Centos7中安装hadoop-1.2.1
在Linux中存放软件压缩包和安装软件的目录说下
/opt/software/ --存放软件压缩包
/opt/modules/ --存放安装软件包
/opt/tools/ --存放工具包
/opt/data/ --存放测试数据
以上是我规定的目录,也可以自行设置软件的安装目录和存放软件压缩包
1、解压hadoop-1.2.1
tar -zxvf /opt/software/hadoop-1.2.1-bin.tar.gz
2、拷贝解压缩后的文件到modules目录
sudo cp hadoop-1.2.1 /opt/modules/
一、首先配置单机模式
1、配置jdk到hadoop-env.sh
vim hadoop-1.2.1/conf/hadoop-env.sh
加入如下内容
export JAVA_HOME=/opt/modules/jdk1.7.0_79
自己安装的jdk路径
source /opt/modules/hadoop-1.2.1/conf/hadoop-env.sh
3、在profile文件中增加hadoop的安装路径
vim /etc/profile
在配置文件中末尾追加以下内容
export HADOOP_HOME=/opt/modules/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
使配置生效
source /etc/profile
4、测试配置是否成功
hadoop
Warning: $HADOOP_HOME is deprecated.
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
datanode run a DFS datanode
dfsadmin run a DFS admin client
mradmin run a Map-Reduce admin client
fsck run a DFS filesystem checking utility
fs run a generic filesystem user client
balancer run a cluster balancing utility
oiv apply the offline fsimage viewer to an fsimage
fetchdt fetch a delegation token from the NameNode
jobtracker run the MapReduce job Tracker node
pipes run a Pipes job
tasktracker run a MapReduce task Tracker node
historyserver run job history servers as a standalone daemon
job manipulate MapReduce jobs
queue get information regarding JobQueues
version print the version
jar <jar> run a jar file
distcp <srcurl> <desturl> copy file or directories recursively
distcp2 <srcurl> <desturl> DistCp version 2
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
5、测试MapReduce是否正常
进入data目录
cd /opt/data/
6、创建input文件夹
sudo mkdir input7、拷贝文件到这个目录
sudo cp /opt/hadoop-1.2.1/conf/*.xml input
8、执行hadoop中自带的例子
进入hadoop目录
cd /opt/modules/hadoop-1.2.1/
9、执行
bin/hadoop jar hadoop-examples-1.2.1.jar grep /opt/data/input/ /opt/data/output 'dfs[a-z.]+'
10、如果在output目录下出现比如
part-00000 _SUCCESS俩个文件,说明执行成功过
11、进入以下文件
more part-00000
1 dfsadmin
有以上内容,说明已经完全执行成功
二、接下来配置伪分布式
1、首先配置核心文件
vim conf/core-site.xml

在以上的“configuration”标签下加入以下图示内容

代码如下
<property><!--配置HDFS的地址和端口号-->
<name>fs.default.name</name>
<value>hdfs://master.dragon.org:9000</value>
</property>
<property><!--配置HDFS数据的存放目录-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
2、接下来配置hdfs文件
vim conf/hdfs-site.xml

在以上的“configuration”标签下加入以下图示内容

代码如下
<property><!--配置HDFS的备份方式默认为3,在单机版的为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property><!--配置HDFS的验证,这里不让他验证-->
<name>dfs.permissions</name>
<value>false</value>
</property>
3、配置MapReduce文件
vim conf/mapred-site.xml
在以上的“configuration”标签下加入以下图示内容
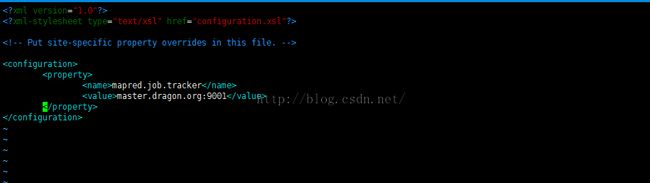
<property><!--配置MapReduce的访问地址-->
<name>mapred.job.tracker</name>
<value>master.dragon.org:9001</value>
</property>
4、配置conf文件夹下的masters文件
vim conf/masters
写Linux配置的全限定名
5、配置conf文件夹下的slaves文件
vim conf/slaves

6、格式化namenode
bin/hadoop namenode -format
7、启动hadoop
bin/start-all.sh
8、用jps查看启动的进程,如果是五个说明就成功了。
9、然后再浏览器中输入master.dragon.org:50070,如果访问成功,出现如下界面

10、如果想要在windows下面访问hadoop,就要在hosts文件中增加Linux主机IP和主机名
11、测试
上传文件到hdfs文件系统中
首先在文件系统中创建存放文件的目录
hadoop fs -mkdir hdfs://master.dragon.org:9000/wc/input/
查看是否创建成功
hadoop fs -lsr hdfs://master.dragon.org:9000/
drwxr-xr-x - root supergroup 0 2016-01-05 17:18 /wc
drwxr-xr-x - root supergroup 0 2016-01-05 17:18 /wc/input
接着开始上传
hadoop fs -put conf/*.xml hdfs://master.dragon.org:9000/wc/input/
在查看是否上传成功
drwxr-xr-x - root supergroup 0 2016-01-05 17:18 /wc
drwxr-xr-x - root supergroup 0 2016-01-05 17:23 /wc/input
-rw-r--r-- 1 root supergroup 7457 2016-01-05 17:23 /wc/input/capacity-scheduler.xml
-rw-r--r-- 1 root supergroup 444 2016-01-05 17:23 /wc/input/core-site.xml
-rw-r--r-- 1 root supergroup 327 2016-01-05 17:23 /wc/input/fair-scheduler.xml
-rw-r--r-- 1 root supergroup 4644 2016-01-05 17:23 /wc/input/hadoop-policy.xml
-rw-r--r-- 1 root supergroup 331 2016-01-05 17:23 /wc/input/hdfs-site.xml
-rw-r--r-- 1 root supergroup 2033 2016-01-05 17:23 /wc/input/mapred-queue-acls.xml
-rw-r--r-- 1 root supergroup 276 2016-01-05 17:23 /wc/input/mapred-site.xml
下载用get命令,模仿以上
12、运行一个例子
hadoop jar hadoop-examples-1.2.1.jar wordcount hdfs://master.dragon.org:9000/wc/input/ hdfs://master.dragon.org:9000/wc/output/
16/01/05 17:32:11 INFO util.NativeCodeLoader: Loaded the native-hadoop library
16/01/05 17:32:11 INFO input.FileInputFormat: Total input paths to process : 7
16/01/05 17:32:11 WARN snappy.LoadSnappy: Snappy native library not loaded
16/01/05 17:32:12 INFO mapred.JobClient: Running job: job_201601051530_0001
16/01/05 17:32:13 INFO mapred.JobClient: map 0% reduce 0%
16/01/05 17:33:31 INFO mapred.JobClient: map 28% reduce 0%
16/01/05 17:33:54 INFO mapred.JobClient: map 57% reduce 0%
16/01/05 17:34:05 INFO mapred.JobClient: map 57% reduce 19%
16/01/05 17:34:23 INFO mapred.JobClient: map 85% reduce 19%
16/01/05 17:34:33 INFO mapred.JobClient: map 100% reduce 19%
16/01/05 17:34:35 INFO mapred.JobClient: map 100% reduce 28%
16/01/05 17:34:37 INFO mapred.JobClient: map 100% reduce 100%
16/01/05 17:34:39 INFO mapred.JobClient: Job complete: job_201601051530_0001
16/01/05 17:34:39 INFO mapred.JobClient: Counters: 29
16/01/05 17:34:39 INFO mapred.JobClient: Job Counters
16/01/05 17:34:39 INFO mapred.JobClient: Launched reduce tasks=1
16/01/05 17:34:39 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=229608
16/01/05 17:34:39 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
16/01/05 17:34:39 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
16/01/05 17:34:39 INFO mapred.JobClient: Launched map tasks=7
16/01/05 17:34:39 INFO mapred.JobClient: Data-local map tasks=7
16/01/05 17:34:39 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=65560
16/01/05 17:34:39 INFO mapred.JobClient: File Output Format Counters
16/01/05 17:34:39 INFO mapred.JobClient: Bytes Written=6564
16/01/05 17:34:39 INFO mapred.JobClient: FileSystemCounters
16/01/05 17:34:39 INFO mapred.JobClient: FILE_BYTES_READ=15681
16/01/05 17:34:39 INFO mapred.JobClient: HDFS_BYTES_READ=15512
16/01/05 17:34:39 INFO mapred.JobClient: FILE_BYTES_WRITTEN=451968
16/01/05 17:34:39 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=6564
16/01/05 17:34:39 INFO mapred.JobClient: File Input Format Counters
16/01/05 17:34:39 INFO mapred.JobClient: Bytes Read=15512
16/01/05 17:34:39 INFO mapred.JobClient: Map-Reduce Framework
16/01/05 17:34:39 INFO mapred.JobClient: Map output materialized bytes=10651
16/01/05 17:34:39 INFO mapred.JobClient: Map input records=386
16/01/05 17:34:39 INFO mapred.JobClient: Reduce shuffle bytes=10651
16/01/05 17:34:39 INFO mapred.JobClient: Spilled Records=1196
16/01/05 17:34:39 INFO mapred.JobClient: Map output bytes=21309
16/01/05 17:34:39 INFO mapred.JobClient: Total committed heap usage (bytes)=867921920
16/01/05 17:34:39 INFO mapred.JobClient: CPU time spent (ms)=16610
16/01/05 17:34:39 INFO mapred.JobClient: Combine input records=1761
16/01/05 17:34:39 INFO mapred.JobClient: SPLIT_RAW_BYTES=847
16/01/05 17:34:39 INFO mapred.JobClient: Reduce input records=598
16/01/05 17:34:39 INFO mapred.JobClient: Reduce input groups=427
16/01/05 17:34:39 INFO mapred.JobClient: Combine output records=598
16/01/05 17:34:39 INFO mapred.JobClient: Physical memory (bytes) snapshot=1215692800
16/01/05 17:34:39 INFO mapred.JobClient: Reduce output records=427
16/01/05 17:34:39 INFO mapred.JobClient: Virtual memory (bytes) snapshot=5859864576
16/01/05 17:34:39 INFO mapred.JobClient: Map output records=1761
一个任务正在运行

运行完之后

查看part-r-00000文件
hadoop fs -cat hdfs://master.dragon.org:9000/wc/output/part-r-00000
"*" 10
"alice,bob 10
' 2
'(i.e. 2
'*', 2
'default' 2
(maximum-system-jobs 2
* 2
, 2
--> 14
-1 1
100 1
25% 1
25. 1
33% 1
4 1
50% 1
<!-- 14
</allocations> 1
</configuration> 6
</description> 19
</property> 34
</value> 2
<?xml 7
<?xml-stylesheet 5
<allocations> 1
<configuration> 6
<description> 4
<description>ACL 10
<description>If 2
<description>Maximum 1
<description>Number 1
<description>Percentage 1
<description>The 10
<name>dfs.permissions</name> 1
<name>dfs.replication</name> 1
<name>fs.default.name</name> 1
<name>hadoop.tmp.dir</name> 1
<name>mapred.capacity-scheduler.default-init-accept-jobs-factor</name> 1
<name>mapred.capacity-scheduler.default-maximum-active-tasks-per-queue</name> 1
<name>mapred.capacity-scheduler.default-maximum-active-tasks-per-user</name> 1
<name>mapred.capacity-scheduler.default-minimum-user-limit-percent</name> 1
<name>mapred.capacity-scheduler.default-supports-priority</name> 1
<name>mapred.capacity-scheduler.default-user-limit-factor</name> 1
<name>mapred.capacity-scheduler.init-poll-interval</name> 1
<name>mapred.capacity-scheduler.init-worker-threads</name> 1
<name>mapred.capacity-scheduler.maximum-system-jobs</name> 1
<name>mapred.capacity-scheduler.queue.default.capacity</name> 1
<name>mapred.capacity-scheduler.queue.default.init-accept-jobs-factor</name> 1
<name>mapred.capacity-scheduler.queue.default.maximum-capacity</name> 1
<name>mapred.capacity-scheduler.queue.default.maximum-initialized-active-tasks-per-user</name> 1
<name>mapred.capacity-scheduler.queue.default.maximum-initialized-active-tasks</name> 1
<name>mapred.capacity-scheduler.queue.default.minimum-user-limit-percent</name> 1
<name>mapred.capacity-scheduler.queue.default.supports-priority</name> 1
<name>mapred.capacity-scheduler.queue.default.user-limit-factor</name> 1
<name>mapred.job.tracker</name> 1
<name>mapred.queue.default.acl-administer-jobs</name> 1
<name>mapred.queue.default.acl-submit-job</name> 1
<name>security.admin.operations.protocol.acl</name> 1
<name>security.client.datanode.protocol.acl</name> 1
<name>security.client.protocol.acl</name> 1
<name>security.datanode.protocol.acl</name> 1
<name>security.inter.datanode.protocol.acl</name> 1
<name>security.inter.tracker.protocol.acl</name> 1
<name>security.job.submission.protocol.acl</name> 1
<name>security.namenode.protocol.acl</name> 1
<name>security.refresh.policy.protocol.acl</name> 1
<name>security.task.umbilical.protocol.acl</name> 1
<property> 34
<value> 2
<value>*</value> 10
<value>-1</value> 1
<value>/opt/data/tmp</value> 1
<value>100000</value> 2
<value>100</value> 3
<value>10</value> 2
<value>1</value> 3
<value>200000</value> 2
<value>3000</value> 1
<value>5000</value> 1
<value>5</value> 1
<value>false</value> 3
<value>hdfs://master.dragon.org:9000</value> 1
<value>master.dragon.org:9001</value> 1
A 11
ACL 13
AdminOperationsProtocol, 1
By 1
Capacity 2
CapacityScheduler. 1
ClientDatanodeProtocol, 1
ClientProtocol, 1
Comma 2
DatanodeProtocol, 1
Default 1
DistributedFileSystem. 1
Each 1
Fair 2
For 13
Hadoop. 1
If 9
Initialization 2
InterDatanodeProtocol, 1
InterTrackerProtocol, 1
Irrespective 2
It 2
Its 1
Job 1
JobSubmissionProtocol, 1
JobTracker. 1
Map/Reduce 2
NamenodeProtocol, 1
Once 4
One 1
Put 4
RefreshAuthorizationPolicyProtocol, 1
Scheduler 1
Scheduler. 1
So 1
TaskUmbilicalProtocol, 1
The 29
This 6
With 1
You 1
a 49
above 2
absence 1
absolute 1
accepted 2
accordingly. 1
account 2
acls 1
acquire 1
across 4
added 1
administrators 2
affected. 1
all 21
allocated 1
allocations 1
allow 1
allowed 6
allowed.</description> 10
also 1
amount 2
and 32
any 2
applied 1
appropriate 1
are 21
as, 1
assigned. 1
at 4
authorization 2
available 1
based 1
be 20
being 1
between 1
beyond 1
blank. 12
block 1
by 28
can 18
cannot 1
capacity 8
capacity. 1
certain 2
change. 1
client-to-datanode 1
clients 1
cluster 6
cluster's 1
cluster, 1
cluster. 2
code 1
comma-separated 10
commands 2
communciate 1
communicate 4
competition 1
complete 1
concurrently, 1
concurrently. 5
config 1
configuration 6
configuration, 2
configuration. 1
configure 1
configured 3
consume 1
contains 1
convention,such 1
could 2
curtail 1
datanodes 1
decisions 1
decisions. 1
default 7
default, 1
default. 1
defines 1
depends 1
details, 1
determine 3
dfsadmin 1
disk. 4
do 4
documentation 2
don't 1
e.g. 12
enabled 2
enforces 1
equal 3
etc. 1
example, 1
exceed 4
excess 1
explained 1
file 3
file. 5
follow 1
for 24
format 1
former 1
from 1
generation 1
get 2
given 2
greater 2
group 24
group1,group2. 2
guarantees 1
have 3
his/her 1
how 1
href="configuration.xsl"?> 5
http://hadoop.apache.org/common/docs/r0.20.205.0/fair_scheduler.html. 1
if 4
implies 2
important 1
imposed. 1
in 27
in-effect. 1
includes 1
increase 1
initialize 2
initialize. 1
initialized 4
initialized, 1
inter-datanode 1
into 2
irrespective 1
is 39
it 2
its 1
job 11
job's 1
job, 1
jobs 23
jobs, 1
jobs. 3
jobtracker 1
jobtracker. 1
kill 1
large 1
latter 1
lead 1
lesser 1
limit 8
limit. 1
limited 1
limits 1
list 26
long 1
manager 1
map 1
mapred.acls.enabled 2
mapred.capacity-scheduler.queue.<queue-name>.property-name. 1
mapreduce.cluster.administrators 2
max 2
maximum 5
maximum-capacity 3
means 13
mentioned 1
miliseconds 1
minimum 2
modify 1
more 6
mradmin 1
mradmins 1
much 1
multipe 2
multiple 2
namenode 1
namenode. 2
names 2
names. 10
naming 1
nature 1
no 8
nodes 2
note 1
number 14
occupying 1
of 67
on 9
only 3
operation. 2
operations 2
or 4
other 1
overrides 4
owner 1
parameters 2
parent 1
particular 2
per-user, 2
percentage 4
point 1
policy 1
poll 1
poller 1
pool 1
pre-emption, 1
priorities 2
priority 1
properties 2
property 11
protocol 3
provides 1
querying 1
queue 12
queue's 3
queue, 5
queue-capacity 1
queue-capacity) 2
queue. 6
queued 4
queues 6
queues. 3
racks 1
recovery. 1
reduce 1
refresh 2
related 1
resource 1
resources 2
resources. 3
running 1
sample 1
scheduler 2
scheduler. 2
scheduling 3
secondary 1
security 1
separated 14
set 7
setting 2
settings 1
single 5
site-specific 4
slots 2
slots. 1
so 1
space), 2
special 12
started 2
status 1
submission, 1
submit 4
submits 1
submitted 2
suppose 1
system 1
taken 2
task 1
tasks 3
tasks, 2
tasktracker. 1
tasktrackers 1
template 1
terms 1
than 5
that 4
the 81
them. 1
then 3
there 2
they 4
thing 1
third 1
this 16
thread 2
threads 2
time 2
time, 1
timestamp. 1
to 43
true, 2
true. 2
two 1
type="text/xsl" 5
updating 1
use 5
use. 1
used 15
user 40
user's 4
user1,user2 2
users 14
users, 1
users,wheel". 10
value 15
value. 2
values 1
various 1
vary 1
version="1.0"?> 7
via 3
view 1
which 17
who 3
will 8
with 5
worker 1
would 7
OK!!!