shell脚本学习笔记 (正则表达式)
正则表达式一般有三个部分组成,他们分别是:字符类,数量限定符,位置限定符。规定一些特殊语法表示字符类、数
量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式(Regular Expression)。我们以一
个例子开始吧。假如给你一个文件,里面存放的是IP地址,但是有一些不是合格的,请你找出合格的IP地址。我想不知道正
则表达式的人一定会觉得好陌生,我拿一个循环去实现,我之前也被问到过这个问题,也是想着拿循环来完成,写出一个函
数来实现这个查找功能实在是不简单,而且不能保证正确性。这时候正是正则表达式登场的时候了。下面是我写的一个正则
表达式:
此时此刻是不是觉得挺神奇的,我当时也感觉到了,上面的五个“IP”地址中,只有一个满足要求的,我们一条
命令就找出来了,是不是顿时被吸引住了,那么我们开始正则表达式的探讨吧。
1.字符类:
它们在模式中表示一个字符,但是取值范围是一类字符中的任意一个。常见的字符类如下:

我写了一些简单的代码来验证上述字符类
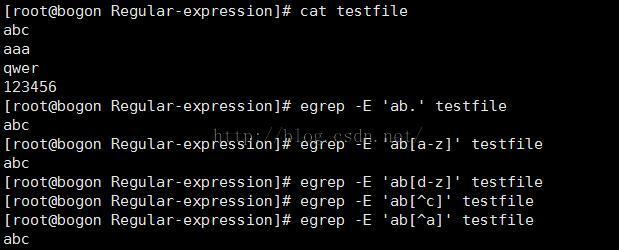
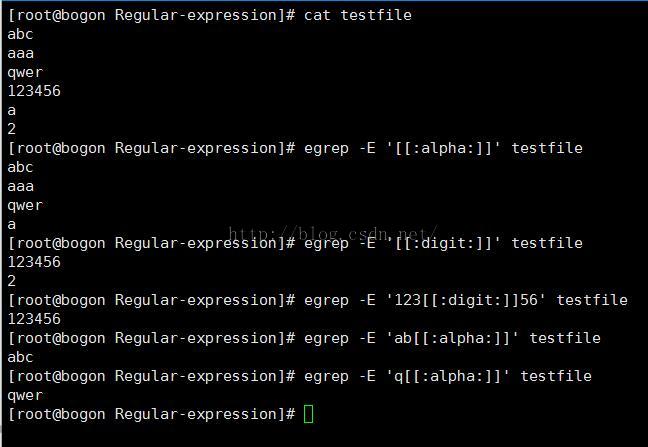
2.数量限定符
数量限定符指明字符类出现的次数,以帮助模式匹配,常见的数量限定符如下:
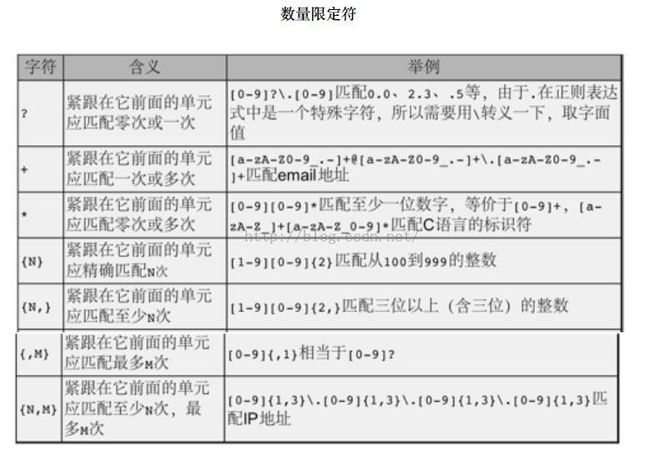
我写的测试代码如下:
我的使用的是centos,不知道细心的你发现没有,有一条语法不支持即:{ ,M}。Z这个在别的linux上是可以的,
比如ubantu,我想这个问题应该是不同平台的差异导致的吧。我在同学的ubantu平台下测试了是可以的,这点可以保证。
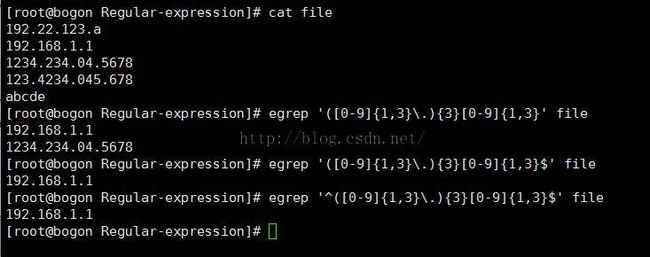
3.位置限定符
顾名思义位置限定符使用限定字符类的位置的,比如我们还是拿IP地址来说吧,IP地址分为四个部分,每两个部分之间
拿 '.' 隔开,而每一部分都可以拿字符类和数量限定符描述。
特殊字符:
1. \ 该字符用于转移,上面的例子中使用到 '.' 的时候都要用 '\' 转移一下,否则无法被解释
2. | '|' 可用于连接两个 字表达式
3. () '()'可将莫一部分作为一个整体,然后我们可以对整体进行操作

到这里正则表达的语法基本上讲完了,下面对以上事例中使用到的工具进行简单的介绍,grep工具相信大家都知道
吧,linux平台下的自带的工具,对grep的介绍我引用搜狗百科的介绍:grep是一种强大的文本搜索工具,它能使用正
则表达式搜索文本,并把匹配的行打印出来。Unix的grep家族包括grep、egrep和fgrep。利用这些返回值就可进行一
些自动化的文本处理工作。 我在上面的例子中使用的是egrep工具,是grep的扩展,这个工具的更多用法以及上面介绍
的一些不充分的地方大家可以去百科上查找一下,其实还有一些更高级的工具也是支持这则表达式的,我将在结下来的
博客中再介绍。
我个人觉得死记这些这些字符的意思是不恰当的,我们应该通过不断的练习来学习正则表达式,这样才能达到好的效
果,忘记的时候我们可以去看一看这些正则表达式的模块的用处,最后希望对大家有一些帮助。