Unix环境高级编程
共享内存&文件映射
1、文件映射、内存映射(存储映射I/O)
P391
【定义】
存储映射I/O使一个磁盘文件与存储空间中的一个缓存相映射。于是当从缓存中取数据,就相当于读文件中的相应字节。与其类似,将数据存入缓存,则相应字节就自动地写入文件。这样,就可以在不使用read和write的情况下执行I/O。
【作用】
1. 直接用内存映射文件来访问磁盘上的数据文件,无需再进行文件的I/0操作.
2. 用来在多个进程之间共享数据.
【API】
1、将给定的文件映射到一个存储区域中
void * mmap(void addr, size_t len, int prot, int flag, int fd, off_t off);
//返回:若成功则为存储区的起始地址,若出错则为- 1addr:参数用于指定映射存储区的起始地址。通常将其设置为0,这表示由系统选择该映射区的起始地址。
len:是映射的字节数
prot:参数说明映射存储区的保护要求 (可读,可写,可执行,不可访问)
flag:参数影响映射存储区的多种属性
fd:指定要被映射文件的描述符
off:是要映射字节在文件中的起始位移量
保护要求:
PROT_READ|PROT_WRITE|PROT_EXEC|PROT_NONE2、修改在内存映像上的保护模式
int mprotect(const void *addr, size_t len, int prot);3、把映像的文件写入磁盘
int msync(const void *addr, size_t len, int flags);【signal】
SIGSEGV: 指示进程试图存取它不能存取的存储区。如果进程企图存数据到用mmap指定为只读的映射存储区,那么也产生此信号。
SIGBUS: 存取一个已不存在的存取映射区时产生
【多进程】
在fork之后,子进程继承存储映射区(因为子进程复制父进程地址空间,而存储映射区是该地址空间中的一部分),但是由于同样的理由,exec后的新程序则不继承此存储映射区。(关闭文件描述符也不影响存储映射区,磁盘文件的页高速缓存并不会因为进程的撤销而撤销,如果有足够的空闲内存,页高速缓存中的页将长期存在,使其它进程再使用该页时不再访问磁盘。)
【编程实例】
P394
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h> //close
#include <fcntl.h> //open O_RDWR
#include <sys/mman.h>
#define FILEPATH "/tmp/mmapped.bin"
#define NUMINTS (1000)
#define FILESIZE (NUMINTS * sizeof(int))
int main(int argc, char *argv[])
{
int i;
int fd;
int result;
int *map; /* mmapped array of int's */
/* Open a file for writing. * - Creating the file if it doesn't exist. * - Truncating it to 0 size if it already exists. (not really needed) * * Note: "O_WRONLY" mode is not sufficient when mmaping. */
fd = open(FILEPATH, O_RDWR | O_CREAT | O_TRUNC, (mode_t)0600);
if (fd == -1) {
perror("Error opening file for writing");
exit(EXIT_FAILURE);
}
/* Stretch the file size to the size of the (mmapped) array of ints */
result = lseek(fd, FILESIZE-1, SEEK_SET);
if (result == -1) {
close(fd);
perror("Error calling lseek() to 'stretch' the file");
exit(EXIT_FAILURE);
}
/* Something needs to be written at the end of the file to * have the file actually have the new size. * Just writing an empty string at the current file position will do. * * Note: * - The current position in the file is at the end of the stretched * file due to the call to lseek(). * - An empty string is actually a single '\0' character, so a zero-byte * will be written at the last byte of the file. */
//需要在文件末尾写入一个结束符,表示该文件有创建时的大小,不然后面的mmap会产生bus error 阅读P394
result = write(fd, "", 1);
if (result != 1) {
close(fd);
perror("Error writing last byte of the file");
exit(EXIT_FAILURE);
}
/* Now the file is ready to be mmapped. */
map = mmap(0, FILESIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (map == MAP_FAILED) {
close(fd);
perror("Error mmapping the file");
exit(EXIT_FAILURE);
}
/* Now write int's to the file as if it were memory (an array of ints). */
for (i = 1; i <=NUMINTS; ++i) {
map[i] = 2 * i;
}
/* Read the file int-by-int from the mmap */
for (i = 1; i <=NUMINTS; ++i) {
printf("%d: %d\n", i, map[i]);
}
/* Don't forget to free the mmapped memory */
if (munmap(map, FILESIZE) == -1) {
perror("Error un-mmapping the file");
/* Decide here whether to close(fd) and exit() or not. Depends... */
}
/* Un-mmaping doesn't close the file, so we still need to do that. */
close(fd);
return 0;
}【内存映射用于共享内存的IPC】
系统调用mmap()用于共享内存的两种方式:
(1)使用普通文件提供的内存映射:适用于任何进程之间;此时,需要打开或创建一个文件,然后再以MAP_SHARED调用mmap();
典型调用代码如下:
fd = open(name, flag, mode);
if(fd<0) ...
ptr = mmap(NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0); 通过mmap()实现共享内存的通信方式有许多特点和要注意的地方,我们将在范例中进行具体说明。
(2)使用特殊文件提供匿名内存映射:适用于具有亲缘关系的进程之间;
由于父子进程特殊的亲缘关系,在父进程中先调用mmap(),然后调用fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可,参见范例2。
参考:内存映射
2、共享内存
【定义】
允许两个或多个进程共享一给定的存储区。因为数据不需要在客户机和服务器之间复制,所以这是最快的一种IPC。使用共享存储的唯一窍门是多个进程之间对一给定存储区的同步存取。若服务器将数据放入共享存储区,则在服务器做完这一操作之前,客户机不应当去取这些数据。通常,信号量被用来实现对共享存储存取的同步。
【实现原理】
共享内存实现原理就是:将相同的物理页加入不同进程的地址空间。
将某个物理页加入进程的地址空间,要做的事情就是将物理页的物理地址填写进程页目录表内的表项和页表内的表项。
显然进程中要加入一块物理页,就必须对应一块线性空间,于是就要先申请一块线性空间,然后根据这块线性空间填写页目录表内的表项和页表内的表项。(这里可以说明为什么不同进程中的不同线性地址可以对应相同的物理地址)。
参考: Linux共享内存实例及文件映射编程及实现原理
【API】
1、获得一个共享存储标识符
int shmget(key_t key, size_t size, int flag);
//返回:成功返回共享存储标识符ID,出错返回-1创建一个新的IPC结构(服务器创建)
key: IPC_PRIVATE
flag: 指定IPC_CREATE
size: 共享存储段的长度,创建时段内内容为0,所有的内存分配操作都是以页为单位的
访问现存IPC结构(用户端)
key: 等于创建该队列时所指定的键,不能指定IPC_PRIVATE
flag: 不能指定IPC_CREATE
size: 指定为0
flag:
IPC_CREAT 如果共享内存不存在,则创建一个共享内存,否则打开操作。
IPC_EXCL 只有在共享内存不存在的时候,新的共享内存才建立,否则就产生错误。
IPC_ EXEL标志本身并没有太大的意义,但是和IPC_CREAT标志一起使用可以用来保证所得的对象是新建的,而不是打开已有的对象。
返回值
成功返回共享内存的标识符;不成功返回-1,errno储存错误原因。
EINVAL 参数size小于SHMMIN或大于SHMMAX。
EEXIST 预建立key所致的共享内存,但已经存在。
EIDRM 参数key所致的共享内存已经删除。
ENOSPC 超过了系统允许建立的共享内存的最大值(SHMALL )。
ENOENT 参数key所指的共享内存不存在,参数shmflg也未设IPC_CREAT位。
EACCES 没有权限。
ENOMEM 核心内存不足。
2、连接到共享内存的地址空间
把共享内存区对象映射到调用进程的地址空间
void *shmat(int shmid, void *addr, int flag) ;shmid:共享内存标识符
addr:指定共享内存出现在进程内存地址的什么位置,直接指定为NULL/0让内核自己决定一个合适的地址位置
flag:SHM_RDONLY:为只读模式,其他为读写模式
【多线程】
fork后子进程继承已连接的共享内存地址。exec后该子进程与已连接的共享内存地址自动脱离(detach)。进程结束后,已连接的共享内存地址会自动脱离(detach)
3、shmctl(共享内存管理)
int shmctl(int shmid, int cmd, struct shmid_ds *buf)
//成功:0 出错:-1,错误原因存于error中msqid: 共享内存标识符
cmd:
IPC_ STAT:得到共享内存的状态,把共享内存的shmid_ds结构复制到buf中
IPC_ SET: 改变共享内存的状态,把buf所指的shmid_ ds结构中的uid、gid、mode复制到共享内存的shmid_ds结构内
IPC_RMID:删除这片共享内存
buf: 共享内存管理结构体
【返回值】
EACCESS:参数cmd为IPC_STAT,确无权限读取该共享内存
EFAULT:参数buf指向无效的内存地址
EIDRM: 标识符为msqid的共享内存已被删除
EINVAL:无效的参数cmd或shmid
EPERM:参数cmd为IPC_ SET或IPC_RMID,却无足够的权限执行
4、脱接共享存储段,并不删除
int shmdt(const void *shmaddr)
//成功:0 出错:-1,【编程实例】
父子进程通信范例
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <error.h>
#define SIZE 1024
int main()
{
int shmid ;
char *shmaddr ;
struct shmid_ds buf ;
int flag = 0 ;
int pid ;
shmid = shmget(IPC_PRIVATE, SIZE, IPC_CREAT|0600 ) ;
if ( shmid < 0 ){
perror("get shm ipc_id error") ;
return -1 ;
}
pid = fork() ;
if ( pid == 0 )
{
shmaddr = (char *)shmat( shmid, NULL, 0 ) ;
if ( (int)shmaddr == -1 ){
perror("shmat addr error") ;
return -1 ;
}
strcpy( shmaddr, "Hi, I am child process!\n") ;
shmdt( shmaddr ) ;
return 0;
} else if ( pid > 0) {
sleep(3 ) ;
flag = shmctl( shmid, IPC_STAT, &buf) ;
if ( flag == -1 ){
perror("shmctl shm error") ;
return -1 ;
}
printf("shm_segsz =%d bytes\n", buf.shm_segsz ) ;
printf("parent pid=%d, shm_cpid = %d \n", getpid(), buf.shm_cpid ) ;
printf("chlid pid=%d, shm_lpid = %d \n",pid , buf.shm_lpid ) ;
shmaddr = (char *) shmat(shmid, NULL, 0 ) ;
if ( (int)shmaddr == -1 ){
perror("shmat addr error") ;
return -1 ;
}
printf("%s", shmaddr) ;
shmdt( shmaddr ) ;
shmctl(shmid, IPC_RMID, NULL) ;
}else{
perror("fork error") ;
shmctl(shmid, IPC_RMID, NULL) ;
}
return 0 ;
}参考:共享内存函数及其范例
信号机制
【头文件】
signal.h
【种类】
SIGSTOP:暂停进程的执行,让出CPU
SIGKILL:终止进程
SIGCHLD:进程Terminate或Stop的时候,SIGCHLD会发送给它的父进程。
SIGALRM: 当alarm设置的计时器超时时产生。
【API】
1、signal(参数1,参数2);
//SIGINT信号代表由InterruptKey产生,通常是CTRL +C 或者是DELETE 。发送给所有ForeGround Group的进程。
signal(SIGINT ,SIG_ING ); //SIG_ING忽略信号 SIG_DFL默认动作
int main()
{
signal(SIGINT, SIG_IGN); //ps -aux kill命令杀掉
while(1)
{
}
} 2、void ( * signal( int sig, void (* handler)( int ) ) )( int );
3、typedef void (* sigfunc)(int);
sigfunc signal(int sig, sigfunc handler);
//返回值:返回之前的信号处理程序的指针。
注意:void (* handler)( int )
【实例】
#include <stdio.h>
#include <signal.h>
#include <unistd.h> //fork
typedef void (* sigfunc)(int);
void sigint_pro(int arg)
{
if(arg == SIGINT)
{
printf("sig int get\n");
}
else if(arg == SIGCHLD)
{
printf("child die\n");
}
else
{
printf("no get\n");
}
}
int main()
{
sigfunc p = signal(SIGINT, sigint_pro);
p = signal(SIGCHLD, sigint_pro);
pid_t pid = fork();
if(pid < 0)
{
perror("fork");
return 1;
}
else if(pid == 0)
{
printf("child\n");
_exit(0);
}
else
{
sleep(3);
}
}4、 kill
int kill(pid_t pid, int signo); //将信号发送给进程(pid > 0)或进程组(pid == 0 or < 0)
//当signo=0时,用于检查某个进程是否存在,不存在时kill返回-1
int raise(int signo); //将信号发送给自己
5、alarm pause
unsigned int alarm(unsigned int seconds(秒)); //
signal(SIGALRM, sigint_pro); //必须在alarm设置定时器前设置处理函数
alarm(4);
printf("before pause\n");
pause();
printf("after pause\n"); alarm(1);
sleep(1);
signal(SIGALRM, sigint_pro); //此时的闹钟已经过去了6、sigaction
//检查或修改与指定信号相关联的处理动作 POSIX的信号接口
int sigaction(int signo, const struct sigaction *act, struct sigaction *oldact);
//信号集
typedef struct {
unsigned long sig[_NSIG_WORDS];
}sigset_t
struct sigaction{
void (*sa_handler)(int); //信号捕捉函数
sigset_t sa_mask; //信号集,在调用sa_handler之前,这一信号集要加进进程的信号屏蔽字中。仅当从sa_handler返回时再将进程的信号屏蔽字复位为原先值。
int sa_flag;
void (*sa_sigaction)(int,siginfo_t *,void *);
};sa_mask;
信号集,在调用sa_ handler之前,这一信号集要加进进程的信号屏蔽字中。仅当从sa_handler返回时再将进程的信 号屏蔽字复位为原先值。
sa_flag是一个选项,主要理解两个
SA_INTERRUPT 由此信号中断的系统调用不会自动重启
SA_RESTART 由此信号中断的系统调用会自动重启
SA_SIGINFO 提供附加信息,一个指向siginfo结构的指针以及一个指向进程上下文标识符的指针
7、sigsetjmp siglongjmp
#include <setjmp.h>
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int value);
int sigsetjmp(sigjmp_buf env, int savemask); //若直接调用则返回0,若从siglongjmp调用返回则返回非0值。
void siglongjmp(sigjmp_buf env, int val); 对sigsetjmp的说明:
sigsetjmp()会保存目前堆栈环境,然后将目前的地址作一个记号,
而在程序其他地方调用siglongjmp()时便会直接跳到这个记号位置,然后还原堆栈,继续程序的执行。
参数env为用来保存目前堆栈环境,一般声明为全局变量
参数savemask若为非0则代表搁置的信号集合也会一块保存
当sigsetjmp()返回0时代表已经做好记号上,若返回非0则代表由siglongjmp()跳转回来。
先看一个setjmp longjmp的实例
下面这个程序是个死循环,setjmp->setjmp_fun->longjmp->setjmp…….
jmp_buf jmpBuffer;
int jmp_ret = 1;
void setjmp_fun()
{
printf("in the setjmp fun\n");
longjmp(jmpBuffer,jmp_ret); //跳转到setjmp处
}
int main()
{
int ret = setjmp(jmpBuffer); //期望longjmp跳转的地方
if(ret == jmp_ret)
printf("return from setjmp_fun\n");
else if(ret == 0) //setjmp第一次从自身返回为0,从longjmp返回为jmp_ret
printf("direct return from setjmp\n");
setjmp_fun();
return 1;
}8、sigsuspend 重点P269 10-15 10-16 10-17
守护进程
【实例】
/* 一个daemon程序 */
#include<unistd.h>
#include<sys/types.h>
#include <sys/stat.h>
#define MAXFILE 65535
main()
{
pid_t pid;
int i, j = 0;
pid = fork();
if (pid < 0)
{
printf("error in fork\n");
exit(1);
}
else if (pid > 0)
exit(0); /* 父进程退出 */
/* 调用setsid,创建新会话 * 成为新会话的首进程,摆脱原会话的控制 * 成为新进程组组长,摆脱原进程组的控制 * 没有终端控制,摆脱原控制终端的控制 */
setsid();
/* 切换当前目录 */
chdir("/");
/* 设置文件权限掩码,不会屏蔽用户的任何操作 */
umask(0);
/* 关闭所有可能打开的不需要的文件 */
for (i = 0; i < MAXFILE; i++)
close(i);
/* *到现在为止,进程已经成为一个完全的daemon进程, *你可以在这里添加任何你要daemon做的事情,如: */
for (j = 0; j < 5; j++)
sleep(10);
}信号量
信号量函数由semget、semop、semctl三个函数组成
【API】
所需头文件:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>1、semget得到一个信号量集标识符或创建一个信号量集对象
int semget(key_t key, int nsems, int semflg)
//成功:返回信号量集的标识符 出错:-1,错误原因存于error中key
0(IPC_PRIVATE):会建立新信号量集对象
大于0的32位整数:视参数semflg来确定操作,通常要求此值来源于ftok返回的IPC键值
nsems
创建信号量集中信号量的个数,该参数只在创建信号量集时有效
msgflg
0:取信号量集标识符,若不存在则函数会报错
IPC_CREAT:当semflg&IPC_CREAT为真时,如果内核中不存在键值与key相等的信号量集,则新建一个信号量集;如果存在这样的信号量集,返回此信号量集的标识符
IPC_CREAT|IPC_EXCL:如果内核中不存在键值与key相等的信号量集,则新建一个消息队列;如果存在这样的信号量集则报错
error:
EACCESS:没有权限
EEXIST:信号量集已经存在,无法创建
EIDRM:信号量集已经删除
ENOENT:信号量集不存在,同时semflg没有设置IPC_CREAT标志
ENOMEM:没有足够的内存创建新的信号量集
ENOSPC:超出限制
如果用semget创建了一个新的信号量集对象时,则semid_ds结构成员变量的值设置如下:
sem_otime设置为0。
sem_ctime设置为当前时间。
msg_qbytes设成系统的限制值。
sem_nsems设置为nsems参数的数值。
semflg的读写权限写入sem_perm.mode中。
sem_perm结构的uid和cuid成员被设置成当前进程的有效用户ID,gid和cuid成员被设置成当前进程的有效组ID。2、semop(完成对信号量的P操作或V操作)
int semop(int semid, struct sembuf *sops, unsigned nsops)
成功:返回信号量集的标识符 出错:-1,错误原因存于error中nsops:进行操作信号量的个数,即sops结构变量的个数,需大于或等于1。最常见设置此值等于1,只完成对一个信号量的操作
sops:指向进行操作的信号量集结构体数组的首地址,此结构的具体说明如下:
struct sembuf {
short semnum; /*信号量集合中的信号量编号,0代表第1个信号量*/
short val;
/*若val>0进行V操作,信号量值加val,表示进程释放控制的资源 */
/*若val<0进行P操作,信号量值减val,若(semval-val)<0(semval为该信号量值),则调用进程阻塞,直到资源可用;若设置IPC_NOWAIT不会睡眠,进程直接返回EAGAIN错误*/
/*若val==0时阻塞等待,信号量为0,调用进程进入睡眠状态,直到信号值为0;若设置IPC_NOWAIT,进程不会睡眠,直接返回EAGAIN错误*/
short flag;
/*0 设置信号量的默认操作*/
/*IPC_NOWAIT设置信号量操作不等待*/
/*SEM_UNDO 选项会让内核记录一个与调用进程相关的UNDO记录,如果该进程崩溃,则根据这个进程的UNDO记录自动恢复相应信号量的计数值*/
};error:
E2BIG:一次对信号量个数的操作超过了系统限制
EACCESS:权限不够
EAGAIN:使用了IPC_NOWAIT,但操作不能继续进行
EFAULT:sops指向的地址无效
EIDRM:信号量集已经删除
EINTR:当睡眠时接收到其他信号
EINVAL:信号量集不存在,或者semid无效
ENOMEM:使用了SEM_UNDO,但无足够的内存创建所需的数据结构
ERANGE:信号量值超出范围
【P/V操作封装】
//semnum为信号量的序号
/***对信号量数组semnum编号的信号量做P操作***/
int P(int semid, int semnum)
{
struct sembuf sops = {semnum,-1, SEM_UNDO};
return (semop(semid,&sops,1));
}
/***对信号量数组semnum编号的信号量做V操作***/
int V(int semid, int semnum)
{
struct sembuf sops = {semnum,+1, SEM_UNDO};
return (semop(semid,&sops,1));
}sops为指向sembuf数组,定义所要进行的操作序列。下面是信号量操作举例。
struct sembuf sem_get={0,-1,IPC_NOWAIT}; /*将信号量对象中序号为0的信号量减1*/
struct sembuf sem_get={0,1,IPC_NOWAIT}; /*将信号量对象中序号为0的信号量加1*/
struct sembuf sem_get={0,0,0}; /*进程被阻塞,直到对应的信号量值为0*/flag一般为0,若flag包含IPC_ NOWAIT,则该操作为非阻塞操作。若flag包含SEM_ UNDO,则当进程退出的时候会还原该进程的信号量操作,这个标志在某些情况下是很有用的,比如某进程做了P操作得到资源,但还没来得及做V操作时就异常退出了,此时,其他进程就只能都阻塞在P操作上,于是造成了死锁。若采取SEM_UNDO标志,就可以避免因为进程异常退出而造成的死锁。
3、semctl (得到一个信号量集标识符或创建一个信号量集对象)
int semctl(int semid, int semnum, int cmd, union semun arg)semid 信号量集标识符
semnum 信号量集数组上的下标,表示某一个信号量
cmd 参考 信号量函数(semget、semop、semctl)及其范例
arg
union semun {
short val; /*SETVAL用的值*/
struct semid_ds* buf; /*IPC_STAT、IPC_SET用的semid_ds结构*/
unsigned short* array; /*SETALL、GETALL用的数组值*/
struct seminfo *buf; /*为控制IPC_INFO提供的缓存*/
} arg;
struct shmid_ds{
struct ipc_perm shm_perm; /* 操作权限*/
int shm_segsz; /*段的大小(以字节为单位)*/
time_t shm_atime; /*最后一个进程附加到该段的时间*/
time_t shm_dtime; /*最后一个进程离开该段的时间*/
time_t shm_ctime; /*最后一个进程修改该段的时间*/
unsigned short shm_cpid; /*创建该段进程的pid*/
unsigned short shm_lpid; /*在该段上操作的最后1个进程的pid*/
short shm_nattch; /*当前附加到该段的进程的个数*/
/*下面是私有的*/
unsigned short shm_npages; /*段的大小(以页为单位)*/
unsigned long *shm_pages; /*指向frames->SHMMAX的指针数组*/
struct vm_area_struct *attaches; /*对共享段的描述*/
};【实例】
int main(int argc, char **argv)
{
int key ;
int semid,ret;
union semun arg;
struct sembuf semop;
int flag ;
//系统建立IPC通讯(如消息队列、共享内存时)必须指定一个ID值。该id值通过ftok函数得到
key = ftok("/tmp", 0x66 ) ;
if ( key < 0 )
{
perror("ftok key error") ;
return -1 ;
}
/***本程序创建了三个信号量,实际使用时只用了一个0号信号量***/
semid = semget(key,3,IPC_CREAT|0600);
if (semid == -1)
{
perror("create semget error");
return ;
}
if ( argc == 1 )
{
arg.val = 1;
/***对0号信号量设置初始值***/
ret =semctl(semid,0,SETVAL,arg);
if (ret < 0 )
{
perror("ctl sem error");
semctl(semid,0,IPC_RMID,arg);
return -1 ;
}
}
/***取0号信号量的值***/
ret =semctl(semid,0,GETVAL,arg);
printf("after semctl setval sem[0].val =[%d]\n",ret);
system("date") ;
printf("P operate begin\n") ;
flag = P(semid,0) ;
if ( flag )
{
perror("P operate error") ;
return -1 ;
}
printf("P operate end\n") ;
ret =semctl(semid,0,GETVAL,arg);
printf("after P sem[0].val=[%d]\n",ret);
system("date") ;
if ( argc == 1 )
{
sleep(120) ;
}
printf("V operate begin\n") ;
if (V(semid, 0) < 0)
{
perror("V operate error") ;
return -1 ;
}
printf("V operate end\n") ;
ret =semctl(semid,0,GETVAL,arg);
printf("after V sem[0].val=%d\n",ret);
system("date") ;
if ( argc >1 )
{
semctl(semid,0,IPC_RMID,arg);
}
return 0 ;
}多路复用IO 多路I/O就绪通知方法
select/poll/epoll
【API】
epoll只有epoll_create,epoll_ctl,epoll_wait 3个系统调用。
1.创建epoll句柄
int epoll_create(int size);
//返回创建的句柄创建一个epoll的句柄。自从linux2.6.8之后,size参数是被忽略的。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭创建的fd,否则可能导致fd被耗尽。
- 事件注册函数
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);它不同于select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型。
epfd: epoll_create()的返回值。
op: 第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
fd: 需要监听的fd。
event: 监听的事件,告诉内核需要监听什么事件,struct epoll_event结构如下:
//感兴趣的事件和被触发的事件
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data { //联合体
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t; events可以是以下几个宏的集合:
EPOLLIN : 表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT: 表示对应的文件描述符可以写;
EPOLLPRI: 表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR: 表示对应的文件描述符发生错误;
EPOLLHUP: 表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
3、收集监控事件
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
//收集在epoll监控的事件中已经发送的事件epfd: epoll_create()的返回值。
events: 分配好的epoll_event结构体数组epoll将会把发生的事件赋值到events数组中(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)
maxevents:告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size
timeout: 是超时时间(毫秒,0会立即返回,-1永久阻塞)。如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时。
【实例】
epoll程序框架
for( ; ; )
{
//查询所有的网络接口,看哪一个可以读,哪一个可以写
//events是一个epoll_event*的指针,当epoll_wait这个函数操作成功之后,epoll_events里面将储存所有的读写事件
//max_events=20是当前需要监听的所有socket句柄数
nfds = epoll_wait(epfd,events,20,500);
for(i=0;i<nfds;++i)
{
if(events[i].data.fd==listenfd) //有新的连接
{
connfd = accept(listenfd,(sockaddr *)&clientaddr, &clilen); //accept这个连接
ev.data.fd=connfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev); //将新的fd添加到epoll的监听队列中
}
else if( events[i].events&EPOLLIN ) //接收到数据,读socket
{
n = read(sockfd, line, MAXLINE)) < 0 //读
ev.data.ptr = md; //md为自定义类型,添加数据
ev.events=EPOLLOUT|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);//修改标识符,等待下一个循环时发送数据,异步处理的精髓
}
else if(events[i].events&EPOLLOUT) //有数据待发送,写socket
{
struct myepoll_data* md = (myepoll_data*)events[i].data.ptr; //取数据
sockfd = md->fd;
send( sockfd, md->ptr, strlen((char*)md->ptr), 0 ); //发送数据
ev.data.fd=sockfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev); //修改标识符,等待下一个循环时接收数据
}
else
{
//其他的处理
}
}//for
}//for
epoll_fd = epoll_create(0);
if (epoll_fd == -1)
{
perror ("epoll_create");
abort ();
}
event.data.fd = socket_fd;
event.events = EPOLLIN | EPOLLET; //读入,边缘触发方式
s = epoll_ctl(epoll_fd, EPOLL_CTL_ADD, socket_fd, &event);
if (s == -1)
{
perror ("epoll_ctl");
abort ();
}
/* Buffer where events are returned */
event_buffer = calloc (MAXEVENTS, sizeof(event));
n = epoll_wait (epoll_fd, event_buffer, MAXEVENTS, -1);epoll工作原理
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
Epoll的2种工作方式-水平触发(LT)和边缘触发(ET)
假如有这样一个例子:
1. 我们已经把一个用来从管道中读取数据的文件句柄(RFD)添加到epoll描述符
2. 这个时候从管道的另一端被写入了2KB的数据
3. 调用epoll_wait(2),并且它会返回RFD,说明它已经准备好读取操作
4. 然后我们读取了1KB的数据
5. 调用epoll_wait(2)……
Edge Triggered 工作模式:
如果我们在第1步将RFD添加到epoll描述符的时候使用了EPOLLET标志,那么在第5步调用epoll_wait(2)之后将有可能会挂起,因为剩余的数据还存在于文件的输入缓冲区内,而且数据发出端还在等待一个针对已经发出数据的反馈信息。只有在监视的文件句柄上发生了某个事件的时候 ET 工作模式才会汇报事件。因此在第5步的时候,调用者可能会放弃等待仍在存在于文件输入缓冲区内的剩余数据。在上面的例子中,会有一个事件产生在RFD句柄上,因为在第2步执行了一个写操作,然后,事件将会在第3步被销毁。因为第4步的读取操作没有读空文件输入缓冲区内的数据,因此我们在第5步调用 epoll_wait(2)完成后,是否挂起是不确定的。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。最好以下面的方式调用ET模式的epoll接口,在后面会介绍避免可能的缺陷。
i 基于非阻塞文件句柄
ii 只有当read(2)或者write(2)返回EAGAIN时才需要挂起,等待。但这并不是说每次read()时都需要循环读,直到读到产生一个EAGAIN才认为此次事件处理完成,当read()返回的读到的数据长度小于请求的数据长度时,就可以确定此时缓冲中已没有数据了,也就可以认为此事读事件已处理完成。
Level Triggered 工作模式
相反的,以LT方式调用epoll接口的时候,它就相当于一个速度比较快的poll(2),并且无论后面的数据是否被使用,因此他们具有同样的职能。因为即使使用ET模式的epoll,在收到多个chunk的数据的时候仍然会产生多个事件。调用者可以设定EPOLLONESHOT标志,在 epoll_wait(2)收到事件后epoll会与事件关联的文件句柄从epoll描述符中禁止掉。因此当EPOLLONESHOT设定后,使用带有 EPOLL_CTL_MOD标志的epoll_ctl(2)处理文件句柄就成为调用者必须作的事情。
LT(level triggered)是epoll缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你 的,所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表.
ET (edge-triggered)是高速工作方式,只支持no-block socket,它效率要比LT更高。ET与LT的区别在于,当一个新的事件到来时,ET模式下当然可以从epoll_wait调用中获取到这个事件,可是如果这次没有把这个事件对应的套接字缓冲区处理完,在这个套接字中没有新的事件再次到来时,在ET模式下是无法再次从epoll_wait调用中获取这个事件的。而LT模式正好相反,只要一个事件对应的套接字缓冲区还有数据,就总能从epoll_wait中获取这个事件。
因此,LT模式下开发基于epoll的应用要简单些,不太容易出错。而在ET模式下事件发生时,如果没有彻底地将缓冲区数据处理完,则会导致缓冲区中的用户请求得不到响应。
参考:epoll详解
线程属性
APUE P314
1、分离线程
线程的分离状态决定一个线程以什么样的方式来终止自己。
线程的默认属性,一般是非分离状态,这种情况下,原有的线程等待创建的线程结束。只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。而分离线程没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。
int pthread_detach(pthread_t thread);
//让子线程处于分离状态2、栈属性
#include<pthread.h>
int pthread_attr_getstacksize(const pthtead_attr_t *restrict attr,void **restrict stackaddr,size_t *restrict stacksize)
int pthread_attr_setstacksize(const pthread_attr_t *attr,void *stackaddr,size_t *stacksize)同步异步阻塞非阻塞IO
【概念】
1. 同步阻塞I/O: 用户进程进行I/O操作,一直阻塞到I/O操作完成为止。
2. 同步非阻塞I/O: 用户程序可以通过设置文件描述符的属性O_NONBLOCK,I/O操作可以立即返回,但是并不保证I/O操作成功。
3. 异步方式: 当你用异步方式调用一个function的时候,这个方法会马上返回,事实上多数情况下这种function call只是向某个任务执行体提交一个任务而已。 而你的主thread可以继续执行其他的事情, 不必等待(阻塞), 而当那个任务执行体执行完你提交的这个任务后,它会通过某种方法callback给你的thread, 告诉你,你的这个任务已经完成。
1.read/write:
对于read操作来说,它是同步的。也就是说只有当申请读的内容真正存放到buffer中后(user mode的buffer),read函数才返回。在此期间,它会因为等待IO完成而被阻塞。研究过源码的朋友应该知道,这个阻塞发生在两个地方:一是read操作刚刚发起,kernel会检查其它进程的need_sched标志,如果有其它进程需要调度,主动阻塞read操作,这个时候其实I/O操作还没有发起。二是I/O操作发起后,调用lock_page对已经加锁的页面申请锁,这时由于页面已经加锁,所以加锁操作被阻塞,从而read操作阻塞,直到I/O操作完成后页面被解锁,read操作继续执行。所以说read是同步的,其阻塞的原因如上。
对于write操作通常是异步的。因为linux中有page cache机制,所有的写操作实际上是把文件对应的page cache中的相应页设置为dirty,然后write操作返回。这个时候对文件的修改并没有真正写到磁盘上去。所以说write是异步的,这种方式下write不会被阻塞。如果设置了O_SYNC标志的文件,write操作再返回前会把修改的页flush到磁盘上去,发起真正的I/O请求,这种模式下会阻塞。
2.Direct I/O
linux支持Direct I/O, 以O_DIRCET标志打开的文件,在read和write的时候会绕开page cache,直接使用user mode的buffer做为I/O操作的buffer。这种情况下的read和write**直接发起I/O操作,都是同步的,并会被阻塞**。
3.AIO
目前大多数的linux用的AIO是基于2.4内核中的patch,使用librt库中的接口。这种方式实现很简单,就是一个父进程clone出子进程帮其做I/O,完成后通过signal或者callback通知父进程。用户看来是AIO,实质还是SIO。linux kernel中AIO的实现概念类似,只不过是以一组kernel thread去做的。这些kernel thread做I/O的时候使用的是和Direct I/O相同的方式。
4.mmap()
抛开它中讲vm_area和page cache映射在一起的机制不说。真正发起I/O时和read、write使用的是相同的机制,同步阻塞。
【同步阻塞 I/O】
I/O 密集型进程,所执行的 I/O 操作比执行的处理操作更多。
CPU密集型进程,所执行的处理操作比 I/O 操作更多。
最常用的一个模型是同步阻塞 I/O 模型。在这个模型中,用户空间的应用程序执行一个系统调用,这会导致应用程序阻塞。这意味着应用程序会一直阻塞,直到系统调用完成为止(数据传输完成或发生错误)。调用应用程序处于一种不再消费 CPU而只是简单等待响应的状态,因此从处理的角度来看,这是非常有效的。
图 2 给出了传统的阻塞 I/O 模型,这也是目前应用程序中最为常用的一种模型。其行为非常容易理解,其用法对于典型的应用程序来说都非常有效。
在调用 read 系统调用时,应用程序会阻塞并对内核进行上下文切换。然后会触发读操作,当响应返回时(从我们正在从中读取的设备中返回),数据就被移动到用户空间的缓冲区中。然后应用程序就会解除阻塞(read 调用返回)。
从应用程序的角度来说,read 调用会延续很长时间。实际上,在内核执行读操作和其他工作时,应用程序的确会被阻塞
【同步非阻塞 I/O】
同步阻塞 I/O 的一种效率稍低的变种是同步非阻塞 I/O。在这种模型中,设备是以非阻塞的形式打开的。这意味着 I/O 操作不会立即完成,read 操作可能会返回一个错误代码,说明这个命令不能立即满足(EAGAIN 或 EWOULDBLOCK),如图 3 所示。
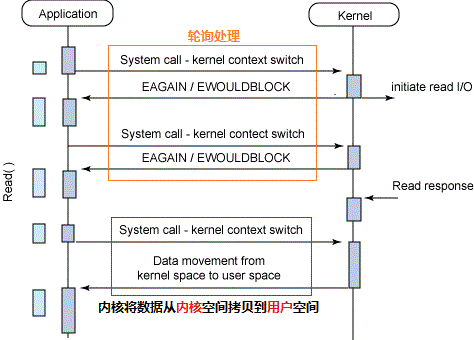
非阻塞的实现是 I/O 命令可能并不会立即满足,需要应用程序调用许多次来等待操作完成(轮询)。这可能效率不高,因为在很多情况下,当内核执行这个命令时,应用程序必须要进行忙碌等待,直到数据可用为止,或者试图执行其他工作。正如图 3 所示的一样,这个方法可以引入 I/O 操作的延时,因为数据在内核中变为可用到用户调用 read 返回数据之间存在一定的间隔,这会导致整体数据吞吐量的降低。
【异步阻塞 I/O】
另外一个阻塞解决方案是带有阻塞通知的非阻塞 I/O。在这种模型中,配置非阻塞 I/O,然后使用阻塞 select 系统调用来确定一个 I/O 描述符何时有操作。使 select 调用非常有趣的是它可以用来为多个描述符提供通知,而不仅仅为一个描述符提供通知。对于每个提示符来说,我们可以请求这个描述符可以写数据、有读数据可用以及是否发生错误的通知。
【异步非阻塞 I/O(AIO)】
异步非阻塞 I/O 模型是一种处理与 I/O 重叠进行的模型。读请求会立即返回,说明 read 请求已经成功发起了。在后台完成读操作时,应用程序然后会执行其他处理操作。当 read 的响应到达时,就会产生一个信号或执行一个基于线程的回调函数来完成这次 I/O 处理过程。
在一个进程中为了执行多个 I/O 请求而对计算操作和 I/O 处理进行重叠处理的能力利用了处理速度与 I/O 速度之间的差异。当一个或多个 I/O 请求挂起时,CPU 可以执行其他任务;或者更为常见的是,在发起其他 I/O 的同时对已经完成的 I/O 进行操作。
AIO异步非阻塞IO
在异步非阻塞 I/O 中,我们可以同时发起多个传输操作。这需要每个传输操作都有惟一的上下文,这样我们才能在它们完成时区分到底是哪个传输操作完成了。在 AIO 中,这是一个 aiocb(AIO I/O Control Block)结构。这个结构包含了有关传输的所有信息,包括为数据准备的用户缓冲区。在产生 I/O (称为完成)通知时,aiocb 结构就被用来惟一标识所完成的 I/O 操作。这个 API 的展示显示了如何使用它。
【API】
aio_read 请求异步读操作
aio_write 请求异步写操作
aio_error 检查异步请求的状态
aio_return 获得完成的异步请求的返回状态
aio_suspend 挂起调用进程,直到一个或多个异步请求已经完成(或失败)
aio_cancel 取消异步 I/O 请求
lio_listio 发起一系列 I/O 操作
aiocb 结构中相关的域
struct aiocb {
int aio_fildes; // File Descriptor
int aio_lio_opcode; // Valid only for lio_listio (r/w/nop)
volatile void *aio_buf; // Data Buffer
size_t aio_nbytes; // Number of Bytes in Data Buffer
struct sigevent aio_sigevent; // Notification Structure I/O操作完成时应该执行的操作
/* Internal fields */
...
};sigevent 结构告诉 AIO 在 I/O 操作完成时应该执行什么操作。
1、aio_read
int aio_read( struct aiocb *aiocbp );
//如果执行成功,返回值为0;如果出现错误,返回值为-1,并设置errno的值请求对一个有效的文件描述符进行异步读操作。这个文件描述符可以表示一个文件、套接字甚至管道。
aio_read 函数在请求进行排队之后会立即返回。
3、aio_return
ssize_t aio_return( struct aiocb *aiocbp );异步 I/O和标准块 I/O之间的另外一个区别是我们不能立即访问这个函数的返回状态,因为我们并没有阻塞在 read 调用上。在标准的 read 调用中,返回状态是在该函数返回时提供的。但是在异步 I/O 中,我们要使用aio_return函数。
只有在 aio_ error 调用确定请求已经完成(可能成功,也可能发生了错误)之后,才会调用这个函数。aio_return 的返回值就等价于同步情况中 read 或 write 系统调用的返回值(所传输的字节数,如果发生错误,返回值就为 -1)。
【AIO通知】
应用程序需要定义信号处理程序,在产生指定的信号时就会调用这个处理程序。应用程序然后配置一个异步请求将在请求完成时产生一个信号。作为信号上下文的一部分,特定的 aiocb 请求被提供用来记录多个可能会出现的请求。
参考:AIO 简介