淘宝Diamond架构分析
花了两天的时间研究了下Diamond,因为写得比较急,而且并没有使用过,只是单纯的做逆向建模,所以难免会有细节缺失,后面会时不时过来看看,然后做些补充。
背景知识
比较早的时候,应用一般都是单体的,配置修改后,只要通过预留的管理界面刷新进行reload即可。
慢慢的,应用都主动或被动被拆分,从单一系统拆分成多个子系统,每个子系统还会对应多个运行实例。此时就面临多个问题:
1. 配置分散在多个业务子系统里,对同一配置的翻译在多个子系统里经常不一致。比如订单和购物车都有货币类型的配置,如果购物车上了一种新的货币类型而订单却没有相应同步增加配置项就会造成程序错误。
2. 将配置收敛成一个公有服务,可以有效改善,但是又会带来其他问题。在复杂应用里,修改一个配置项,无法确切的知道需要刷新哪些相关子系统。最终只能做全量刷新,甚至是停机发布。这对于一些停机敏感的应用例如电商几乎是无法接受的。
3. 配置收敛后,配置中心成了应用中的单点,配置如果挂了,应用也会跟着产生异常甚至挂掉。所以配置服务器需要保证高可用。
Diamond就是为了解决这些问题而产生的。
Diamond的配置类型
配置是Diamond的核心域,也是Diamond致力于去解决的问题。首先看下Diamond的两个主要配置类型– single和aggr。二者结构如下:
Aggr和single相比,少md5多datumId。DatumId是aggr的逻辑主键,多条aggr会聚合成一条配置,也就是说多条aggr记录(多个datumId)会对应同一个dataId。diamond通过merge任务对aggr合并最终生成一条single。
md5是对content md5编码生成的字符串,用于比对缓存数据和数据库数据是否有改变。只有single配置才有md5,aggr其实并不算是完整的配置(多条aggr一起才是一个完整的配置),所以不需要校验数据是否改变。
整体架构设计
下图是Diamond的组件视图。Diamond主要有ops, sdk, client和server 4个组件。Ops是运维用的配置工具,主要用于下发以及查询配置等;server则是Diamond的后台,处理配置的一些逻辑;sdk则是提供给ops或者其他第三方应用的开发工具包;client则是编程api,它和sdk乍看有点像,其实差别很大,sdk是用于构建前台运维配置程序的,本质是对数据的维护,而client则是这些数据的消费者,事实上准确的说是diamond的消费者们(各子系统)都是通过client组件对server访问。

Diamond server是无中心节点的逻辑集群,app的访问请求都是读local file缓存,而写请求则会直接写入数据库,再更新各节点缓存。注意:ops或者其他第三方运维系统(其实就是sdk模块)读取的是数据库实时数据,这很容易理解,缓存会有lag,配置系统必须知道的是实时数据。
从Diamond的整体架构来看,数据库还是单点的,利用数据库特性可以保证数据的原子性,一致性和持久性,这样就不需要实现类似zk的集群协议,也就不存在leader/follower以及observer等节点角色,所有节点都可以接受任意的请求。Diamond是典型的读多写少,写一般都来自运维系统例如ops,即使峰值时期对数据库的冲击也不会太大。从这个角度看,diamond实际上是在数据库上层的一个保护壳,数据库的数据通过它透出来,也通过它渗进去。
Diamond的同质节点之间会相互通信以保证数据的一致性,每个节点都有其它节点的地址信息,其中一个节点收到变更请求后,首先写入数据库,再通知所有涉及节点更新缓存,保证数据的一致性。
为了保证高可用,client还会在app端缓存一个本地文件,这样即使server不可用也能保证app可用。
长轮询
Client不断长轮询server,获取最新的配置推送,尽量保证本地数据的时效性。
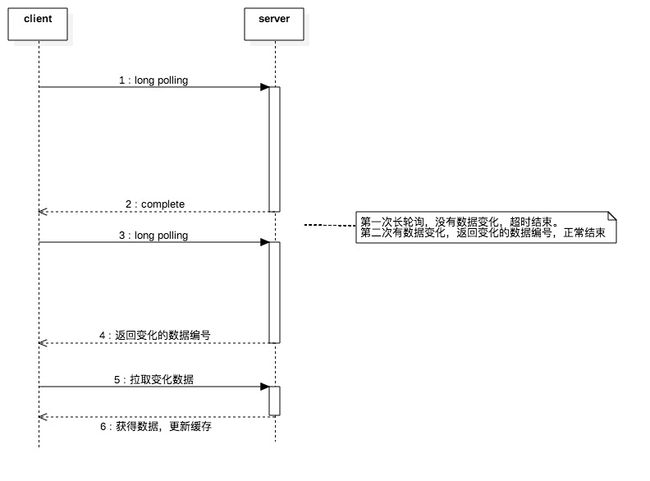
Client默认启动周期任务对server进行长轮询感知server的配置变化,server感知到配置变化就发送变更的数据编号,客户端通过数据编号再去拉取最新配置数据;否则超时结束请求(默认10秒)。拉取到新配置后,client会通知监听者(MessageListener)做相应处理,用户可以通过Diamond#addListener监听。
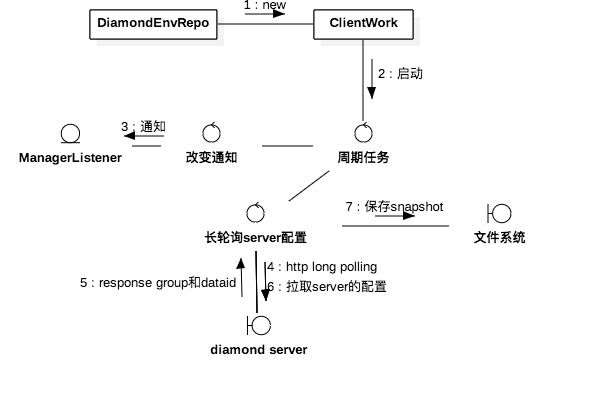
服务端通过AsyncContext对请求做非阻塞处理,通过定时任务感知配置变化。
详细描述下上图,
1. server收到请求后启动AsyncContext,并基于它构造ClientLongPulling。ClientLongPulling除了AsyncContext还有一个超时回复任务对长轮询请求做超时处理
2. 之后ClientLongPulling被加入等待列表。LongPullingService关联一个感知数据变化的定时任务,当有数据变化时,就会循环等待列表里的ClientLongPulling,推送数据变化回客户端。
4. Dump是抽象出来的一块儿概念,server的数据变化都会触发响应的dump task,并会发送相应的事件,由server感知,DataChangeTask也是一个事件监听者,能感知local file的数据变化。
服务端架构设计
前面介绍过Diamond集群是去中心化的,使用通知机制保证集群各节点数据一致。

1. Diamond集群内每个节点都有其他节点的地址信息,当一台节点对配置做了修改就会发送ConfigDataChangeEvent,监听者收到该事件后通知所有节点做数据变更。这里需要注意的一点是通知所有节点也包括自己,下发配置的请求只会更新数据库,并不会更新本地文件缓存。
2. 通知发送到所有节点后,通过dump更新local file。Dump是将配置对象dump进本地文件的过程,dump完毕后发送LocalDataChangeEvent,引起客户端进行应答响应。
任务管理
Diamond收到配置请求后,数据库执行完毕后,向任务管理的任务栈里插入一条任务,任务管理模块感知到新任务后,使用对应的TaskProcessor处理。TaskProcessor和Task的关系由用户调用TaskManager#addProcessor(或setDefaultProcessor)设置。Diamond的任务管理器是FIFO的,这就会造成长延时任务阻塞其他任务的执行。
在Diamond中,为解决这个问题,为每个Task都定制了一个TaskManager。用户可以做些优化,参考hadoop的公平算法,针对应用场景(比如长延时,离线,实时等等)定制TaskProcessor。
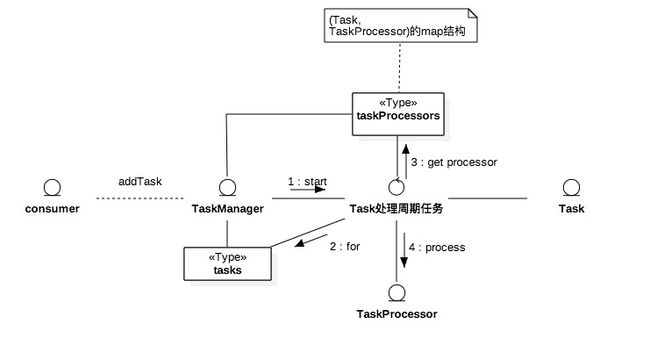
其他一些任务
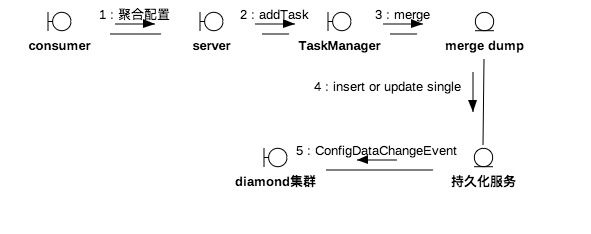
为了保证Diamond的数据一致,除了以上介绍的两类任务,还有其他一些task,见下图:
1. Merge任务用于合并aggr。App下发聚合配置到diamond后,会触发合并任务生成single,同时广播配置变更事件(ConfigDataChangeEvent),各节点收到通知后拉取数据库相应single数据并更新local file。这与上面描述的server数据同步基本类似,只是事件源头换成了merge。
2. DumpAllTask会每6小时run一次做全量dump,全量删除老的缓存数据,生成新缓存。
2. DumpChangeTask做增量dump。通过和数据库的配置做md5对比,删除被移除配置的文件缓存,更新md5不一致的文件缓存等等。
3. 清除历史数据用于清除1周前的数据库his表数据。
4. 心跳任务用于记录心跳时间,节点服务重启时会判断距离上次心跳时间是否已经超过一小时,超过一小时则做全量dump,否则做增量。
剩下的都很好理解,不再一一介绍,需要注意的是,这些任务里并不是所有的都是定时做,有些是事件触发的,例如DumpTask和merge;还有些在Diamond服务启动时会触发,如merge,DumpChangeTask等。