XML概述
XML Extensible Markup Language可扩展的标记语言是W3C组织在2000年发布的1.0版本
为什么需要这样的数据
现实生活中存在大量的数据,数据之间往往存在一定的关系,XML就是来存储这样的数据,能够保存和处理它们之间的关系
1、跨平台的数据
2、来写配置文件
XML文件的校验
1、通过浏览器
XML语法
1、文档申明
用来声明xml的基本属性,用来只会解析引擎如何去解析xml通常一个XML文档都把冷汗一个文档申明,在文档申明之前不能有任何的内容
version是必须存在的属性,表明当前文档所遵循的版本
encoding 属性 解决乱码的原理图 解决的办法就是通过encoding来指定浏览器的解码方式
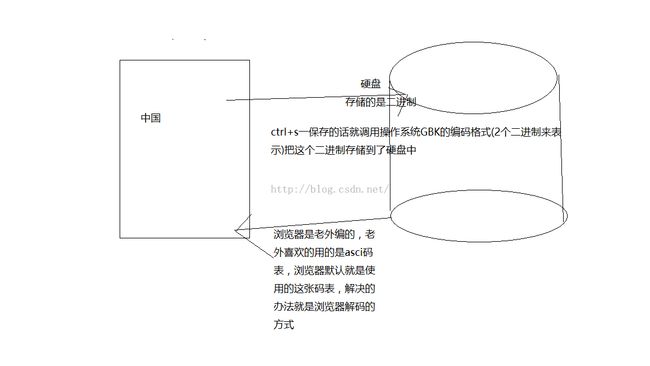
所以解决乱码的方法就是:编码(存储)的编码格式和解码的使用的码表是一样的
<? xml version=1.0 encoding="gbk"?>
standalone="yes" 用来指定当前文档是是否独立的文档,默认值是yes,表明当前文档不需要依赖其他文档,
注意:一个xml中必须有一个根节点
2、元素
元素:一个xml标签就是一个元素 一个标签分为开始标签和结束标签,在开始和结束之间的文本称为标签体,如果在开始标签和结束标签没有标签体或者没有子标签,这样就可以称为自闭标签<a/>,一个标签中可以包含任意多个子标签,一个xml只能包含一个根标签,对于xml标签中的所有的空格和换行,xml解析程序都会把它当作标签内容来处理
大部分的解析器都会在解析的时候进行trim();
注意:1、标签名字区分大小写
2、不能以数字和下划线开头
3、属性
一个标签可以有多个属性,每个属性都有自己的名称和值
<china captial="beijing">属性的名在定义时,要遵循和xml元素相同的命名规则,属性的值需要用单引号或双引号括起来
4、注释
注释可以出现在文档的任意位置,但是不能出现文档申明之前,注释不能嵌套注释
<!--zhushi--->
5、CDATA区/转义字符
CDATA区语法 <![CDATA[转义的内容]]>
转义字符:& -->&
< --><
> -->>
"" -->"
'' -->'
6、处理指令
PI processing instruction 处理指令用来指挥解析引擎如何解析xml文档内容
<?xml-stylesheet type="text/css" href="1.css" ?>
xml之前不能有空格
xml约束
在xml技术里,可以编写一个文档来约束xml文档的写法,被称之为xml文档的写法,被称之为xml约束,框架的设计者就是需要约束配置文件的写法。
xml约束的作用:
1、约束xml文档的写法
2、对xml进行校验
常见的xml约束技术:
XML DTD
XML Schema
DTD技术
<!ELEMENT 书架(书+)>
书架这个元素里可以包含书这个子元素,书这个子元素可以出现一次或者多次
<!ELEMENT 书(书名,作者,售价)>
元素书地下可以包含书名,作者,售价并且必须按这个元素
<!ELEMENT 书名(#PCDATA)>
元素书名可以包含标签体
<!ELEMENT 作者(#PCDATA)>
元素作者名可以包含标签体
<!ELEMENT 售价(#PCDATA)>
正确的写法,书架后边必须空一格
<!ELEMENT 书架 (书+)>
<!ELEMENT 书 (书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
元素售价可以包含标签体
注意的是浏览器用dtd进行校验的时候默认的dtd校验是关闭的,但是没有一种方式可以打开这种校验
解决办法:1、使用myeclipse本身就会做检验
2、使用javascript来进行校验,作用的原理打开浏览器的校验
注意:dtd文件必须保存为utf-8
dtd语法
1、在xml中如何引入dtd
外部引入:可以将dtd约束的内容写在外置的dtd文件中。dtd文件保存时必须用utf-8来编码,再在xml文件中写<!DOCTYPE 根元素名称 SYSTEM/PUBLIC "文件的位置">
如果写的是SYSTEM表明当前引入的dtd在当前的操作系统中,后面指定的文件位置是当前硬盘中的位置
如果写的是PUBLIC表明当前引入的dtd文件中在网络上的公共位置,后边要指明的是dtd文件的名字和dtd所在网络位置的URL地址
2、内部引入dtd
直接在xml文件中直接写dtd约束
<!DOCTYPE 根元素名称[
dtd约束
]>
XML的crud
利用java程序来crud:
解析xml的两种思路:
dom解析
sax解析
DOM解析方式:
node接口中提供了很多增删该查的结果,所有的文档树中的对象都实现过这个接口
优点:1、十分便于进行增删改查的操作2、只需解析一次DOM对象后可以重复使用此对象减少DOM对象的解析次数
缺点:1、第一次解析过程比较慢,需要将整个文档都解析完成后才能操作这个树
2、需要将整个树的内容都加载到内存,当文档超大时,这种解析方式会对内存的损耗非常严重
SAX解析方式:
两步:1、拿到sax解析的解析器
2、事件处理器
编程人员要做的就是每次出现事件的时候要添加事件处理机制
优点:不需要将整个文档都加载到内存,当解析到某一部分自动触发到对应的方法,处理的效率比较高,无论是多大的xml,理论上都能解析,
缺点:
1、每次的解析都只能处理一次,下次还想在处理的时候还要重新解析,
2、sax解析只能进行查询,不仅进行增删改
一般多使用sax 因为一般来说查询的操作比较多
sax解析的api
1、不需要导入任何的包 这种解析方式效率低下
2、需要导入一些市面上的解析包 这种解析方式比较高效 dom4j
dom4j
基于上述两种解析思想:
sun 公司的 j2se有自动的规范中,市面上一般使用的有dom4j使用dom方式来解析文档
非常优秀的java XMLAPI需要下载dom4j下载jar包
使用dom4j
1、导入开发包,通常只需要导入核心包