【Redis源码剖析】 - Redis数据类型之有序集合zset
原创作品,转载请标明:http://blog.csdn.net/Xiejingfa/article/details/51231967
这周事情比较多,原本计划每周写两篇文章的任务看来是完不成了。今天为大家带来有序集合zset的源码分析。
Redis中的zset主要支持以下命令:
- zadd、zincrby
- zrem、zremrangebyrank、zremrangebyscore、zremrangebyrank
- zrange、zrevrange、zrangebyscore、zrevrangebyscore、zrangebylex、zrevrangebylex
- zcount、zcard、zscore、zrank、zrevrank
- zunionstore、zinterstore
zset的源码主要涉及redis.h和t_zset.c两个文件。
1、跳跃表skiplist
Redis中的zset在实现时用到了跳跃表skiplist这种数据结构。skiplist是一种基于并联链表的、随机化的数据结构,由 William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中首次提出,可以实现平均复杂度为O(longN)的插入、删除和查找操作。
下面我们主要来介绍跳跃表在Redis中的实现和应用。关于跳跃表的原理和代码实现,我在网上找到一篇不错的文章,如果你还不了解跳跃表相关知识,可以先看看这篇文章:skiplist 跳跃表详解及其编程实现。
1.1、跳跃表的存储结构
Redis中的跳跃表实现和William Pugh在《Skip Lists: A Probabilistic Alternative to Balanced Trees》一文中描述的跳跃表基本一致,主要有以下三点进行了修改:
- Redis中的跳跃表允许有重复的分值score,以支持有序集合中多个元素可以有相同的分值score。
- 节点的比较操作不仅仅比较其分值score,同时还要比较其关联的元素值value。
- 每个节点还有一个后退指针(相当于双向链表中的prev指针),通个该指针,我们可以从表尾向表头遍历列表。这个属性可以实现zset的一些逆向操作命令如zrevrange。
跳跃表的节点定义在redis.h头文件中:
/* 跳跃表节点定义 */
typedef struct zskiplistNode {
// 存放的元素值
robj *obj;
// 节点分值,排序的依据
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨越的节点数量
unsigned int span;
} level[];
} zskiplistNode;跳跃表的定义如下:
/* 跳跃表定义 */
typedef struct zskiplist {
// 跳跃表的头结点和尾节点
struct zskiplistNode *header, *tail;
// 节点数量
unsigned long length;
// 目前跳跃表的最大层数
int level;
} zskiplist;跳跃表主要操作实现在t_zset.c中,主要包括以下操作:
// 创建一个层数为level的跳跃表节点
zskiplistNode *zslCreateNode(int level, double score, robj *obj);
// 创建一个跳跃表
zskiplist *zslCreate(void);
// 释放指定的跳跃表节点
void zslFreeNode(zskiplistNode *node);
// 释放跳跃表
void zslFree(zskiplist *zsl);
// 往跳跃表中插入一个新节点
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj);
// 删除节点函数,供zslDelete、zslDeleteByScore和zslDeleteByRank函数调用
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update);
// 从从跳跃表中删除一个分值score、保存对象为obj的节点
int zslDelete(zskiplist *zsl, double score, robj *obj);
// 如果range给定的数值范围包含在跳跃表的分值范围则返回1,否则返回0
int zslIsInRange(zskiplist *zsl, zrangespec *range);
// 返回跳跃表中第一个分值score在range指定范围的节点
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range);
// 返回跳跃表中最后一个分值score在range指定范围的节点
zskiplistNode *zslLastInRange(zskiplist *zsl, zrangespec *range);
// 在跳跃表中删除所有分值在给定范围range内的节点
unsigned long zslDeleteRangeByScore(zskiplist *zsl, zrangespec *range, dict *dict);
// 删除成员对象值在指定字典序范围的节点
unsigned long zslDeleteRangeByLex(zskiplist *zsl, zlexrangespec *range, dict *dict);
// 在跳跃表中删除给定排序范围的节点
unsigned long zslDeleteRangeByRank(zskiplist *zsl, unsigned int start, unsigned int end, dict *dict);
// 返回指定元素在跳跃表中的排位
unsigned long zslGetRank(zskiplist *zsl, double score, robj *o);
// 返回指定排位上的节点
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank)接下来我们举两个列子,让大家能更好地理解跳跃表的存储结构。
(1)、创建一个空的跳跃表
zslCreate用来创建并初始化一个新的跳跃表,一个空的跳跃表如下所示:
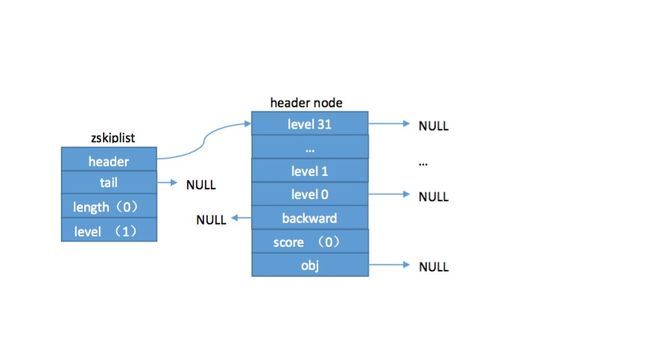
其中level0 - level31是一个长度为32(由ZSKIPLIST_MAXLEVEL定义,值为32)的zskiplistLevel 结构体数组,zskiplistLevel结构体包含span和forward两个成员,这里为了方便展示忽略了span。
(2)、插入操作
跳跃表中的元素是按分值score排序的,如果我们往跳跃表中插入了a、b、c、d四个元素,对应的分值为3、5、7、9,则对应的跳跃表结构如下所示:

2、zset编码方式
有序集合zset主要有两种编码方式:REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_SKIPLIST。ziplist可以表示较小的有序集合, skiplist表示任意大小的有序集合。
前面我们介绍List数据类型时,List以ziplist作为默认编码。但在zset中则采取不同的策略,zset会根据zadd命令添加的第一个元素的长度大小来选择创建编码方式。具体而言:如果满足下面两个条件之一则使用ziplist编码方式:
- Redis中server.zset_max_ziplist_entries的值不为0。
- 第一个元素值的长度小于server.zset_max_ziplist_value(默认值为64)。
反之,则使用skiplist编码方式。
该过程实现在在zaddGenericCommand函数中,这里只截取部分代码用作展示:
...
/* Lookup the key and create the sorted set if does not exist. */
// 取出有序集合对象
zobj = lookupKeyWrite(c->db,key);
// 如果key指定的有序集合对象不存在则创建一个
if (zobj == NULL) {
// server.zset_max_ziplist_entries的默认值为128
// server.zset_max_ziplist_value的默认值为64
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[3]->ptr))
{
zobj = createZsetObject();
} else {
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
}
// 如果key指定的对象存在,还需要进一步检查其类型是否是zset
else {
if (zobj->type != REDIS_ZSET) {
addReply(c,shared.wrongtypeerr);
goto cleanup;
}
}
...如果zset当前使用REDIS_ENCODING_ZIPLIST编码,当满足下面两个条件之一时会转换为REDIS_ENCODING_SKIPLIST编码:
- 当待添加的新字符串长度超过server.zset_max_ziplist_value (默认值为64)时。
- ziplist中保存的节点数量超过server.zset_max_ziplist_entries(默认值为128)时。
两种编码的转换由zsetConvert函数实现。
2.1、ziplist编码的zset存储结构
在zset中,每个元素包含两个成员:元素值、分值。如果使用ziplist编码如何来保存这两个成员呢?Redis用ziplist中相邻的两个节点来存放zset中的一个元素,这两个节点分别保存元素值和分值。为了方便描述,我们称这两个为“元素值节点”和“分值节点”。同时,为了维持zset的有序性,ziplist中的节点两两一组并按分值score从小到大排序。
所以ziplist编码的zset存储结构如下所示:
2.2、skiplist编码的zset存储结构
skiplist编码的有序集合定义在redis.h头文件中:
/* 有序集合结构体 */
typedef struct zset {
// 字典,维护元素值和分值的映射关系
dict *dict;
// 按分值对元素值排序序,支持O(longN)数量级的查找操作
zskiplist *zsl;
} zset;看到这里你会不会感到奇怪:不是说以skiplist编码吗,为什么还会有dict在里面?这里解释一下dict的作用。在上面介绍中我们说过跳跃表可以实现平均复杂度为O(longN)的插入、删除和查找操作,这是zset高效运行的基础。但是zset还需要支持诸如获取元素值对应的分值、判断某元素值是否存在zset中等命令,对于这些操作,如果在跳跃表的基础上实现效果并不好。所以作者增加了一个dict来维护元素值和分值的映射关系(键为元素值、值为分值),这样就能快速获取指定成员的分值,弥补skiplist在这方面的不足。
到这里,我们已经了解了zset两种编码方式的存储结构。类似我们前面介绍的List类型,zset相关函数的主要功能之一就是要在ziplist和skiplist这两种结构上维护一份统一的zset操作接口,以屏蔽底层的差异。这些操作没有什么难点,这里就不一一赘述,大家可以参看我后面提供的注释源码。
3、范围操作命令
zset中有很多跟范围相关的命令,大致可以归纳为以下三种:
- 获取或删除指定排位区间内的元素,如zrange、zrevrange、zremrangebyrank命令。
- 获取或删除指定分值区间内的元素,如zrangebyscore、zrevrangebyscore、zremrangebyscore命令。
- 获取或删除指定字典序区间内的元素,如zrangebylex、zremrangebylex。对于这种情况,需要注意:只有当插入到有序集合(Sorted set)中的所有元素的分值score都相同时,使用zrangebylex或zremrangebylex命令可以认为存储在有序集合中的元素是按字典序排序(Lexicographical ordering)的,然后返回或删除元素值在最小值 min 及最大值 max 之间的所有元素。如果有序集合中的元素存在不同的分值,所返回或删除的元素是不确定的。
为了方便范围操作,Redis在redis.h头文件中定了了分值区间结构体和字典区间结构体:
/* Struct to hold a inclusive/exclusive range spec by score comparison. */
/* 指明某个区间为开区间 or 闭区间 的结构体 */
typedef struct {
// 最小值、最大值
double min, max;
// 是否包含最小值、是否包含最大值(0表示包含、1表示不包含)
int minex, maxex; /* are min or max exclusive? */
} zrangespec;
/* Struct to hold an inclusive/exclusive range spec by lexicographic comparison. */
/* 以字典顺序表示的开区间 or 闭区间 */
typedef struct {
robj *min, *max; /* May be set to shared.(minstring|maxstring) */
// 是否包含最小值、是否包含最大值(0表示包含、1表示不包含)
int minex, maxex; /* are min or max exclusive? */
} zlexrangespec;我们以zslDeleteRangeByScore和zzlDeleteRangeByScore函数为例,总结这类区间操作的一般过程。
zslDeleteRangeByScore函数用于删除skiplist编码的有序集合中分值在指定范围的元素,实现如下:
unsigned long zslDeleteRangeByScore(zskiplist *zsl, zrangespec *range, dict *dict) {
// update数组用来记录降层节点
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long removed = 0;
int i;
x = zsl->header;
// 从前往后遍历,记录降层节点,方面以后修改指针
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward && (range->minex ?
x->level[i].forward->score <= range->min :
x->level[i].forward->score < range->min))
x = x->level[i].forward;
update[i] = x;
}
/* Current node is the last with score < or <= min. */
// 定位到第一次中待删除的第一个节点
x = x->level[0].forward;
/* Delete nodes while in range. */
// 删除range指定范围内的所有节点
while (x &&
(range->maxex ? x->score < range->max : x->score <= range->max))
{
// 记录下一个节点的位置
zskiplistNode *next = x->level[0].forward;
// 删除节点
zslDeleteNode(zsl,x,update);
// 删除dict中相应的元素
dictDelete(dict,x->obj);
zslFreeNode(x);
// 记录删除节点个数
removed++;
// 指向下一个节点
x = next;
}
return removed;
}zzlDeleteRangeByScore函数用于删除ziplist编码的有序集合中分值在指定范围的元素,实现如下:
unsigned char *zzlDeleteRangeByScore(unsigned char *zl, zrangespec *range, unsigned long *deleted) {
unsigned char *eptr, *sptr;
double score;
unsigned long num = 0;
if (deleted != NULL) *deleted = 0;
// 指向ziplist中分值落在指定范围的第一个节点
eptr = zzlFirstInRange(zl,range);
if (eptr == NULL) return zl;
/* When the tail of the ziplist is deleted, eptr will point to the sentinel * byte and ziplistNext will return NULL. */
// 一直删除节点一直遇到不在range指定范围内的节点为止
while ((sptr = ziplistNext(zl,eptr)) != NULL) {
score = zzlGetScore(sptr);
if (zslValueLteMax(score,range)) {
/* Delete both the element and the score. */
zl = ziplistDelete(zl,&eptr);
zl = ziplistDelete(zl,&eptr);
num++;
} else {
/* No longer in range. */
break;
}
}
if (deleted != NULL) *deleted = num;
return zl;
}我们可以看到,zset范围操作的一般过程是:
- 先找到ziplist或skiplist中落在指定区间内开始迭代的第一个节点。比如分值指定分值区间为[3,10],如果是正向操作的话,第一步先找出第一个分值大于或等于3的节点,接下来往后遍历;如果是逆向操作的话,第一步先找出第一个分值小于或等于10的节点,接下来往前遍历。
- 上一步中得到开始遍历节点,接下来就从该节点开始依次正向或逆向遍历直到遇到不满足要求的节点后跳出。
zset的实现分析大概就讲这么多吧,关于细节方面的东西大家还是需要看看源码,这样子更好把握。
注释版源码:https://github.com/xiejingfa/the-annotated-redis-2.8.24/blob/master/t_zset.c