大数据作协框架Oozie
大数据作协框架Oozie
标签(空格分隔): 大数据
- 大数据作协框架Oozie
- 一概述
- 二Oozie的安装和部署
- 三wordcount案例实现map reduce运行
- 四hive案例实现shell
- 五coordinatetime trigger
- 六coodernate实例
- 七总结
一,概述
大数据协作框架是一个桐城,就是Hadoop2生态系统中几个辅助的Hadoop2.x框架。主要如下:
1,数据转换工具Sqoop
2,文件搜集框架Flume
3,任务调度框架Oozie
4,大数据Web工具Hue任务调度框架
1,Linux Crontab
2,Azkaban –https://azkaban.github.io/
3,Ozie –http://oozie.apache.org/ 功能强大 难度大
工作流调度
协作调度(定时,数据可用性)
binder(批量)
4,Zeus –https://github.com/michael8335/zeus2Oozie概述
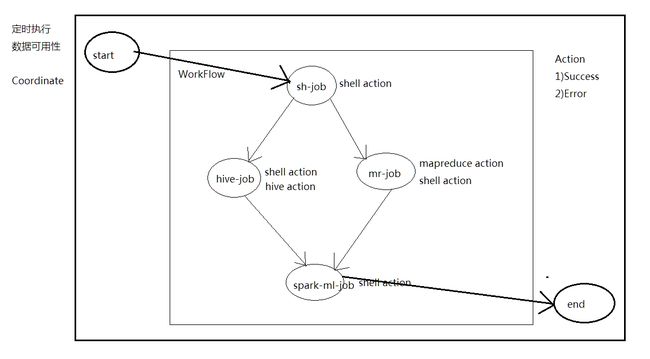
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions.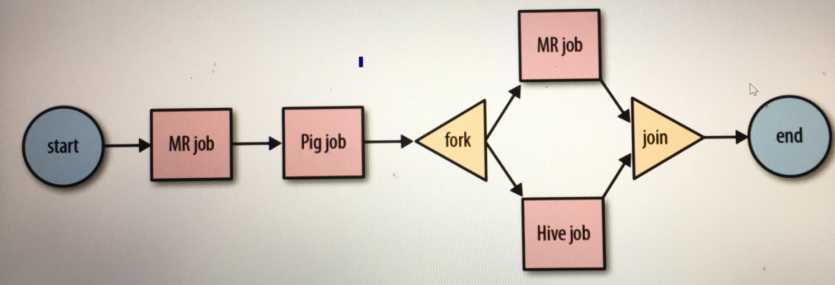
Oozie Coordinator jobs are recurrent Oozie Workflow jobs triggered by time (frequency) and data availabilty.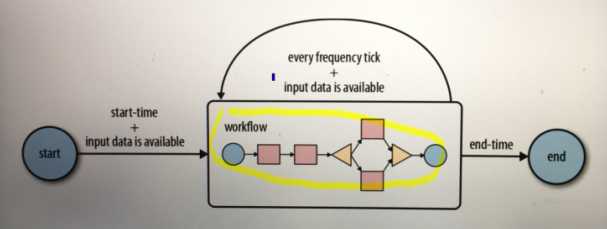
Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box (such as Java map-reduce, Streaming map-reduce, Pig, Hive, Sqoop and Distcp) as well as system specific jobs (such as Java programs and shell scripts).Oozie is a scalable, reliable and extensible system.1,一个基于工作流引擎的开源框架,是由Cloudera公司贡献给Apache的,它能够提供对Hadoop Mapreduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。
2,Oozie工作流定义,同Jboss jBPM提供的jPDL一样,提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。对于工作流系统,一般会有很多不同功能的节点,比如分支,并发,汇合等等。
3,Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision,fork,join等;而动作节点包括Haoop map-reduce hadoop文件系统,Pig,SSH,HTTP,eMail和Oozie子流程
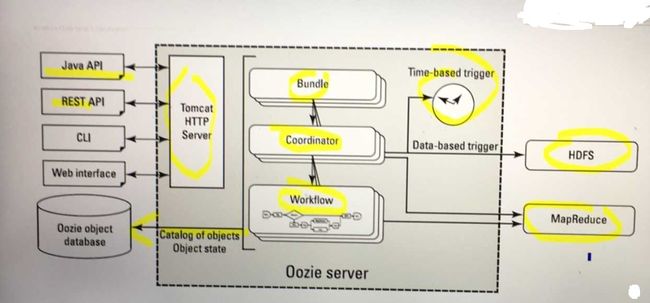
- Oozie Server Architecture
Oozie Server Components
二,Oozie的安装和部署
- 下载安装包
http://archive.cloudera.com/cdh5/cdh/5/oozie-4.0.0-cdh5.3.6.tar.gz - 解压安装包
tar -zxf oozie-4.0.0-cdh5.3.6.tar.gz -C /opt/app- It is recommended to use a Oozie Unix user for the Oozie server.
sudo adduser oozie
sudo passwd oozie- Configure the Hadoop cluster with proxyuser for the Oozie process.
The following two properties are required in Hadoop core-site.xml:
<property>
<name>hadoop.proxyuser.hadoop001.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop001.groups</name>
<value>*</value>
</property>Hadoop集群安装在A账户下,OOZIE安装在某节点的B账户下,该账户属于C用户组。那么代理设置表示如下含义:A账户在该节点拥有代替C用户组提交任务的权限。Hadoop集群安装在A账户下,OOZIE安装在某节点的B账户下,该账户属于C用户组。那么代理设置表示如下含义:A账户在该节点拥有代替C用户组提交任务的权限。
- Expand the Oozie hadooplibs tar.gz in the same location Oozie distribution tar.gz was expanded
tar -zxf oozie-hadooplibs-4.0.0-cdh5.3.6.tar.gz -C ../- Create a libext/ directory in the directory where Oozie was expanded.
mkdir libext- If using a version of Hadoop bundled in Oozie hadooplibs/ , copy the corresponding Hadoop JARs from hadooplibs/ to the libext/ directory. If using a different version of Hadoop, copy the required Hadoop JARs from such version in the libext/ directory.
cp -r ./* /opt/app/oozie-4.0.0-cdh5.3.6/libext/- If using the ExtJS library copy the ZIP file to the libext/ directory.
cp ext-2.2.zip /opt/app/oozie-4.0.0-cdh5.3.6/libext- Run the oozie-setup.sh script to configure Oozie with all the components added to the libext/ directory.
$ bin/oozie-setup.sh prepare-war- Create the Oozie DB using the ‘ooziedb.sh’ command line tool:
$ bin/ooziedb.sh create -sqlfile oozie.sql -run- A “sharelib create -fs fs_default_name [-locallib sharelib]” command is available when running oozie-setup.sh for uploading new sharelib into hdfs where the first argument is the default fs name and the second argument is the Oozie sharelib to install, it can be a tarball or the expanded version of it. If the second argument is omitted, the Oozie sharelib tarball from the Oozie installation directory will be used. Upgrade command is deprecated, one should use create command to create new version of sharelib. Sharelib files are copied to new lib_ directory. At start, server picks the sharelib from latest time-stamp directory. While starting server also purge sharelib directory which is older than sharelib retention days (defined as oozie.service.ShareLibService.temp.sharelib.retention.days and 7 days is default).
$ bin/oozie-setup.sh sharelib create \
-fs hdfs://xingyunfei001.com.cn \
-locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gzStart Oozie as a daemon process run:
$ bin/oozied.sh start查看
http://xingyunfei001.com.cn:11000/oozie/三,运行测试example
- Oozie examples are bundled within the Oozie distribution in the oozie-examples.tar.gz file.
tar -zxf oozie-examples.tar.gz- The examples/ directory must be copied to the user HOME directory in HDFS:
[hadoop001@xingyunfei001 hadoop_2.5.0_cdh]$ bin/hdfs dfs -put /opt/app/oozie-4.0.0-cdh5.3.6/examples- 修改job.properties文件
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
nameNode=hdfs://xingyunfei001.com.cn:8020
jobTracker=xingyunfei001.com.cn:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/hadoop001/${examplesRoot}/apps/map-reduce/workflow.xml
outputDir=map-reduce- 修改oozie-site.xml文件
<property>
<name>oozie.service.HadoopAccessorService.hadoop.configurations</name>
<value>*=/opt/app/hadoop_2.5.0_cdh/etc/hadoop</value>
<description>
Comma separated AUTHORITY=HADOOP_CONF_DIR, where AUTHORITY is the HOST:PORT of
the Hadoop service (JobTracker, HDFS). The wildcard '*' configuration is
used when there is no exact match for an authority. The HADOOP_CONF_DIR contains
the relevant Hadoop *-site.xml files. If the path is relative is looked within
the Oozie configuration directory; though the path can be absolute (i.e. to point
to Hadoop client conf/ directories in the local filesystem.
</description>
</property>- 重新启动oozie
$ bin/oozied.sh stop
$ bin/oozied.sh start- run an example application:
$ bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/map-reduce/job.properties -run–总结
1,job.properties:属性指向workflow.xml所在的HDFS的位置(local)
2,workflow:(hdfs)
*start
*action
–mapreduce/shell
–ok
–error
*kill
*end
3,lib:依赖的jar包(hdfs)
三,wordcount案例实现(map reduce运行)
1,创建相应的工程
mkdir wordcount
cd wordcount
mkdir lib
cp hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar /opt/app/oozie-4.0.0-cdh5.3.6/examples/apps/wordcount/lib/
cp job.properties /opt/app/oozie-4.0.0-cdh5.3.6/examples/apps/wordcount/
cp workflow.xml /opt/app/oozie-4.0.0-cdh5.3.6/examples/apps/wordcount/2,在hdfs上创建输入输出目录
bin/hdfs dfs -mkdir ooziedir
bin/hdfs dfs -mkdir ooziedir/input
bin/hdfs dfs -mkdir ooziedir/output
bin/hdfs dfs -put /opt/app/hadoop_2.5.0_cdh/etc/hadoop/core-site.xml ooziedir/input/
bin/yarn jar /opt/app/hadoop_2.5.0_cdh/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /user/hadoop001/ooziedir/input/core-site.xml /user/hadoop001/ooziedir/output/out001
3,编辑job.properties文件
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
nameNode=hdfs://xingyunfei001.com.cn:8020
jobTracker=xingyunfei001.com.cn:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/hadoop001/${examplesRoot}/apps/map-reduce/workflow.xml
inputFile=/user/hadoop001/ooziedir/input/core-site.xml
outputDir=/user/hadoop001/ooziedir/output/outwordcount
4,编辑workflow.xml文件
<!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to you under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. -->
<workflow-app xmlns="uri:oozie:workflow:0.2" name="map-wordcount-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/${outputDir}"/>
</prepare>
<configuration>
<!--hadoop new api-->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!--queue-->
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!--1,input-->
<property>
<name>mapred.input.dir</name>
<value>${inputFile}</value>
</property>
<!--2,mapper-->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<property>
<name>mapreduce.map.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.map.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!--3,reducer-->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!--3,output-->
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
5,将本地工程上传到hdfs
bin/hdfs dfs -put /opt/app/oozie-4.0.0-cdh5.3.6/examples/apps/wordcount /user/hadoop001/examples/apps/6,启动oozie调度
[hadoop001@xingyunfei001 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/wordcount/job.properties -run
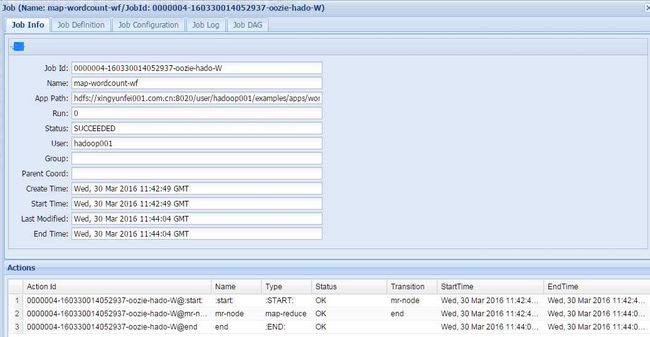
bin/hdfs dfs -text /user/hadoop001/ooziedir/output/outwordcount/part*
总结:
1,nodename的命名长度不要超过20个字符 [a-zA-Z][-_a-zA-Z0-9]
四,hive案例实现(shell)
1,本地创建工作空间
cp hive shellhive2,创建shell脚本(hive-select.sh)
#!/bin/bash
/opt/app/hive_0.13.1_cdh/bin/hive -e "select id,url,ip from db_track.track_log limit 10;"
3,修改job.properties文件
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<workflow-app xmlns='uri:oozie:workflow:0.4' name='shell-select-wf'>
<start to='shell-node' />
<action name='shell-node'>
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>${shellFile}#${EXEC}</file>
</shell>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Script failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name='end' />
</workflow-app>
4,将工作目录传到hdfs指定的目录上
bin/hdfs dfs -put /opt/app/oozie-4.0.0-cdh5.3.6/examples/apps/shellhive /user/hadoop001/examples/apps/5,执行oozie调度
bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/shellhive/job.properties -run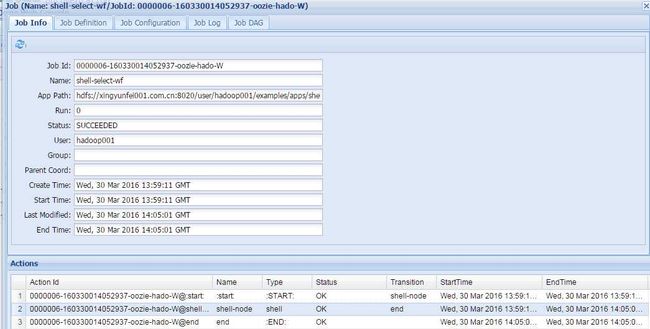
五,coordinate—time trigger
- 三个要素
1,开始时间
2,频率
3,结束时间 - 时区
1,CST:中国标准时间
2,UTC(协调世界时)==GMT(格林威治时间)
3,修改系统时区和oozie自带的时区:
--系统时区
[root@xingyunfei001 hadoop001]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
[root@xingyunfei001 hadoop001]# date -R
--Wed, 30 Mar 2016 22:36:08 +0800--修改oozie时区
--修改oozie-site.xml配置文件
<property>
<name>oozie.processing.timezone</name>
<value>GMT+0800</value>
</property>
--重新启动oozie生效- 修改js以保持web console显示的时区和oozie设置的时区一致
六,coodernate实例
1,创建工作环境
[hadoop001@xingyunfei001 apps]$ mkdir cron-test
[hadoop001@xingyunfei001 cron]$ cp coordinator.xml ../cron-test
[hadoop001@xingyunfei001 shellhive]$ cp hive-select.sh ../cron-test
[hadoop001@xingyunfei001 shellhive]$ cp job.properties ../cron-test
[hadoop001@xingyunfei001 shellhive]$ cp workflow.xml ../cron-test2,修改coordinate.xml配置文件
<coordinator-app name="cron-coord" frequency="${coord:minutes(12)}" start="${start}" end="${end}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
<property>
<name>EXEC</name>
<value>${EXEC}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>3,修改job.properties文件
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
nameNode=hdfs://bigdata-senior01.ibeifeng.com:8020
jobTracker=bigdata-senior01.ibeifeng.com:8032
queueName=default
examplesRoot=user/hadoop001/examples/apps
oozie.coord.application.path=${nameNode}/${examplesRoot}/cron-test
start=2016-03-31T00:40+0800
end=2016-03-31T00:59+0800
workflowAppUri=${nameNode}/${examplesRoot}/cron-test
EXEC=hive-select.sh
4,修改workflow.xml文件
<workflow-app xmlns="uri:oozie:workflow:0.4" name="emp-select-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapreduce.job.queuename</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>${nameNode}/${examplesRoot}/cron-test/${EXEC}#${EXEC}</file>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>5,上传本地工程到hdfs上面
bin/hdfs dfs -put /opt/app/oozie-4.0.0-cdh5.3.6/examples/apps/cron-test /user/hadoop001/examples/apps/6,执行定时计划
$ bin/oozie job -oozie http://localhost:11000/oozie -config examples/apps/cron-test/job.properties -run
七,总结
当前系统时间已经超过计划开始执行时间时,任务开始时系统会立即执行计划,后面的计划按照计划配置的开始时间进行计算
nameNode=hdfs://xingyunfei001.com.cn:8020
jobTracker=xingyunfei001.com.cn:8032
queueName=default
examplesRoot=user/hadoop001/examples/apps
oozie.coord.application.path=${nameNode}/${examplesRoot}/cron-test
start=2016-03-31T18:25+0800
end=2016-03-31T18:40+0800
workflowAppUri=${nameNode}/${examplesRoot}/cron-test
EXEC=hive-select.sh