合并排序
合并排序,顾名思义,就是通过将两个有序的序列合并为一个大的有序的序列的方式来实现排序。合并排序是一种典型的分治算法:首先将序列分为两部分,然后对每一部分进行循环递归的排序,然后逐个将结果进行合并。

合并排序最大的优点是它的时间复杂度为O(nlgn),这个是我们之前的选择排序和插入排序所达不到的。他还是一种稳定性排序,也就是相等的元素在序列中的相对位置在排序前后不会发生变化。他的唯一缺点是,需要利用额外的N的空间来进行排序。
一 原理

合并排序依赖于合并操作,即将两个已经排序的序列合并成一个序列,具体的过程如下:
- 申请空间,使其大小为两个已经排序序列之和,然后将待排序数组复制到该数组中。
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较复制数组中两个指针所指向的元素,选择相对小的元素放入到原始待排序数组中,并移动指针到下一位置
- 重复步骤3直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到原始数组末尾
该过程实现如下,注释比较清楚:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
private
static
void
Merge(T[] array,
int
lo,
int
mid,
int
hi)
{
int
i = lo, j = mid +
1
;
//把元素拷贝到辅助数组中
for
(
int
k = lo; k <= hi; k++)
{
aux[k] = array[k];
}
//然后按照规则将数据从辅助数组中拷贝回原始的array中
for
(
int
k = lo; k <= hi; k++)
{
//如果左边元素没了, 直接将右边的剩余元素都合并到到原数组中
if
(i > mid)
{
array[k] = aux[j++];
}
//如果右边元素没有了,直接将所有左边剩余元素都合并到原数组中
else
if
(j > hi)
{
array[k] = aux[i++];
}
//如果左边右边小,则将左边的元素拷贝到原数组中
else
if
(aux[i].CompareTo(aux[j]) <
0
)
{
array[k] = aux[i++];
}
else
{
array[k] = aux[j++];
}
}
}
|
下图是使用以上方法将EEGMR和ACERT这两个有序序列合并为一个大的序列的过程演示:
二 实现
合并排序有两种实现,一种是至上而下(Top-Down)合并,一种是至下而上 (Bottom-Up)合并,两者算法思想差不多,这里仅介绍至上而下的合并排序。
至上而下的合并是一种典型的分治算法(Divide-and-Conquer),如果两个序列已经排好序了,那么采用合并算法,将这两个序列合并为一个大的序列也就是对大的序列进行了排序。
首先我们将待排序的元素均分为左右两个序列,然后分别对其进去排序,然后对这个排好序的序列进行合并,代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public
class
MergeSort<T> where T : IComparable<T>
{
private
static
T[] aux;
// 用于排序的辅助数组
public
static
void
Sort(T[] array)
{
aux =
new
T[array.Length];
// 仅分配一次
Sort(array,
0
, array.Length -
1
);
}
private
static
void
Sort(T[] array,
int
lo,
int
hi)
{
if
(lo >= hi)
return
;
//如果下标大于上标,则返回
int
mid = lo + (hi - lo) /
2
;
//平分数组
Sort(array, lo, mid);
//循环对左侧元素排序
Sort(array, mid +
1
, hi);
//循环对右侧元素排序
Merge(array, lo, mid, hi);
//对左右排好的序列进行合并
}
...
}
|
以排序一个具有15个元素的数组为例,其调用堆栈为:
我们单独将Merge步骤拿出来,可以看到合并的过程如下:

三 图示及动画
如果以排序38,27,43,3,9,82,10为例,将合并排序画出来的话,可以看到如下图:
下图是合并排序的可视化效果图:
对6 5 3 1 8 7 24 进行合并排序的动画效果如下:
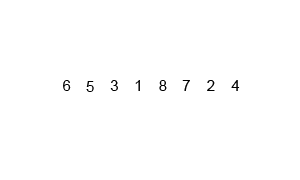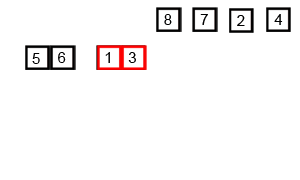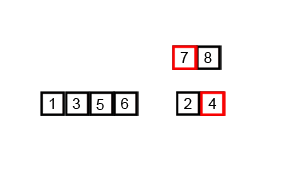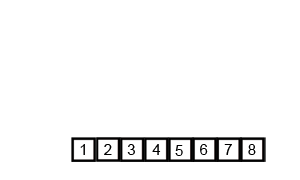
下图演示了合并排序在不同的情况下的效率:

四 分析
1. 合并排序的平均时间复杂度为O(nlgn)
证明:合并排序是目前我们遇到的第一个时间复杂度不为n2的时间复杂度为nlgn(这里lgn代表log2n)的排序算法,下面给出对合并排序的时间复杂度分析的证明:
假设D(N)为对整个序列进行合并排序所用的时间,那么一个合并排序又可以二分为两个D(N/2)进行排序,再加上与N相关的比较和计算中间数所用的时间。整个合并排序可以用如下递归式表示:
D(N)=2D(N/2)+N,N>1;
D(N)=0,N=1; (当N=1时,数组只有1个元素,已排好序,时间为0)
因为在分治算法中经常会用到递归式,所以在CLRS中有一章专门讲解递归式的求解和证明,使用主定理(master theorem)可以直接求解出该递归式的值,后面我会简单介绍。这里简单的列举两种证明该递归式时间复杂度为O(nlgn)的方法:
Prof1:处于方便性考虑,我们假设数组N为2的整数幂,这样根据递归式我们可以画出一棵树:

可以看到我们对数组N进行MergeSort的时候,是逐级划分的,这样就形成了一个满二叉树,树的每一及子节点都为N,树的深度即为层数lgN+1,满二叉树的深度的计算可以查阅相关资料,上图中最后一层子节点没有画出来。这样,这棵树有lgN+1层,每一层有N个节点,所以
D(N)=(lgN+1)N=NlgN+N=NlgN
Prof2:我们在为递归表达式求解的时候,还有一种常用的方法就是数学归纳法,
首先根据我们的递归表达式的初始值以及观察,我们猜想D(N)=NlgN.
- 当N=1 时,D(1)=0,满足初始条件。
- 为便于推导,假设N是2的整数次幂N=2k, 即D(2k)=2klg2k = k*2k
- 在N+1 的情况下D(N+1)=D(2k+1)=2k+1lg2k+1=(k+1) * 2k+1,所以假设成立,D(N)=NlgN.
2. 合并排序需要额外的长度为N的辅助空间来完成排序
如果对长度为N的序列进行排序需要<=clogN 的额外空间,认为就是就地排序(in place排序)也就是完成该排序操作需要较小的,固定数量的额外辅助内存空间。之前学习过的选择排序,插入排序,希尔排序都是原地排序。
但是在合并排序中,我们要创建一个大小为N的辅助排序数组来存放初始的数组或者存放合并好的数组,所以需要长度为N的额外辅助空间。当然也有前人已经将合并排序改造为了就地合并排序,但是算法的实现变得比较复杂。
需要额外N的空间来辅助排序是合并排序的最大缺点,如果在内存比较关心的环境中可能需要采用其他算法。
五 几点改进
对合并排序进行一些改进可以提高合并排序的效率。
1. 当划分到较小的子序列时,通常可以使用插入排序替代合并排序
对于较小的子序列(通常序列元素个数为7个左右),我们就可以采用插入排序直接进行排序而不用继续递归了),算法改造如下:
|
1
2
3
4
5
6
7
8
9
10
|
private
const
int
CUTOFF =
7
;
//采用插入排序的阈值
private
static
void
Sort(T[] array,
int
lo,
int
hi)
{
if
(lo >= hi)
return
;
//如果下标大于上标,则返回
if
(hi <= lo + CUTOFF -
1
) Sort<T>.SelectionSort(array, lo, hi);
int
mid = lo + (hi - lo) /
2
;
//平分数组
Sort(array, lo, mid);
//循环对左侧元素排序
Sort(array, mid +
1
, hi);
//循环对右侧元素排序
Merge(array, lo, mid, hi);
//对左右排好的序列进行合并
}
|
2. 如果已经排好序了就不用合并了
当已排好序的左侧的序列的最大值<=右侧序列的最小值的时候,表示整个序列已经排好序了。
算法改动如下:
|
1
2
3
4
5
6
7
8
9
10
|
private
static
void
Sort(T[] array,
int
lo,
int
hi)
{
if
(lo >= hi)
return
;
//如果下标大于上标,则返回
if
(hi <= lo + CUTOFF -
1
) Sort<T>.SelectionSort(array, lo, hi);
int
mid = lo + (hi - lo) /
2
;
//平分数组
Sort(array, lo, mid);
//循环对左侧元素排序
Sort(array, mid +
1
, hi);
//循环对右侧元素排序
if
(array[mid].CompareTo(array[mid +
1
]) <=
0
)
return
;
Merge(array, lo, mid, hi);
//对左右排好的序列进行合并
}
|
3. 并行化
分治算法通常比较容易进行并行化,在浅谈并发与并行这篇文章中已经展示了如何对快速排序进行并行化(快速排序在下一篇文章中讲解),合并排序一样,因为我们均分的左右两侧的序列是独立的,所以可以进行并行,值得注意的是,并行化也有一个阈值,当序列长度小于某个阈值的时候,停止并行化能够提高效率,这些详细的讨论在浅谈并发与并行这篇文章中有详细的介绍了,这里不再赘述。
六 用途
合并排序和快速排序一样都是时间复杂度为nlgn的算法,但是和快速排序相比,合并排序是一种稳定性排序,也就是说排序关键字相等的两个元素在整个序列排序的前后,相对位置不会发生变化,这一特性使得合并排序是稳定性排序中效率最高的一个。在Java中对引用对象进行排序,Perl、C++、Python的稳定性排序的内部实现中,都是使用的合并排序。
七 结语
本文介绍了分治算法中比较典型的一个合并排序算法,这也是我们遇到的第一个时间复杂度为nlgn的排序算法,并简要对算法的复杂度进行的分析,希望本文对您理解合并排序有所帮助,下文将介绍快速排序算法。