1 概述1.1 研发背景
支撑互联网应用的各种服务通常都是用复杂大规模分布式集群来实现的。而这些互联网应用又构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开 发、可能使用不同的编程语言来实现、有可能布在了几千台服务器,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工 具。
hydra分布式跟踪系统就为了解决以上这些问题而设计的。
1.2 理论依据Google的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》是我们设计开发的指导思想(原文和译文地址 https://github.com/bigbully/Dapper-translation)。Google针对自己的分布式跟踪系统Dapper 在生产环境下运行两年多时间积累的经验,在论文中重点提到了分布式跟踪系统对业务系统的零侵入这个先天优势,并总结了大量的应用场景,还提及它的不足之 处。我们通过对这篇论文的深入研究,并参考了Twitter同样依据这篇论文的scala实现Zipkin,结合我们自身的现有架构,我们认为分布式跟踪 系统在我们内部是非常适合的,而且也是急需的。
1.3 功能概述hydra目前的功能并不复杂,他可以接入一些基础组件,然后实现在基础组件上收集在组建上产生的行为的时间消耗,并且提供跟踪查询页面,对跟踪到的数据进行查询和展示。
我们会在之后的功能介绍中对hydra现有功能进行说明。
2 领域模型分布式跟踪的领域模型其实已经很成熟,早在1997年IBM就把ARM2.0(Application Response Measurement)作为一个公开的标准提供给了Open Group,无奈当时SOA的架构还未成熟,对业务的跟踪还需要直接嵌入到业务代码中,致使跟踪系统无法顺利推广。
如今互联网领域大多数后台服务都已经完成了SOA化,所以对业务的跟踪可以直接简化为对服务调用框架的跟踪,所以越来越多的跟踪系统也涌现出来。 在hydra系统中,我们使用的领域模型参考了Google的Dapper和Twitter的Zipkin(http://twitter.github.io/zipkin/)。
2.1 hydra中的跟踪数据模型参考Dapper和Zipkin的设计,hydra也提炼出了自己的领域模型,如图所示:

-
Trace:一次服务调用追踪链路。
-
Span:追踪服务调基本结构,多span形成树形结构组合成一次Trace追踪记录。
-
Annotation:在span中的标注点,记录整个span时间段内发生的事件。
-
BinaryAnnotation:属于Annotation一种类型和普通Annotation区别,这键值对形式标注在span中发生的事件,和一些其他相关的信息。
Annotation在整个跟踪数据模型中最灵活的,灵活运用annotation基本能表达你所想到的跟踪场景。在hydra中(参考了zipkin)定义4种不同value的annotation用来表达记录span 4个最基本的事件。通过这4个annotation能计算出链路中业务消耗和网络消耗时间。
2.2 dubbo服务调用框架的模型公司内部,尤其是我们部门有很多业务系统使用dubbo作为服务调用框,所以我们的分布式跟踪系统第一个接入组件就是dubbo。 另一个原因也是因为我们团队对dubbo有着非常深入的理解,加之dubbo本身的架构本身十分适合扩展,作为服务调用框架而言,跟踪的效果会非常明显, 比如Twitter的Zipkin也是植入到内部的Finagle服务调用框架上来进行跟踪的。
由于现阶段hydra主要接入了dubbo服务调用框架,所以在这必须了解dubbo的几个模型,如下图所示:
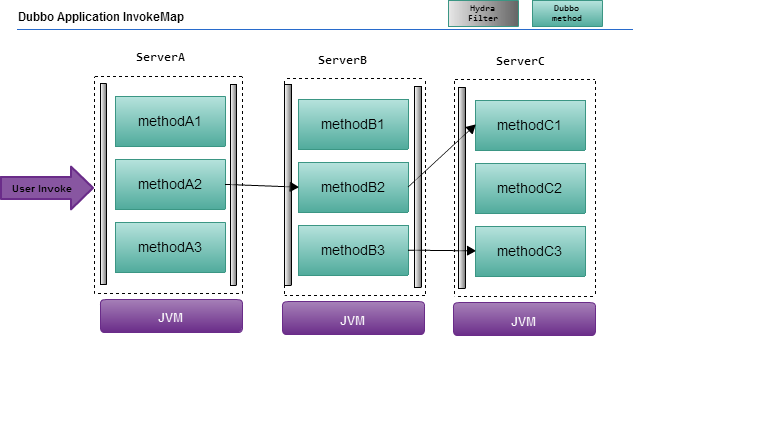
-
Application:一类业务类型的服务,下面可能包含多个接口服务,可能出现多种类型业务跟踪链路。
-
InterfaceService:接口服务,一个服务接口提供多种业务处理方法。
-
Method:接口服务中具体处理业务的方法。
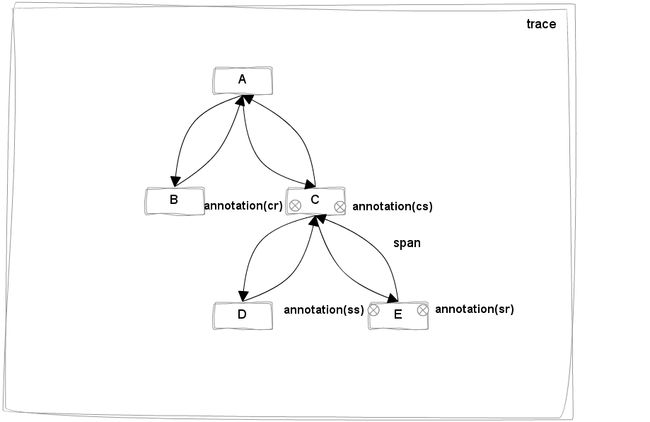
如图所示的应用场景对A服务的调用。A服务在被调用的过程中会继续调用服务B和服务C,而服务C被调用之后又会继续调用服务D和服 务E。在我们的领域模型中,服务A被调用到调用完成的过程,就是一次trace。而每一个服务被调用并返回的过程(一去一回的箭头)为一个span。可以 看到这个示例中包含5个span,client-A,A-B,A-C,C-D,C-E。span本身以树形结构展开,A-C是C-D和C-E的父 span,而client-A是整个树形结构的root span。之后要提到的一个概念就是annotation,annotation代表在服务调用过程中发生的一些我们感兴趣的事情,如图所示C-E上标出 来的那四个点,就是四个annotation,来记录事件时间戳,分别是C服务的cs(client send),E服务的ss(server receive),E服务的ss(server send), C服务的cr(client receive)。如果有一些自定义的annotation我们会把它作为BinaryAnnotation,其实就是一个k-v对,记录任何跟踪系统想 记录的信息,比如服务调用中的异常信息,重要的业务信息等等。
3 功能介绍当前hydra1.0版的功能主要分为两个部分,跟踪查询和跟踪展示。
如图所示为查询页面:
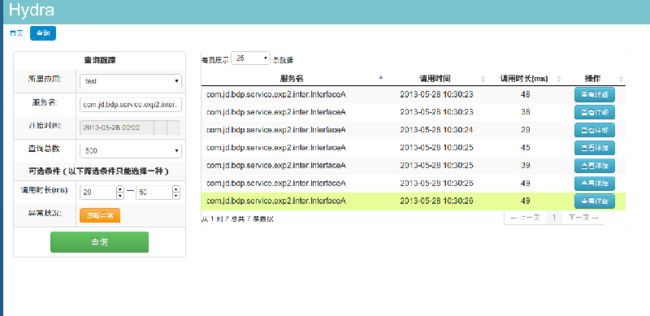
在hydra针对业务提出两个相关的概念:应用和服务。不同的业务的所属不同的应用(相当于dubbo中的Application),服务(相当于dubbo中的interface)挂在应用之下。
在hydra的查询界面中首先要选择想要关注的应用名,然后通过自动完成的方式输入应用下的服务。选择服务的开始时间和需要查看的跟踪次数。另外hydra需要确定返回数据的总量,防止查询出大数据量导致页面失去响应。
另外我们提供对额外的筛选条件:调用响应时间、是否发生异常。调用响应时间指的是这一次服务调用从调用开始到调用结束的时间,是否发生异常则包括一次服务调用中所有历经的服务抛出的异常都会捕获到。
对于查询之后的数据,hydra提供在前台进行排序的功能。
对于每一次跟踪,我们可以进一步展示他的服务调用层级与响应时间的时序图。如下图所示:
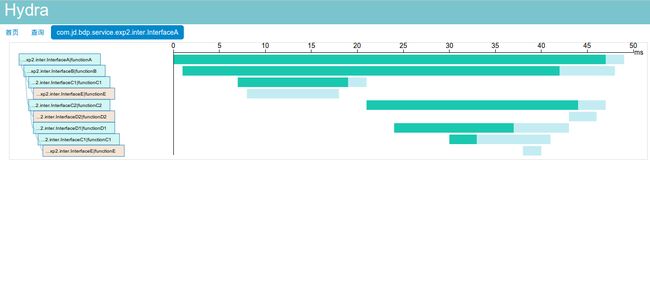
我们参考Dapper中论述的场景,在时序图中用绿色代表服务调用时间,浅蓝色代表网络耗时,另外如果服务调用抛出异常被 hydra捕捉到的话,会用红色表示。鼠标移动到时序图中的每一个对象上,会Tip展现详细信息,包括服务名、方法名、调用时长、Endpoint、异常 信息等。
左侧的树形结构图可以收起和展开,同时右侧的时序图产生联动,利于调整关注点在不同的服务上。
4 整体架构4.1 完整版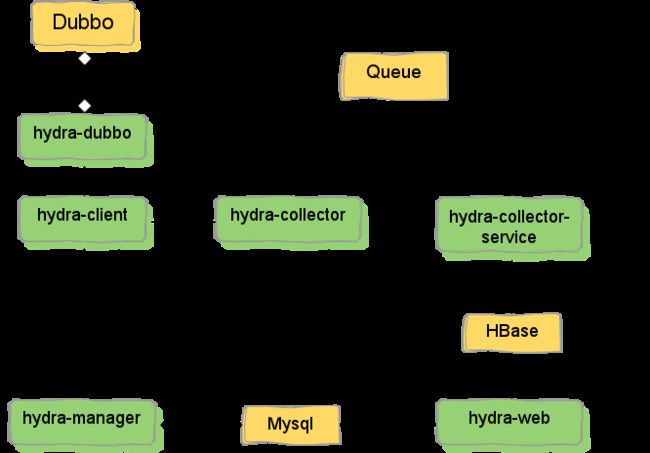
对于分布式跟踪系统而言,必须对接入的基础组件进行改造,我们对dubbo的改造很简单,只是在过滤器链上增加一个过滤器,我们将其封装成一个hydra-dubbo的jar包,由dubbo直接依赖。
所有跟踪所需的通用性的API我们封装在hydra-client中,遍于接入各种组件。 hydra-manager用来完成每个服务的注册、采样率的调成、发送seed生成全局唯一的traceId等通用性的功能。所有hydra-manager数据统一用mysql进行存储。
我们使用hydra-collector和hydra-collector-service进行跟踪数据的异步存储,中间使用metaQ进行缓冲。
hydra-manager和hydra-collector使用dobbo提供服务。
4.2 精简版考虑到数据量不大的情况,以及部署的复杂度。我们提供了两种更简便的架构
-
如果考虑到数据量没有那么大,可以不使用hbase,用mysql代替,即精简版1。因为毕竟hadoop集群和hbase集群的部署和维护工作量很大。
-
如果并发量也不是很大的话,可以不使用消息中间件,也就是精简版2,如图所示。在hydra-collector端直接进行数据落地,当然仍然是异步的。

在使用mysql进行存储的时候我们并未进行分库分表,因为考虑到存储的是监控数据,时效性较高,而长期的监控数据的保留意义并不大。所以我们在主表上有明确的时间戳字段,使用者可以自行决定何时对保存的历史数据进行迁移。
5 Quick Start5.1 部署简介Hydra分布式跟踪系统可以跟踪环境的数据量大小选择上文所述的三种部署方式
-
高并发,大数据量:hydra-client | Queue | hbase
-
高并发,小数据量:hydra-client | Queue | mysql
-
低并发,小数据量:hydra-client | mysql
因为是quick start,这里只介绍低并发和小数据量的情况。不过这里会详细介绍如何通过配置文件的修改来切换这三种部署方式。
5.2 硬件要求-
1或多台业务系统集群机
-
1套zookeeper单点或集群机
-
1台机器部署Hydra-manager
-
1或多台机器部署Hydra-Collector
-
1台机器部署Hydra-web
-
1台数据库服务器
-
Dubbo:Hydra是基于alibaba的dubbo框架基准上做的服务跟踪系统,理论上原有的Dubbo框架服务群中所有应用不需要额外的配置,皆可以平滑的接入Hydra系统。
-
Zookeeper:各个服务点依赖于zookeeper来读取Hydra-manager和Hydra-collector获取数据交互路由点,来完成跟踪数据的推送和跟踪的控制。
-
Mysql:跟踪数据的持久化存储。
-
Tomcat:前端web应用容器
可以暂时使用master,后续版本会归并到dubbo管理端
5.5 项目构建打包maven项目不用多说。mvn clean install。不过不得不说的是,hydra项目中包含一些涉及数据库读写的单元测试(mysql,hbase),配置文件分别在:
-
modules/hydra-manager-db/src/test/resources/mysql.properties
-
modules/hydra-store/hydra-mysql/src/test/resources/mysql.properties
-
modules/hydra-store/hydra-hbase/src/test/resources/hbase-site.xml
-
modules/hydra-store/hydra-hbase/src/test/resources/hydra-hbase-test.xml
mysql需要创建测试用数据库和测试用表,hbase需要创建测试用表
-
docs/table-hbase/initTable
(hbase建表时可以根据hbase集群的具体情况调整域分区,涉及到table-mysql中对TB_PARA_SERVICE_ID_GEN初始化数据的设计) -
docs/table-mysql
当然对于不需要使用hbase的同学也可以自行移除modules/hydar-store/hydra-hbase。
当然用maven构建跳过测试也是可以的。使用mvn clean install -Dmaven.test.skip=true
需要打包的子项目会通过maven:assemblly插件打成tar.gz包在各自的target目录下。
5.6 安装部署5.6.1 Hydra-clienthydra-client中包含hydra与dubbo的集成,以及hydra跟踪收集的相关功能。如果需要进行dubbo服务的跟踪,只需要把这个jar包放在dubbo服务的classpath下,就会自动开启跟踪功能!
5.6.2 Hydra-manager-
部署:scp -r target/*.tar.gz username@ip:dirname
-
配置:cd basedir/conf (需要修改配置)
-
启动:cd basedir/bin
sh manager.sh start -
停止:cd basedir/bin
sh manager.sh stop -
输入:cd basedir/log
tail -f manager.log
-
部署:scp -r target/*.tar.gz username@ip:dirname
-
配置:cd basedir/conf (需要修改配置)
-
启动:cd basedir/bin
sh collector-mysql.sh start
(这里注意一下,如果在hydra-collector中需要发送到Queue中,则需要启动collector.sh,jar包会加载不同的配置文件。) -
停止:cd basedir/bin
sh collector-mysql.sh stop -
输入:cd basedir/log
tail -f *.log
-
需要在web.xml中修改引入的配置文件为hydra-mysql.xml,注掉hydra-hbase.xml
-
部署:scp -r target/*.war username@ip:$TOMCAT_WEBAPPS
我们模拟了两个测试场景,均是基于dubbo服务调用
场景exp1:
A --> B --> C
即服务A调用服务B,服务B调用服务C。测试用例在modules/hydra-example/hydra-exmple-exp1/。熟悉dubbo的同学一定不会陌生。
场景exp2:
A --> B --> C1 --> E --> C2 --> D1 --> C1 --> E --> D2
场景2很复杂,基本涵盖了对同步调用跟踪的大多数可能遇到的场景。测试用例在modules/hydra-example/hydra-exmple-exp2/。
6.2 模拟场景dubbo服务的部署Hydra默认使用了hydra-exmple中的两个应用场景来做,你可以在hydra-test/hydra-test-integration打包中获得应用场景。
获得tar.gz包或者zip包后,将服务分布式部署到不同的机器上,以模拟应用场景,一下介绍场景一的部署方法,场景二的部署方法类似。
hydra-test-intergration 分为windows版和linux版(默认),见如下打包方法。
-
打包:linux: mvn package -Pruntime-env-linux
window: mvn package -Pruntime-env-windows -
部署: scp -r target/*.tar.gz username@ip:dirname
-
配置: cd basedir/conf
修改 *exp1.properties -
启动: cd basedir/bin
cd exp1
sh startA.sh
cd ..
sh startTrigger-exp1.sh start -
停止: cd basedir/bin
sh startTrigger-exp1.sh stop
All.sh stop -
输出: cd basedir/log
tail -f *.log
以下演示安装样例:
-
部署zookeeper单点或集群环境,以保证获得最佳SOA,zookeeper的部署请参照官方文档。
-
部署实验场景exp1,只需要部署hydra-test-integration模块打包的tar.gz包,拷贝三份分布式部署。
-
部署一个触发器Trigger,以激活服务的调用。
-
部署一个Manager,以管理各个跟踪点的跟踪上下文。
-
部署一个或者多个Collector消费机集群,以搜集来自Hydra-client推送过来的跟踪数据。
-
部署一个web应用,已提供给前端展现应用系统服务上下文。
exp1场景说明:
有三个服务应用A、B、C和一个触发RPC调用的应用Trigger,服务调用关系为A-B-C, 每隔500s触发一个调用,持续时间为1天。
部署地址举例:
角色ipportZK192.168.200.110-1122181~A192.168.200.11020990B192.168.200.11120991C192.168.200.11220992Trigger192.168.200.113-Manager192.168.228.8120890Collector192.168.228.81-8220889Web192.168.228.818080MySql-DB192.168.228.8133067 测试相关7.1 测试说明本测试针对Hydra-Client模块进行功能测试和压力测试,以便在Hydra开发的过程中及时发现重要bug和帮助优化Hydra系统性能。
本测试目前只针对Hydra-client的测试,重点关注业务系统接入Hydra和不接入Hydra前后性能影响,以保证Hydra系统接入端的低侵入性和稳定性。
针对Hydra-Client的测试,在部署上,只用部署应用场景(带Hydra_client)和Benchmark触发点,然后在应用Benchmark和应用场景上埋点分析Hydra性能。