Java数据结构----图的基础知识
1、概念
图: 是一种复杂的非线性数据结构。
图的二元组定义:
图 G 由两个集合 V 和 E 组成,记为:
G=(V, E) 其中: V 是顶点的有穷非空集合,
E 是 V 中顶点偶对(称为边)的有穷集。
通常,也将图 G 的顶点集和边集分别记为 V(G) 和 E(G) 。 E(G) 可以是空集。若 E(G) 为空,则图 G 只有顶点而没有边。
有向图: 若图 G 中的每条边都是有方向的,则称 G 为有向图 (Digraph) 。
无向图: 若图 G 中的每条边都是没有方向的,则称 G 为无向图 (Undigraph) 。
完全图:若无向图中的每个顶点之间存在着一条边,有向图中的每两个定点之间都存在着方向相反的两条边,则称此图为完全图。
稠密图: 当一个图接近完全图时,则称它为稠密图。
稀疏图:当一个图含有较少边数(即e<< n(n-1),双小于号表示非常小于的含义)时,则称它为稀疏图。
简单图:图中每条边的顶点均不相同。
邻接点:
有向图:如果 <u, v>∈ E, 则称v为u的邻接点,u为v的逆邻接点。边<u, v>与顶点u和v相关联,从u出发的边称为u的出边或邻接边,而指向顶点u的边称为u的入边或逆邻接边。
无向图:如果(u, v)∈ E, 则称u与v互为邻接点。
顶点的度、入度与出度:
依附与某顶点v的边数 称为度;
在有向图中,顶点v的 入度: 指以顶点为终点的边的数目。
出度:指以顶点起始点的边的数目;
无向图中出度入度相等。
通路或路径:由m+1个顶点与m条边交替构成的一个序列。
环路:如路径的第一个顶点和最后一个顶点相同,称之为环路。
可达分量:有向图中,若顶点s到v有一条通路,称v是从s可达的。对于s,从s可达的所有顶点的集合叫可达分量。
连通图:无向图中,若一个顶点到另一个顶点有路径,则称这2个顶点是连通的。如果图中任意2顶点都是连通的,则称该图是连通图。
连通分量:指无向图的极大连通子图。
权:与图中边有关的实数。
带权图或网:边上具有权值的图。
强连通分量(有向图):顶点s在图G中的可达分量 与 s在镜像图R(G)中的可达分量的交集。
最小生成树:从图中的不同顶点或从同一顶点按不同的优先搜素过程可以得到不同的树。而对于一个连通网(连通带权图)来说,生成的树不同,每棵树的代价(树中每条边上权值之和)也可能不同,代价最小的生成树为图的最小生成树。
图的遍历:具体实现:http://blog.csdn.net/ochangwen/article/details/50729993

图的深度优先遍历:1->2->4->6->5->3
图的广度优先遍历:1->2->3->4->5->6
深度优先就是由开始点向最深处遍历,没有了就回溯到上一级顶点
广度就是先把开始点的邻接的所有点都遍历了,没有了就开始遍历邻接点的第一个点,直到所有的遍历完成
最短路径—Dijkstra算法和Floyd算法:具体实现http://blog.csdn.net/ochangwen/article/details/50730937

1-->2 的最短路径是:7
1-->3 的最短路径是:9
1-->4 的最短路径是:20
1-->5 的最短路径是:20
1-->6 的最短路径是:11
单源最短路径算法,用于计算一个节点到其他!!所有节点!!的最短路径
1-->2-->3-->6-->4-->5-->
图的最小生成树:具体实现-->

一个连通图的生成树是一个极小的连通子图,它含有图中全部顶点,但只有足以构成一棵树的n-1条边。那么我们把构造连通网的最小代价生成树称为最小生成树。
找连通网的最小生成树,经典的有两种算法,普里姆算法和克鲁斯卡尔算法。下面分别介绍两种算法。
1、普里姆(Prim)算法
普里姆算法,图论中的一种算法,可在加权连通图里搜索最小生成树。意即此算法搜索到的边子集所构成的树中,不但包括连通图里的所有顶点,且其所有边的权值之和亦为最小。
1).顶点D被任意选为起始点;
2).顶点A、B、E和F通过单条边与D相连。A是距离D最近的顶点,因此下一个是A。
3).然后是F --> B --> E-->C-->G。最小生成树的权值之和为39。
邻接矩阵实现的普里姆算法的时间复杂度为O(n2)。
2、克鲁斯卡尔(Kruskal)算法
kruskal算法充分体现了贪心算法的精髓,该算法总共选择n- 1条边,(共n个点)所使用的贪婪准则是:从剩下的边中选择一条不会产生环路的具有最小耗费的边加入已选择的边的集合中。注意到所选取的边若产生环路则不可能形成一棵生成树。kruskal算法分e 步,其中e 是网络中边的数目。按耗费递增的顺序来考虑这e 条边,每次考虑一条边。当考虑某条边时,若将其加入到已选边的集合中会出现环路,则将其抛弃,否则,将它选入。
1).将所有的边的长度排序,用排序的结果作为我们选择边的依据。这里再次体现了贪心算法的思想。资源排序,对局部最优的资源进行选择
2).再选边:AD --> CE --> AB --> BE
3).下一步就是关键了。下面选择那条边呢? BC或者EF吗?都不是,尽管现在长度为8的边是最小的未选择的边。但是他们已经连通了(对于BC可以通过CE,EB来连接,类似的EF可以通过EB,BA,AD,DF来接连)。所以我们不需要选择他们。类似的BD也已经连通了(这里上图的连通线用红色表示了)。
4).最后就剩下EG和FG了。当然我们选择了EG
Kruskal算法的时间复杂度由排序算法决定,若采用快排则时间复杂度为O(N log N)。
克鲁斯尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势;
普里姆算法主要是针对顶点来展开,对于稠密图,即边数非常多的情况会更好一些。
2、图的抽象类型
public interface Graph {
public static final int UndirectedGraph = 0;//无向图
public static final int DirectedGraph = 1;//有向图
//返回图的类型
public int getType();
//返回图的顶点数
public int getVexNum();
//返回图的边数
public int getEdgeNum();
//返回图的所有顶点
public Iterator getVertex();
//返回图的所有边
public Iterator getEdge();
//删除一个顶点v
public void remove(Vertex v);
//删除一条边e
public void remove(Edge e);
//添加一个顶点v
public Node insert(Vertex v);
//添加一条边e
public Node insert(Edge e);
//判断顶点u、v是否邻接,即是否有边从u到v
public boolean areAdjacent(Vertex u, Vertex v);
//返回从u指向v的边,不存在则返回null
public Edge edgeFromTo(Vertex u, Vertex v);
//返回从u出发可以直接到达的邻接顶点
public Iterator adjVertexs(Vertex u);
//对图进行深度优先遍历
public Iterator DFSTraverse(Vertex v);
//对图进行广度优先遍历
public Iterator BFSTraverse(Vertex v);
//求顶点v到其他顶点的最短路径
public Iterator shortestPath(Vertex v);
//求无向图的最小生成树,如果是有向图不支持此操作
public void generateMST() throws UnsupportedOperation;
//求有向图的拓扑序列,无向图不支持此操作
public Iterator toplogicalSort() throws UnsupportedOperation;
//求有向无环图的关键路径,无向图不支持此操作
public void criticalPath() throws UnsupportedOperation;
}
3、图的存储方法
3.1、邻接矩阵表示法:
采用2个数组来表示图;一个是存储所有顶点信息的一维数组、一个是存储图中顶点之间关联关系的二维数组,这个二维数组称为邻接矩阵。

对于无向图a,邻接矩阵是一个对称矩阵。第i行(i列)非∞元素的个数正好是第i个顶点的度。
对于有向图b,第i行非∞元素的个数是第i个顶点的出度、i列非∞元素的个数是第i个顶点的入度。
邻接矩阵的不足:
1、由n个顶点构成的图中最多可以有n2条边,但大多数情况下,边的数目远远达不到这个量级,邻接矩阵中大多数单元都是闲置的。
2、矩阵结构是静态的,大小N需要预先估计,然后创建N*N的矩阵,而图的规模往往是动态变化的,N估计过大会造成空间浪费,过小则造成空间不够用。
3.2、邻接表表示法:
链接表是图的一种动态的链式存储方法,类似于树的孩子链表表示法。
对于n个顶点、m条边的无向图,采用邻接表,需要n个表头节点和2m个边表节点。在边稀疏的情况下,要比使用邻接矩阵节省空间。
邻接表的特性:
1.在无向图中,顶点v的度为v的邻接表中 表表节点的个数。
2.在有向图中,顶点v的邻接表中边表的节点个数仅为v的出度。入度需要遍历这个邻接表或者从逆邻接表中获取。判断2个顶点直接是否有边需要搜素2个顶点对应的邻接表。不如邻接矩阵方便。
3.3、双链式存储结构:
邻接表是图的一种很有效的存储结构,但是在该结构中删除顶点,边,或添加顶点,边的操作实现起来都比较复杂,所需时间代价较大。所以给出双链式存储结构解决上述问题。
顶点、边都抽象为独立的类,所有的顶点类都存储在一个链接表中,所有的边类也存储在一个链接表中。并在顶点、边之间建立关系。
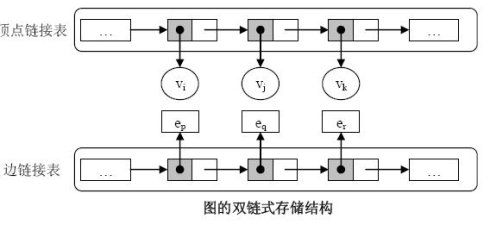
边中有5个重要的指针域:第一顶点域、第二顶点域、第一边表位置域、第二边表位置域、边位置域。
有向图中:第一顶点域指向该边的起始顶点在顶点表中的位置、第二顶点域指向该边的终止顶点在顶点表中的位置; 第一边表位置域指向边在其起始点的出边表中的位置,第二边表位置域指向边表在其终止点的入边表中的位置;
无向图:二个顶点域分别指向边的两个顶点在顶点表中的位置。第一边表位置域、第二边表位置域分别指向第一、第二顶点的邻接边表中的位置。
边位置域:指向边在边表中的位置。