《Flume 1.6.0 User Guide》基础入门
一、简介
Apache Flume是一个用于“从不同数据源节点(source)收集数据,保存到单一目的节点(sink)”的分布式框架。
二、体系结构
2.1、简单数据流
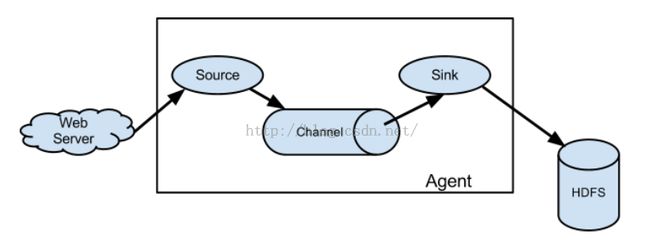
在一个简单数据流中包含3个部分:source节点,channel通道,sink节点。这样的一个简单的数据流被称为hop。
source节点从外部数据源(比如Web Server)获取数据,然后将其存入channel通道中;sink节点从channel通道中读取删除数据,然后将其存入外部存储区(比如HDFS)中。
其中,source节点往channel通道存入数据和sink节点从channel通道读取删除数据是异步进行的。
Flume Agent是一个Java进程,它提供source节点,channel通道,sink节点运行所需要的资源,即source节点,channel通道,sink节点所对应的Java片段在该进程中运行。
在有些语境中,hop和Flume Agent是等价的。
图示如下:
多个hop相连接,前一个hop的sink节点与下一个hop的source节点相连
2.2.2、数据分发
source节点的数据被分成多个部分,分别被分发给不同的channel通道
2.3、可靠传输
在Apache Flume中,采用事务机制,数据的传输是可靠的
三、运行
3.1、配置文件
要使得Apache Flume运行,首先得得到一个本地的配置文件。其中包括1个或多个hop(Flume Agent)的参数配置,其中还包括hop中source节点,channel通道,sink节点的参数配置以及它们之间的连接关系。
一个配置文件例子如下:
我们可通过telnet命令在44444端口上产生数据。
具体步骤如下:
1)执行“telnet localhost 44444”,即通过44444端口远程登录本机
2)输入消息,该消息被传递给本机的44444端口
Apache Flume是一个用于“从不同数据源节点(source)收集数据,保存到单一目的节点(sink)”的分布式框架。
二、体系结构
2.1、简单数据流
在一个简单数据流中包含3个部分:source节点,channel通道,sink节点。这样的一个简单的数据流被称为hop。
source节点从外部数据源(比如Web Server)获取数据,然后将其存入channel通道中;sink节点从channel通道中读取删除数据,然后将其存入外部存储区(比如HDFS)中。
其中,source节点往channel通道存入数据和sink节点从channel通道读取删除数据是异步进行的。
Flume Agent是一个Java进程,它提供source节点,channel通道,sink节点运行所需要的资源,即source节点,channel通道,sink节点所对应的Java片段在该进程中运行。
在有些语境中,hop和Flume Agent是等价的。
图示如下:
2.2、复杂数据流
2.2.1、多hop多个hop相连接,前一个hop的sink节点与下一个hop的source节点相连
2.2.2、数据分发
source节点的数据被分成多个部分,分别被分发给不同的channel通道
2.3、可靠传输
在Apache Flume中,采用事务机制,数据的传输是可靠的
三、运行
3.1、配置文件
要使得Apache Flume运行,首先得得到一个本地的配置文件。其中包括1个或多个hop(Flume Agent)的参数配置,其中还包括hop中source节点,channel通道,sink节点的参数配置以及它们之间的连接关系。
一个配置文件例子如下:
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
其中定义了一个Flume Agent实例(名称为a1),a1中有source节点实例(r1),channel通道实例(c1)和sink节点实例(k1)。r1节点从netcat命令获取数据,r1节点与c1通道绑定;k1节点与c1通道绑定,k1节点将数据传递给日志处理框架。
3.2、开始运行执行“bin/flume-ng agent -n a1 -f config.properties -Dflume.root.logger=INFO,console”命令,开始运行"a1"这个Flume Agent。
其中"-n"选项的值表示Flume Agent的实例名称,"-f"选项的值表示配置文件的路径。
此时本机44444端口上的数据会通过该Agent被传递给日志处理框架,由于“-Dflume.root.logger=INFO,console”的设置,日志处理框架直接在控制台打印数据。我们可通过telnet命令在44444端口上产生数据。
具体步骤如下:
1)执行“telnet localhost 44444”,即通过44444端口远程登录本机
2)输入消息,该消息被传递给本机的44444端口
3)Flume Agent从44444端口上获取数据,将其传递给日志处理框架,这里是直接在控制台中打印
参考文献:
[1]https://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.pdf