Pybrain 使用
Pybrain是我前几天妄想识别验证码时使用的一个手段,此为背景。
看了一篇文章后,看他说得比较准确,就暂时放弃对验证码进行破解工作。
这个是一位作者实践后的心得:
http://www.cnblogs.com/sweetwxh/p/captcha_recognize.html
Pybrain总体来说还是很好用的,鉴于没有太多相关的教程,在这里贴出来供大家参考。
PyBrain(Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network)是Python的一个机器学习模块,它的目标是为机器学习任务提供灵活、易应、强大的机器学习算法。
PyBrain正如其名,包括神经网络、强化学习(及二者结合)、无监督学习、进化算法。因为目前的许多问题需要处理连续态和行为空间,必须使用函数逼近(如神经网络)以应对高维数据。PyBrain以神经网络为核心,所有的训练方法都以神经网络为一个实例。
Pybrain 依赖项有 numpy、scipy,请自行找方法安装。
神经网络,包含三种层,一个是输入层,第二个是隐含层,第三是输出层。
官方文档里关于BP神经网络的介绍和使用说明:https://github.com/pybrain/pybrain/
这里我使用的是下面这个文档对爬去的验证码数据进行学习和验证。

建立样本集
inputVecTrain[i], outputVecTrain[i] 的格式是在Python下默认的list类型,如何生成这个列表,请查找相关资料。最终inputVecTrain和outputVecTrain是一个二维数组。
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.datasets import SupervisedDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
# 建立训练数据集,输入节点104个,输出节点36个
dsTrain = SupervisedDataSet(104, 36)
# 将输入输出数据加入Pybrain的数据集合
for i in range(len(inputVecTrain)):
dsTrain.addSample(inputVecTrain[i], outputVecTrain[i])
# 建立测试数据集
dsTest = SupervisedDataSet(104, 36)
# 将输入输出数据加入Pybrain的数据集合
for i in range(len(inputVecTest)):
dsTest.addSample(inputVecTest[i], outputVecTest[i])之后你可以遍历数据集里的数据,看看长的是什么样子。
for ipr, target in dsTrain:
print ipr
print target 这里是输出的样式,第一个是输入层数据,共104个;第二个是输出层数据,共36个。

建立神经网络
关于buildNetwork,官方文档里有说可以选择传递函数类型,这里默认选的是sigmod函数。
# 建立神经网络,输入层104,隐含层:100,输出层36
fnn = buildNetwork(104, 100, 36, bias=True)
#构建BP训练集
trainer = BackpropTrainer(fnn, dsTrain, momentum=0.1, verbose=True, weightdecay=0.01)开始训练
trainEpochs是每10次报告一次误差,在这个for循环里面总的迭代次数是2000次。
percentError是计算百分比误差。里面的第一个参数是选择的数据集,第二个选择的是何种的数据
#开始训练
for i in range(200):
trainer.trainEpochs(10)
trnresult = percentError(trainer.testOnClassData(), dsTrain['target'])
testResult = percentError(trainer.testOnClassData(dataset=dsTest), dsTest['target'])
print("epoch: %4d" % trainer.totalepochs, \
" train error: %5.2f%%" % trnresult, \
" test error: %5.2f%%" % testResult)第一行是 trainer.trainEpochs(10) 运行的输出结果(不是百分数)。后面是训练和输出的误差。
泛化
别看训练误差这么小,然而在实际泛化的时候,根本没法一一对应,识别率是0,惨不忍睹。
fnn.activate(ipr) 是用于训练后测试用的,返回值是BP输出层的实际输出。
for ipr, target in dsTest:
print target
result = fnn.activate(ipr)
print result
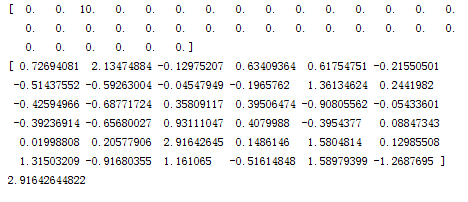
print result.max()以下,第一个数组是泛化样本,数组中的“10”对应于 字母“c”。
第二个数组中对应位置的实际输出是:“2.1347….”,而数组里最大的是“2.91642…”,在第5行,第3列。
已经完全跑偏了。
总结
之前想着神经网络的强大功能,没有对分割后的字符提取其特性值,所以识别率是0。现在对其也有了一个新的认识,光对神经网络进行长时间的训练并不是最主要的,特征提取更重要,这样它学习的效率和效果才会更佳!