low cost很低的代价
Key/Index:PRIMARY使用主键索引
Used Key Parts使用了主键索引的哪部分
Filtered过滤比率,100%过滤最好,小于1%最差
过滤比率低则表明查询检查了很多行数据,但是很多都不满足条件。
执行结果:
结论:
以上是MySQL单表主键查询的执行计划。结论自己理解吧。
2.单表唯一索引查询
语句:
select * from gmvcsbase.base_file where sid='c465202be7664ff5a11663f7fd1bff4b'
执行计划:
执行图:
执行结果:
结论:
单表唯一索引查询和单表主键查询在效率上几乎一样。由于唯一索引和主键索引是一对一的关系,索引找到唯一索引值即可直接找到主键值。
3.单表非唯一索引查询
语句:
select * from gmvcsbase.base_file where police_id='00003771' limit 10
执行计划:
Type为ref,如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),或者联接只使用键的最左边的前缀,则使用ref。
Possible_keys有很多,可以理解为任何包含police_id的索引都是possible_keys
实际使用的是index_user_id。
Rows有2999个,说明满足police_id=’00003771’的数据大概有2999条吧。
Extra使用索引条件
执行图:
Non-Unique Key Lookup非唯一索引查询
代价估算:Low if number of matching rows is small,higher as the numberof rows increases。
执行结果:
结论:
非唯一索引查询比主键索引查询和唯一索引查询要差一些。
思考不加limit情况会怎样,limit 2900,20会如何,order by start_capture_time会如何。
4.单表无索引查询
语句:
select * from gmvcsbase.base_file where device_serial='1615CF85CA08' limit 20
执行计划:
Type为ALL表示需要进行全表扫描,不使用索引,通常查询效率很差。
Rows为29971746,说明全表数据量大概这么多行吧。
Extra为Using where用于限制哪一个行匹配,在这里的匹配条件是:
device_serial='1615CF85CA08'
执行图:
29.97M rows就是全表扫描2997万行数据
代价估算:Very High,No usable indexes,must search every row。
This could also mean thesearch range is so broad that the index would be useless.
也有可能是查询范围太广,索引会没多大用处。
Key/Index空,没有使用
Attached Condition附加条件,device_serial='1615CF85CA08',貌似using where就是这个意思了,扫表的时候,判断这个条件是否满足。
Filtered为100%说明attachedCondition在这里不算过滤条件,因为这个确实没办法算嘛。
执行结果:
0秒不代表查询快,那是因为加了limit 20这个条件,如果不加,卡死。
结论:
全表扫描应该避免。
5.单表非唯一索引范围查询
语句:
select * from gmvcsbase.base_file
where start_capture_time>='2015-11-01' andstart_capture_time<'2015-11-02'
limit 20
执行计划:
Type为range 给定范围内的检索,使用一个索引来检查行。
Key为index_start_capture_time
Rows713248就是start_cpauture_time在2015-11-01和2015-11-02之间有这么多条数据。
Extra使用索引条件
执行图:
71万数据满足索引条件
range范围查询
代价估算:中等,部分索引扫描
执行结果:
结论:
用索引进行范围查询总比不用索引进行范围查询好吧。
思考,当查询start_capture_time大时间范围时,还会使用index_start_capture_time这个索引么。
6.单表非唯一索引范围+附加条件+order by查询
语句:
select fi.id,fi.sid,fi.name file_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi
where
fi.start_capture_time>= '2015-10-01 00:00:00' and fi.start_capture_time <= '2015-11-2309:25:39'
and fi.status=0
and(fi.workstation_type=1 or fi.workstation_type=0 orfi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
order by fi.start_capture_time desc limit0,20;
执行计划:
Extra使用索引条件查询,使用where查询。
执行图:
由图可知,此种查询首先会使用索引Index_start_capture_time进行范围查询,满足
fi.start_capture_time >= '2015-10-0100:00:00' and fi.start_capture_time <= '2015-11-23 09:25:39'
条件的是索引搜索范围。
每次按照时间顺序拿X条满足上面索引条件的记录,然后找到这些记录,判断这些记录是否满足where条件:
and fi.status=0
and (fi.workstation_type=1 orfi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
如果全部满足,则此条记录返回。
由于index_start_capture_time本身是有序的,而且index_start_capture_time本身就是索引条件,此处order by start_capture_time就不需要再排序了。此处需要加深理解。
执行结果:
结论:
单独的使用索引范围并且有limit查询时是很快的,但如果有where附加条件,那么问题就不一样了,比如说where附加条件实际情况不存在的情况,索引范围查询也会遍历满足索引条件的所有记录,然后才知道满足where附加条件的数据根本不存在。下一条给出示例。
7.单表非唯一索引范围+附加条件(附加条件不存在于实际数据中)+order by查询
语句:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
and fi.type='0' order by fi.start_capture_time desc limit 0,20;
执行计划:
和上例一模一样
执行图:
和上例基本一样,只是attachedcondition附加条件中多了一条and fi.type='0'媒体类型为其他。
执行结果:
查询耗时2.403秒,查询出结果为空即没有行满足查询条件。
结论:
要尽量避免此类情况的出现,如果有这类查询,需要做特殊处理吧。
8.单表非唯一索引范围+附加条件+order by(不按照索引条件)查询
语句:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
order by fi.capture_time desc limit 0,20;
执行计划:
Extra多了个Using filesort就是要排序的意思
执行图:
Using Filesort为True,意思是没法索引自然排序,必须要把数据全部查出来,然后再排序。
执行结果:
这个耗时跟上面的不存在条件查询差不多,因为两者都进行了全索引范围查询,不然的话不能保证排序是正确的
结论:
排序要慎用,尤其当查询的数据量大的时候,如果排序不能直接按照索引自然排,则查询会查所有,然后再排序和limit。
9.单表LIKE索引查询
语句1:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi
where
police_id like'00003771%'
limit 0,20;
语句2:
select fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time
from gmvcsbase.base_file fi
where
police_id like '%00003771%'
limit 0,20;
执行计划1:
使用索引index_user_id
执行计划2:
全表扫描
执行图1:
满足索引条件的有3000行数据,部分索引扫描
执行图2:
全表扫描,无法使用索引
执行结果1:
执行结果2:
结论:
貌似执行结果都蛮快,实际上那是因为加了limit条件而已。如果,limit条件改动,两者查询效率会有十分大的区别。
LIKE 可以使用索引前缀来加快查询速度,但是是有条件的,就是LIKE条件不能以%开头,必须是具体的数据。
10.单表聚合(count、sum、avg)查询
语句1:
select count(*) from gmvcsbase.base_file fiwhere
start_capture_time>='2015-11-01' andstart_capture_time<'2015-11-02'
start_capture_time有加索引
语句2:
select count(*) from gmvcsbase.base_file fiforce index(start_capture_time)where
capture_time>='2015-11-01' andcapture_time<'2015-11-02'
capture_time未加索引,全表扫描
语句3:
Select count(*) from gmvcsbase.base_file fiwhere
capture_time>='2015-11-01' andcapture_time<'2015-11-02'
执行计划1:
索引扫描
执行计划2:
全表扫描
执行计划3:
使用了索引index_user_createtime(police_id,capture_time)
执行图1:
因为有个start_capture_time加索引,所以count的时候就可以直接算索引条数即可,而且索引是有序的,这样就更快了。
执行图2:
全表扫描,需要扫描3000W条记录
代价估算非常高
执行图3:
此次查询使用了Fullindex Scan全索引扫描
执行结果1:
0.28秒
执行结果2:
24.242秒
执行结果3:
14.4秒
结论:
在进行聚合查询时,如果聚合查询的条件能有效使用合适的索引,则能很好地提高查询效率。
3000W条记录进行全表扫描耗时24.242秒,如此计算,每秒大概能扫描比对100W条记录,这是因为全表扫描是顺序读取数据而非随机读取数据,如果是随机读取,则耗时不可想象。
语句3走的是联合索引,而且police_id在前,start_capture_time在后,因此需要进行全索引扫描,效率上比直接索引查询慢,跟全表扫描的效率其实是同一个量级。
单表查询总结:
至此,单表查询就介绍到这里了,基本概念应该也比较清晰了,下面开始介绍多表联合查询。
11.主表left join外表,多对一或一对一关系,主键或唯一索引作匹配条件
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d %H:%i:%s')import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left joingmvcsbase.base_department dep ON fi.police_dep = dep.code
left joingmvcsbase.base_user user ON fi.police_id = user.police_id
where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
order by fi.start_capture_time desc limit0,20;
执行计划:
执行图:
Nested loop表示嵌套循环
Unique Key Lookup表示唯一索引查找,因为dep.code和user.police_id都是各自表中的主键,所以查询时能根据索引直接找到需要的行记录,而且匹配行数只有一行,速度很快。
执行流程如上图从上至下依次执行。
首先是base_file表,别名fi,使用索引index_start_capture_time和附加条件查询出需要的数据。
然后嵌套循环这些查询出的数据,根据police_code去查找base_department表(别名dep)中相应的部门名称name。
然后嵌套循环这些数据,根据police_id去查找base_user表(别名user)中的警员名称name。
最后将查询出的数据进行排序,由于是按照start_capture_time进行排序,而且在第一步的时候使用了index_start_capture_time,所以在第一步时已经是有序的数据了。
执行结果:
耗时0.016秒
结论:
这种查询的特点是base_file表为主表,需要根据base_file表中的某一字段(在外表中为主键或者唯一索引)去外表中获取对应行的信息。查询效率很高。
12.主表left join外表,多对一或一对一关系,主键或唯一索引作匹配条件,外表有额外条件
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left joingmvcswxs.tmis_filelabel label on fi.sid=label.WJBH
left join gmvcsbase.base_user user ONfi.police_id = user.police_id
left join gmvcsbase.base_department dep ONfi.police_dep = dep.code
where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and (fi.workstation_type=1or fi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
and fi.is_unusual=0 and fi.is_mark =1
and label.BZDM='0301'and label.is_delete=0
order by fi.start_capture_time desc limit0,20;
Base_file表和标注表是1对1的关系。Fi.sid是base_file表的唯一索引,label.WJBH是标注表的唯一索引。where条件中加入了filelabel表中的条件,BZDM标注类别,is_delete=0标注信息未删除。
执行计划:
首先查base_file表,然后嵌套循环查出警员名称,然后嵌套循环查出部门名称,然后嵌套循环按照and label.BZDM='0301' and label.is_delete=0过滤数据,将满足条件的前20条数据返回。
执行图:
跟执行计划流程基本吻合。
关键点看此图,这里有了附加条件,通过附加条件进行数据过滤,只有满足条件的数据才是我们需要的数据。
显然这里的order by也是自然就排好了的。
执行结果:
耗时0.265秒
结论:
很简单的理解,从base_file表找出了20条数据(按照start_capture_time已排序),遍历这20条数据,根据当前条数据的fi.police_id去user表查找user.name,相当于如下语句:
Select user.name from user whereuser.police_id=fi.police_id
将查找到的user.name加入该条数据中。
。。。。。。dep表同理。
关于label表也类似,相当于如下语句:
Select 1 from label where label.WJBH =fi.sid andlabel.BZDM='0301' and label.is_delete=0
此处fi.sid有具体的值,是常数,如果返回1,则表示这条记录满足条件,如果没返回1,则不满足条件,此条记录被过滤掉。
注意:假如label.BZDM=’某实际不存在的值’,结果应该能够理解。
假如order bycapture_time,结果也应该能够理解。无法自然排序的limit是在全部数据查出之后。
13.主表left join外表,多对多或一对多关系,外表附加条件
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left joingmvcswxs.tmis_match gl on fi.sid=gl.WJBH
left join gmvcsbase.base_user user ONfi.police_id = user.police_id
left join gmvcsbase.base_department dep ONfi.police_dep = dep.code
where
fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and fi.is_relation =1
and (fi.workstation_type=1 orfi.workstation_type=0 or fi.workstation_type=101)
and fi.police_depin('440100-00010','440101-00064','440101-00331','440101-00332')
and gl.SJLX='PECC'and gl.is_delete=0
group by fi.id
order by fi.start_capture_time desc limit0,20
这里由于是1对多关系,1条base_file表记录在tmis_match表中有对应多条记录。
根据left join规则,联表后,需要group by fi.id才能去除fi表重复的记录。
执行计划:
执行图:
注意gl表的流程,Non-Unique Key Lookup非唯一索引检索,因为是1对多关系,gl表中的WJBH不能成为唯一索引。
注意group的下面有个tmp table,说明gl表联表查询后形成了临时表,然后对这个临时表进行了group by fi.id操作,最后,将group by好的数据再按照start_capture_time进行排序。
注意,Low ifnumber of matching rows is small,higher as the number of rows increases。
使用了临时表,没有排序。
最后order by时,需要排序。
执行结果:
耗时2.262秒,好像还行,可以接受,但这是因为fi表中已经过滤了大部分数据,如果fi表中没法过滤大部分数据,那查询效率不敢想象。
结论:
一对多,多对多是不好优化的,最好在起始表就过滤大量数据,不然后续的临时表会非常大,对临时表进行分组,然后排序也会消耗大量资源(内存,时间)。
14.尝试使用exists进行13的优化
语句:
select
fi.id,fi.sid,fi.namefile_name,fi.police_id,fi.police_dep,fi.type,fi.quality,fi.duration,
DATE_FORMAT(fi.start_capture_time,'%Y-%m-%d%H:%i:%s') capture_time,
DATE_FORMAT(fi.import_time,'%Y-%m-%d%H:%i:%s') import_time,
user.name user_name,
dep.name dep_name
from gmvcsbase.base_file fi
left join gmvcsbase.base_user user ONfi.police_id = user.police_id
left join gmvcsbase.base_department dep ONfi.police_dep = dep.code
where fi.start_capture_time>='2015-10-0100:00:00' and fi.start_capture_time<'2015-10-02'
and fi.status=0 and fi.is_relation =1
and (fi.workstation_type=1 orfi.workstation_type=0 or fi.workstation_type=101)
and fi.police_dep in('440100-00010','440101-00064','440101-00331','440101-00332')
and exists(select 1 fromgmvcswxs.tmis_match gl where gl.SJLX='PECC' and gl.is_delete=0 andfi.sid=gl.WJBH)
order by fi.start_capture_time desc limit0,20
想想为何这里没有groupby
执行计划:
DEPENDENT SUBQUERY独立子查询
执行图:
这张执行图就比较复杂了。
起始fi表查询中多了一个附加条件attached condition。
这里是需要去做判断,比如说我查到一条fi表记录,根据这条记录的sid去tmis_match表查找该sid是否满足上面条件,如果满足条件则此记录保留,如果不满足则丢弃。
针对gl表的子查询如上图所示,其实就是一条语句
select 1 from gmvcswxs.tmis_match gl wheregl.SJLX='PECC' and gl.is_delete=0 and gl.WJBH=fi.sid
这里的fi.sid是常数。由于走了索引,WJBH有加索引,所以子查询效率足够快。
返回1就是exists。可以推知,无需group by也无需order by也没有临时表。
执行结果:
0.156秒较上面的查询快了至少一个数量级。
结论:
一对多,多对多查询如果只查主表数据,不涉及到外表,则可以用exists来避免临时表,groupby和排序。