重复数据删除简介
简介
重复数据删除,顾名思义,就是将多份重复的数据只存储一份,减少存储开销,同时也可以减少网络传输带宽。
重复数据删除有两种处理方式,一种是同步方式,即存入数据之前就判断是否是重复数据,如果重复则存储指向源数据的指针即可,如果新数据则存入到系统中;另一种是异步方式,即离线处理,开启后台进程扫描磁盘,查看是否有重复的数据。
文件级别
判断整个文件是否重复。
文件判重
首先在系统中维护一个hash表,存储所有unique文件的hash值。当读取到一个文件后,使用MD5或者sha-1计算给定文件的hash值,然后去hash表中查看是否已经存在。 如果存在,表明此文件已经存在,因此只需要存储指向源文件的指针即可,如果不存在,需要将此文件存储到系统中,并添加此hash值到hash表中,同时记录文件的地址。
优缺点
实现简单,粒度大,但是当文件有小范围的修改时,会导致系统重新存储整个文件,造成数据空间的浪费。如何能够当文件有小范围的修改依然能够删除冗余数据,只存储冗余的一部分呢?这就需要细粒度的重复数据删除了(即数据块级别)
数据块级别
将文件划分为数据块,针对每一个数据块计算hash值,并存储到系统块hash表中。新到来一个文件,将其划分为数据块,然后计算hash并与系统hash表对比,如果相同,则认为此块已经存在,不同则将此块加入到系统中。
固定块大小
将文件按照固定长度划分为块,进行hash的方式。这种方式实现简单,但是判断冗余的效率不高。例如文件中加入一个字节后,会导致此字节后面的数据块的hash全部失效(不能进行重复数据删除),而我们想要的效果应该是加入某些字节后,只让受影响的数据块不可用,而受影响的块之后的数据块依然可以进行重复数据删除。
举例:
abcdefghijkl按照块长度为4进行划分,可划分为三组( 即三个数据块):abcd, efgh, ijkl。
如果中间加入了一个字符1,变成ab1cdefghijkl,那么再进行固定划分的方式,可划分为4组:a1bc, defg, hijk, l。
可以看出没有一个数据块与原来的三个数据块相同,也就没有起到冗余数据删除的效果。
我们想要达到的应该是进行如下的划分: a1bcd, efgh, ijkl。 这样就会有两个块可以进行重复数据删除的,受影响的只是第一个块而已。
可变块大小
根据上面的描述,需要合理的进行块的划分,而且肯定不是固定块大小的划分。
首先说一下: Rabin fingerprint
给定一个n bit的 m0,m1,...,mn−1 数据 m ,可将其看作是基于有限域GF(2)的一个多项式,而且它的最高次项的指数为 n−1
然后我们选择一个素多项式 p(x) ,它的最高次项的指数为 k 。所谓素多项式,即是不可进行因式分解的多项式,类似于我们在算术运算领域的素数的概念。 例如 x2−1 就不是素多项式,因为它可以分解为$(x-1)(x+1)。
计算 f(x) 与 p(x) 的余数 r(x),即 r(x) = f(x) mod p(x) 。这个运算是基于GF(2),得到的余数 r(x) 的最高此项的指数为 k-1 ,因此可将其看作是一个 k bit的数字 r ,我们就称 r 是数据 m$的水印。
有了以上的理论,我们选择两个整数 p 和 r ,以及一个给定的长度 l ,开始对一串数据 s 进行匹配。 匹配的过程如下:首先从位置0开始,选择长度 l ,即 s0,s1,s2...,sl−1 ,将其定为上面的rabin算法的m,然后对 p 求余,看其是否等于 r ,如果相等,则定其为边界,如果不相等窗口后移一步,就这样一步步划分边界,得到 s 串的所有边界,然后计算利用边界将 s 串分割成多个字串,分别计算每一个字串的hash指纹,存储起来即可。
借用别人的一个图:
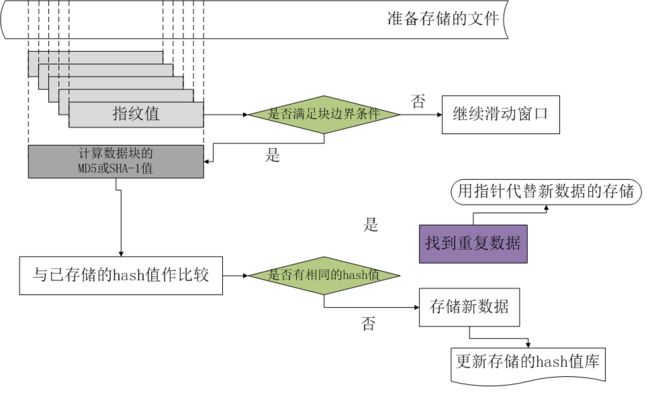
如上图所示,那个标有指纹值的数据块的长度就是上面提到的给定的长度 l ,此数据块即为消息 m , 使用此数据块与 p 求余判断是否等于 r ,如果满足边界条件,则在此处划定边界,如果不满足继续滑动窗口。等新文件到来时,同样使用此方法进行寻找边界,然后划分字串,然后计算字串的hash值,与已经存储的hash值比较是否相同,如果相同,则表明此块是重复数据,只存储指针指向源数据块,否则存储新的数据并更新hash表。
举例说明:
使用abcdefghijklmnopqrst进行举例
前提假设: 窗口的长度 l 等于2,同时假定cd, gh, mn, st这四个串在对p求余的时候等于r,也就是说这四个串的位置会被划分为边界。
\begin{aligned}
&l=2\\
&"cd" \ mod \ p = r \\
&"gh" \ mod \ p = r \\
&"mn" \ mod \ p = r \\
&"st" \ mod \ p = r
\end{aligned}
\end{equation}
运行过程: 首先从索引 k=0 ,选择长度为2的字符串进行匹配,也就是说 "ab" mod p ,经过运算发现不匹配,然后 k 后移一步,变成 k=1 ,继续扫描”bc”,运算不匹配;继续后移”cd”发现匹配,设置d的位置为边界;重复上述流程,则会有以下的边界:
abcd efgh ijklmn opqrst
新到字符串
a22bcdefghijklmnopq2rst
对于上面的新到来的字符串,同样进行上述的匹配过程,同样使用”cd, gh, mn, st”进行匹配分割边界,则会生成如下边界:
a22bcd efgh ijklmn opq2rst, 则会发现依然有两个串(efgh, ijklmn)可以进行匹配,这两个串就会根据hash比较进行重复数据删除,减少存储开销。