twemproxy + redis + sentinel 实现redis集群高可用
本文主要描述使用 twemproxy + redis + sentinel + 脚本 实现redis集群的高可用,篇幅有点长(实战配置文件/命令)
先贴个本文主要标题列表哈
- redis简介
- sentinel 功能
- twemproxy特性
- twemproxy + redis + sentinel 实现redis集群高可用架构图
- 实战一 :环境部署
- 实战二 :redis 主从配置
- 实战三 :sentinel 配置
- 实战四 :twemproxy 配置
redis
Redis 是完全开源免费的,遵守BSD协议,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件,是一个高性能的key-value数据库。
前面有篇文档写到了redis简介及安装和压测数据:http://www.huangdc.com/246
redis sentinel
redis sentinel 是redis 官方推荐的redis 高可用(HA)解决方案
sentinel 的功能:
- 监控(Monitoring),sentinel 时刻监控着redis master-slave 是否正常运行
- 通知(Notification),sentinel 可以通过api 来通知管理员,被监控的redis master-slave 出现了问题
- 自动故障转移(Automatic failover),当redis master 出现故障不可用状态,sentinel 会开始一次故障转移,将其中一个 slave 提升为新的master ,将其他的slave 将重新配置使用新的master同步,并使用Redis的服务器应用程序在连接时收到使用新的地址连接
- 配置提供者(Configuration provider) ,sentinel 作为在集群中的权威来源,客户端连接到sentinel来获取某个服务的当前Redis主服务器的地址和其他信息。当故障转移发生时,Sentinel 会报告新地址。
twemproxy (nutcraker)
Twemproxy,也叫nutcraker。是一个twtter开源的一个redis 和memcache 快速/轻量级代理服务器;Twemproxy是一个快速的单线程代理程序,支持Memcached ASCII协议和更新的Redis协议
Twemproxy 通过引入一个代理层,可以将其后端的多台 Redis 或 Memcached 实例进行统一管理与分配,使应用程序只需要在 Twemproxy 上进行操作,而不用关心后面具体有多少个真实的 Redis 或 Memcached 存储
twemproxy 的特性:
- 支持失败节点自动删除
- 可以设置重新连接该节点的时间
- 可以设置连接多少次之后删除该节点 - 支持设置HashTag
- 通过HashTag可以自己设定将两个key哈希到同一个实例上去 - 减少与redis的直接连接数
- 保持与redis的长连接
- 减少了客户端直接与服务器连接的连接数量 - 自动分片到后端多个redis实例上
- 多种hash算法:md5、crc16、crc32 、crc32a、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins
- 多种分片算法:ketama(一致性hash算法的一种实现)、modula、random
- 可以设置后端实例的权重 - 避免单点问题
- 可以平行部署多个代理层,通过HAProxy做负载均衡,将redis的读写分散到多个twemproxy上。 - 支持状态监控
- 可设置状态监控ip和端口,访问ip和端口可以得到一个json格式的状态信息串
- 可设置监控信息刷新间隔时间 - 使用 pipelining 处理请求和响应
- 连接复用,内存复用
- 将多个连接请求,组成reids pipelining统一向redis请求 - 并不是支持所有redis命令
- 不支持redis的事务操作
- 使用SIDFF, SDIFFSTORE, SINTER, SINTERSTORE, SMOVE, SUNION and SUNIONSTORE命令需要保证key都在同一个分片上。
twemproxy + redis + sentinel 高可用架构
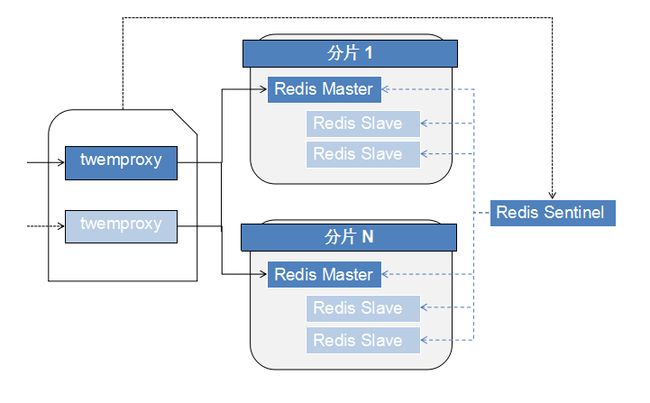
- 前端使用twemproxy (主备节点)做代理,将其后端的多台Redis实例分片进行统一管理与分配
- 每一个分片节点的redis slave 都是redis master的副本且只读
- redis sentinel 持续不断的监控每个分片节点的master,当master出现故障且不可用状态时,sentinel 会通知/启动自动故障转移等动作
- sentinel 可以在发生故障转移动作后触发相应脚本(通过 client-reconfig-script 参数配置 ),脚本获取到最新的master来修改 twemproxy 配置并重启 twemproxy
实战一 :环境部署
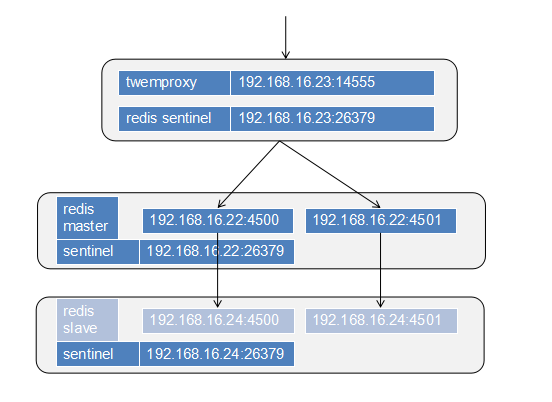
实验环境:(简单化用三台主机)
| ip | 系统 | 部署软件 | twemproxy服务 | redis服务 | sentinel服务 |
| 192.168.16.23 | CentOS 6.7 | redis twemproxy |
192.168.16.23:14500 | _ | 192.168.16.23:26379 |
| 192.168.16.22 | CentOS 6.7 | redis | _ | 192.168.16.22:4500 192.168.16.22:4501 |
192.168.16.22:26379 |
| 192.168.16.24 | CentOS 6.7 | redis | _ | 192.168.16.24:4500 192.168.16.24:4501 |
192.168.16.24:26379 |
实验架构图:
安装redis
分别在三台服务器都安装 redis (192.168.16.22,192.168.16.23,192.168.16.24 )
## 下载 && 解压并安装 wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar zxf redis-3.0.6.tar.gz cd redis-3.0.6 make && make install ## 检查bin文件 及 版本(默认bin文件路径为 /usr/local/bin/ ,也可以在编译时候加上 --prefix 参数自定义目录) [root@vm16-22 ~]# ll /usr/local/bin/redis* -rwxr-xr-x 1 root root 4589115 Feb 23 15:07 /usr/local/bin/redis-benchmark -rwxr-xr-x 1 root root 22177 Feb 23 15:07 /usr/local/bin/redis-check-aof -rwxr-xr-x 1 root root 45395 Feb 23 15:07 /usr/local/bin/redis-check-dump -rwxr-xr-x 1 root root 4698322 Feb 23 15:07 /usr/local/bin/redis-cli lrwxrwxrwx 1 root root 12 Feb 23 15:07 /usr/local/bin/redis-sentinel -> redis-server -rwxr-xr-x 1 root root 6471190 Feb 23 15:07 /usr/local/bin/redis-server [root@vm16-22 ~]# /usr/local/bin/redis-server -v Redis server v=3.0.6 sha=00000000:0 malloc=jemalloc-3.6.0 bits=64 build=a1df4a293d9213e9
安装twemproxy
在 192.168.16.23 服务器安装 twemproxy
安装twemproxy 前,需要安装autoconf,automake,libtool 软件包
1、编译安装autoconf
## 下载 && 解压并安装 wget http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz tar zxf autoconf-2.69.tar.gz ./configure make && make install
2、编译安装automake
## 下载 && 解压并安装 wget http://ftp.gnu.org/gnu/automake/automake-1.15.tar.gz tar zxf automake-1.15.tar.gz ./configure make && make install
3、编译安装libtool
## 下载 && 解压并安装 wget https://ftp.gnu.org/gnu/libtool/libtool-2.4.6.tar.gz tar zxf libtool-2.4.6.tar.gz cd libtool-2.4.6 ./configure make && make install
4、编译安装twemproxy
## 下载 && 解压并安装 wget https://github.com/twitter/twemproxy/archive/master.zip unzip master.zip cd twemproxy-master ## 在twemproxy源码目录执行autoreconf 生成 configure文件等 aclocal autoreconf -f -i -Wall,no-obsolete ## 然后编译安装 ./configure --prefix=/usr/local/twemproxy/ make && make install
注意:如果没有安装libtool 的话,autoreconf 的时候会报错,如下:
configure.ac:133: the top level
configure.ac:36: error: possibly undefined macro: AC_PROG_LIBTOOL
If this token and others are legitimate, please use m4_pattern_allow.
See the Autoconf documentation.
autoreconf: /usr/local/bin/autoconf failed with exit status: 1
实战二 : redis 主从配置
1、创建目录环境
##
## 在192.168.12.22 , 192.168.12.24 创建目录
mkdir -p /data/nosql/{redis_4500,redis_4501,sentinel}
## 在192.168.12.23 创建目录
mkdir -p /data/nosql/sentinel
mkdir -p /usr/local/twemproxy/{conf,logs}
192.168.12.22:4500 -> 192.168.12.24:4500 (主->从)
192.168.12.22:4501 -> 192.168.12.24:4501 (主->从)
2、在 192.168.12.22 配置 192.168.12.22:4500 redis master
在192.168.12.22 配置master文件 /data/nosql/redis_4500/redis.conf ,文件内容如下:
daemonize yes ##使用daemon 方式运行程序,默认为非daemon方式运行
pidfile "/data/nosql/redis_4500/redis.pid" ##pid文件位置
port 4500 ##监听端口
bind 192.168.16.22 ##绑定ip
timeout 0 ## client 端空闲断开连接的时间
loglevel warning ##日志记录级别,默认是notice,我这边使用warning,是为了监控日志方便。
## 使用warning后,只有发生告警才会产生日志,这对于通过判断日志文件是否为空来监控报警非常方便。
logfile "/data/nosql/redis_4500/redis.log"
databases 16 ##默认是0,也就是只用1 个db,我这边设置成16,方便多个应用使用同一个redis server。
##使用select n 命令可以确认使用的redis db ,这样不同的应用即使使用相同的key也不会有问题。
##下面是SNAPSHOTTING持久化方式的策略。
##为了保证数据相对安全,在下面的设置中,更改越频繁,SNAPSHOTTING越频繁,
##也就是说,压力越大,反而花在持久化上的资源会越多。
##所以我选择了master-slave模式,并在master关掉了SNAPSHOTTING。
save 900 1 #在900秒之内,redis至少发生1次修改则redis抓快照到磁盘
save 300 10 #在300秒之内,redis至少发生100次修改则redis抓快照到磁盘
save 60 10000 #在60秒之内,redis至少发生10000次修改则redis抓快照到磁盘
stop-writes-on-bgsave-error yes
rdbcompression yes ##使用压缩
rdbchecksum yes
dbfilename "dump.rdb"
dir "/data/nosql/redis_4500"
## replication 设置
slave-serve-stale-data yes
slave-read-only yes
slave-priority 100
###LIMIT 设置
maxmemory 256mb ##redis最大可使用的内存量,如果使用redis SNAPSHOTTING的copy-on-write的持久会写方式,会额外的使用内存,
##为了使持久会操作不会使用系统VM,使redis服务器性能下降,建议保留redis最大使用内存的一半来留给持久化使用
maxmemory-policy allkeys-lru ##使用LRU算法删除设置了过期时间的key,但如果程序写的时间没有写key的过期时间
##建议使用allkeys-lru,这样至少保证redis不会不可写入
##append only mode设置
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
lua-time-limit 5000
###slow log 设置
slowlog-log-slower-than 10000
slowlog-max-len 128
##advanced config设置,下面的设置主要是用来节省内存的
hash-max-ziplist-entries 1024
hash-max-ziplist-value 2048
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
启动master 4500 端口:
## [root@vm16-22 ~]# /usr/local/bin/redis-server /data/nosql/redis_4500/redis.conf
3、在 192.168.12.24 配置 192.168.12.24:4500 redis slave
在 192.168.12.24 配置slave文件 /data/nosql/redis_4500/redis.conf
redis slave 从实例需要多加一个配置参数: slaveof 192.168.16.22 4500 , 指明master 的ip 和端口
文件内容如下:
daemonize yes pidfile "/data/nosql/redis_4500/redis.pid" port 4500 ##监听端口 bind 192.168.16.24 ##绑定ip timeout 0 loglevel warning logfile "/data/nosql/redis_4500/redis.log" databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename "dump.rdb" dir "/data/nosql/redis_4500" slave-serve-stale-data yes slave-read-only yes slave-priority 100 maxmemory 256mb ##缓存大小 maxmemory-policy allkeys-lru appendonly no appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 hash-max-ziplist-entries 1024 hash-max-ziplist-value 2048 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 # Generated by CONFIG REWRITE ## slave 实例只需要配置 slaveof 即可 slaveof 192.168.16.22 4500
启动 slave 实例服务
## [root@vm16-24 ~]# /usr/local/bin/redis-server /data/nosql/redis_4500/redis.conf
4、192.168.12.22:4501 -> 192.168.12.24:4501 的 master->slave 同理第2、3步骤
5、检查两个主从实例信息:
## 查看redis 进程 [root@vm16-22 ~]# ps -ef |grep redis root 37694 1 0 Mar04 ? 00:10:52 /usr/local/bin/redis-server 192.168.16.22:4501 root 39611 65000 0 22:03 pts/2 00:00:00 grep redis root 60304 1 0 Mar04 ? 00:10:07 /usr/local/bin/redis-server 192.168.16.22:4500 [root@vm16-24 ~]# ps -ef |grep redis root 36265 1 0 Mar04 ? 00:10:08 /usr/local/bin/redis-server 192.168.16.24:4501 root 63873 24110 0 22:03 pts/0 00:00:00 grep redis root 65394 1 0 Mar04 ? 00:10:38 /usr/local/bin/redis-server 192.168.16.24:4500 ## 检查主从信息 info replication ### 4500 端口主信息 [root@vm16-22 ~]# redis-cli -h 192.168.16.22 -p 4500 info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.16.24,port=4500,state=online,offset=96330188,lag=0 master_repl_offset:96330188 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:95281613 repl_backlog_histlen:1048576 ### 4500 端口从信息 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4500 info replication # Replication role:slave master_host:192.168.16.22 master_port:4500 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:96354366 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 ### 4501 端口主信息 [root@vm16-22 ~]# redis-cli -h 192.168.16.22 -p 4501 info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.16.24,port=4501,state=online,offset=50410,lag=0 master_repl_offset:50553 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:50552 ### 4501 端口从信息 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4501 info replication # Replication role:slave master_host:192.168.16.22 master_port:4501 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:75031 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
6、检查两个主从实例同步:
检查 192.168.12.22:4500 -> 192.168.12.24:4500 (主->从)同步
## 主设置一个key huangdc [root@vm16-22 ~]# redis-cli -h 192.168.16.22 -p 4500 set huangdc "i love you" OK ## 在从获取 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4500 get huangdc "i love you"
检查 192.168.12.22:4501 -> 192.168.12.24:4501 (主->从)同步
## 主设置一个key huangdc4501 [root@vm16-22 ~]# redis-cli -h 192.168.16.22 -p 4500 set huangdc4501 "i love you 4501" OK ## 在从获取 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4500 get huangdc4501 "i love you 4501"
ok , 两个主从同步没有问题
实战三 : sentinel 配置
在三台服务器配置 sentinel ,sentinel 默认监听端口是 26379
1、三台服务器的sentinel 配置文件 /data/nosql/sentinel/sentinel.conf ,内容如下:
# Global port 26379 ##监听端口 daemonize yes ##使用daemon方式运行程序,默认为非daemon方式运行 dir "/data/nosql/sentinel" pidfile "/data/nosql/sentinel/sentinel.pid" loglevel notice logfile "/data/nosql/sentinel/sentinel.log" ## ## sentinel monitor <master-group-name> <ip> <port> <quorum> ####行尾的<quorum>是数字 ####这个数字表明需要最少多少个sentinel互相沟通来确认某个master是否真的死了 # ## sentinel <option_name> <master-group-name> <option_value> #### down-after-milliseconds : sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒。 #### failover-timeout : 这个选项确定自动转移故障超时时间,单位毫秒 #### parallel-syncs : 在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步 sentinel monitor redis_14555_g1_4500 192.168.16.22 4500 2 sentinel down-after-milliseconds redis_14555_g1_4500 2500 sentinel failover-timeout redis_14555_g1_4500 10000 sentinel parallel-syncs redis_14555_g1_4500 1 sentinel monitor redis_14555_g2_4501 192.168.16.22 4501 2 sentinel down-after-milliseconds redis_14555_g2_4501 2500 sentinel failover-timeout redis_14555_g2_4501 10000 sentinel parallel-syncs redis_14555_g2_4501 1
上面的配置项配置了两个名字分别为redis_14555_g1_4500 和redis_14555_g2_4501 的master,配置文件只需要配置master的信息就好啦,不用配置slave的信息,因为slave能够被自动检测到(master节点会有关于slave的消息)。需要注意的是,配置文件在sentinel运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的master会被修改为另外一个slave。这样,之后sentinel如果重启时,就可以根据这个配置来恢复其之前所监控的redis集群的状态。
大家在这里记一下我给两个master的命名为 redis_14555_g1_4500 和 redis_14555_g2_4501 ,是有目的的,为了sentinel 后面触发修改twemproxy 的配置文件和重启有关系
sentinel 的配置信息也可以通过动态配置 ,如 SENTINEL SET command动态修改
2、在三台服务器分别启动 sentinel 服务
# /usr/local/bin/redis-sentinel /data/nosql/sentinel/sentinel.conf
3、测试sentinel 自动故障转移(kill掉一个master ,sentinel 会将slave 提升为master)
在前面redis 配置主从时候,我们已经检查过了 主从的信息
## 查看 192.168.16.24:4501 的信息( role:slave ) [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4501 info replication # Replication role:slave ## slave master_host:192.168.16.22 master_port:4501 master_link_status:up master_last_io_seconds_ago:0 master_sync_in_progress:0 slave_repl_offset:855442 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 ## kill 掉 192.168.16.22:4501 master 进程 [root@vm16-22 ~]# ps -ef |grep 4501 root 14455 59263 0 23:16 pts/2 00:00:00 grep 4501 root 37694 1 0 Mar04 ? 00:10:58 /usr/local/bin/redis-server 192.168.16.22:4501 [root@vm16-22 ~]# kill 37694 [root@vm16-22 ~]# ps -ef |grep 4501 root 14532 59263 0 23:16 pts/2 00:00:00 grep 4501 ## 立马再次查看 192.168.16.24:4501 的信息,角色role 还是slave ;因为故障转移需要一点时间 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4501 info replication # Replication role:slave ## slave master_host:192.168.16.22 master_port:4501 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:857887 master_link_down_since_seconds:20 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 ## 稍等几秒,再次查看 192.168.16.24:4501 的信息,角色role 还是master;故障转移成功,提升slave为 master了 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4501 info replication # Replication role:master ## master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 [root@vm16-22 ~]#
4、查看一台sentinel 的日志信息
55580:X 09 Mar 23:17:01.856 # +new-epoch 9 55580:X 09 Mar 23:17:01.856 # +try-failover master redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:01.900 # +vote-for-leader f88ba4336b43abddc5c9fbffbc564b2bc213560c 9 55580:X 09 Mar 23:17:01.979 # 192.168.16.23:26379 voted for f88ba4336b43abddc5c9fbffbc564b2bc213560c 9 55580:X 09 Mar 23:17:01.986 # 192.168.16.24:26379 voted for f88ba4336b43abddc5c9fbffbc564b2bc213560c 9 55580:X 09 Mar 23:17:02.040 # +elected-leader master redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.040 # +failover-state-select-slave master redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.117 # +selected-slave slave 192.168.16.24:4501 192.168.16.24 4501 @ redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.117 * +failover-state-send-slaveof-noone slave 192.168.16.24:4501 192.168.16.24 4501 @ redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.176 * +failover-state-wait-promotion slave 192.168.16.24:4501 192.168.16.24 4501 @ redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.425 # +promoted-slave slave 192.168.16.24:4501 192.168.16.24 4501 @ redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.425 # +failover-state-reconf-slaves master redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.425 # +failover-end master redis_14555_g2_4501 192.168.16.22 4501 55580:X 09 Mar 23:17:02.425 # +switch-master redis_14555_g2_4501 192.168.16.22 4501 192.168.16.24 4501 55580:X 09 Mar 23:17:02.426 * +slave slave 192.168.16.22:4501 192.168.16.22 4501 @ redis_14555_g2_4501 192.168.16.24 4501 55580:X 09 Mar 23:17:04.956 # +sdown slave 192.168.16.22:4501 192.168.16.22 4501 @ redis_14555_g2_4501 192.168.16.24 4501
大家可以自行查看一下相关说明
实战四 : twemproxy 配置
因为sentinel 确保了 redis 主从故障转移,当master 出现故障后,将slave提升为master 继续为客户端提供缓存服务;但是新的master ip 和端口信息已经发生了改变,所以客户端需要重新配置文件或者改造程序才能重新连接新的master ,这样有点不方便 。为了方便客户端无需改造及redis 达到高可用状态(故障恢复时间保持在1分钟内),我们采用 twemproxy 做redis 前端代理,分片存储数据,结合sentinel故障转移时的通知/触发脚本功能,做一个自动故障转移且高可用的redis 集群。也就是本文最开始的架构图 twemproxy + redis + sentinel + 脚本 实现redis高可用架构(高可用集群)
redis 主从 和 sentinel 基本都已经配置好了,我们现在来配置一下 twemproxy
1、在 192.168.16.23 服务器上配置twemproxy ,配置文件为 /usr/local/twemproxy/conf/redis_14555.yml
内容为:
redis_14555: listen: 192.168.16.23:14555 hash: fnv1a_64 distribution: ketama auto_eject_hosts: true redis: true server_retry_timeout: 2000 server_failure_limit: 1 servers: - 192.168.16.22:4500:1 - 192.168.16.22:4501:1
上面配置了两个redis master 的分片 192.168.16.22:4500 和 192.168.16.22:4501 。
这里的参数我们先不讲,我们看看配置的文件名是 redis_14555.yml ,大家有没有想起来,跟sentinel monitor 监控的 master-group-name 有关系,对了取的就是master-group-name 的前半段(redis_14555_g1_4500); 大家再记住一下,后面还会用到
2、启动twemproxy
## 启动 [root@vm16-23 ~]# /usr/local/twemproxy/sbin/nutcracker -c /usr/local/twemproxy/conf/redis_14555.yml -p /usr/local/twemproxy/conf/redis_14555.pid -o /usr/local/twemproxy/logs/redis_14555.log -v 11 -d [root@vm16-23 ~]# ps -ef |grep nutcracker root 9356 1 0 23:56 ? 00:00:00 /usr/local/twemproxy/sbin/nutcracker -c /usr/local/twemproxy/conf/redis_14555.yml -p /usr/local/twemproxy/conf/redis_14555.pid -o /usr/local/twemproxy/logs/redis_14555.log -v 11 -d
启动相关参数信息说明:
Usage: nutcracker [-?hVdDt] [-v verbosity level] [-o output file]
[-c conf file] [-s stats port] [-a stats addr]
[-i stats interval] [-p pid file] [-m mbuf size]
Options:
-h, --help : this help
-V, --version : show version and exit
-t, --test-conf : test configuration for syntax errors and exit
-d, --daemonize : run as a daemon
-D, --describe-stats : print stats description and exit
-v, --verbose=N : set logging level (default: 5, min: 0, max: 11)
-o, --output=S : set logging file (default: stderr)
-c, --conf-file=S : set configuration file (default: conf/nutcracker.yml)
-s, --stats-port=N : set stats monitoring port (default: 22222)
-a, --stats-addr=S : set stats monitoring ip (default: 0.0.0.0)
-i, --stats-interval=N : set stats aggregation interval in msec (default: 30000 msec)
-p, --pid-file=S : set pid file (default: off)
-m, --mbuf-size=N : set size of mbuf chunk in bytes (default: 16384 bytes)
3、测试 twemproxy set/get ,后端分片查看
## 测试set 和 get ## 测试短key - value [root@vm16-23 ~]# redis-cli -h 192.168.16.23 -p 14555 set huang "dc" OK [root@vm16-23 ~]# redis-cli -h 192.168.16.23 -p 14555 get huang "dc" ## 测试长key - value [root@vm16-23 ~]# redis-cli -h 192.168.16.23 -p 14555 set huangggggggggggggggggggggggggg "dccccccccccccccccccccccccccccccccccccc" OK [root@vm16-23 ~]# redis-cli -h 192.168.16.23 -p 14555 get huangggggggggggggggggggggggggg "dccccccccccccccccccccccccccccccccccccc" ## 直接通过后端redis 的master get key 查看存储,会发现已经分片了 [root@vm16-23 ~]# redis-cli -h 192.168.16.22 -p 4500 get huang "dc" [root@vm16-23 ~]# redis-cli -h 192.168.16.22 -p 4501 get huang (nil) [root@vm16-23 ~]# redis-cli -h 192.168.16.22 -p 4500 get huangggggggggggggggggggggggggg (nil) [root@vm16-23 ~]# redis-cli -h 192.168.16.22 -p 4501 get huangggggggggggggggggggggggggg "dccccccccccccccccccccccccccccccccccccc"
我们现在将 192.168.16.22:4501 master 直接kill 掉 ,并查看 192.168.16.22:4501 的从服务192.168.16.24:4501是否被提示为 master
[root@vm16-22 ~]# ps -ef |grep 4501 root 18304 1 0 Mar09 ? 00:00:03 /usr/local/bin/redis-server 192.168.16.22:4501 root 41826 59263 0 00:07 pts/2 00:00:00 grep 4501 [root@vm16-22 ~]# kill 18304 [root@vm16-22 ~]# ps -ef |grep 4501 root 41871 59263 0 00:07 pts/2 00:00:00 grep 4501 ## 查看从服务是否被提升为新的 master ,如下所示,很明显已经被提升为master了 [root@vm16-22 ~]# redis-cli -h 192.168.16.24 -p 4501 info replication # Replication role:master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
好了,我们再次通过 twemproxy 获取 刚刚设置的两个key “huang” 和 “huangggggggggggggggggggggggggg"
## [root@vm16-23 ~]# redis-cli -h 192.168.16.23 -p 14555 get huang "dc" [root@vm16-23 ~]# redis-cli -h 192.168.16.23 -p 14555 get huangggggggggggggggggggggggggg (error) ERR Connection refused ## 很明显,刚刚存储在 4501 上面的key:huangggggggggggggggggggggggggg 已经获取不到了
为了让redis 达到高可用状态,我们还需要在 sentinel 发送故障转移的时候,将新的master ip和端口告知twemproxy ,并修改twemproxy的配置文件和重启nutcracker服务,下一步见分晓
4、sentinel 配置 client-reconfig-script 脚本
增加脚本 /data/nosql/sentinel/client-reconfig.sh ; 并添加执行权限 chmod +x /data/nosql/sentinel/client-reconfig.sh ; 脚本内容如下:
#!/bin/sh
### sentinel 触发执行此脚本时,会默认传递几个参数过来
### <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
#
monitor_name="$1" ##monitor master-group-name
master_old_ip="$4"
master_old_port="$5"
master_new_ip="$6"
master_new_port="$7"
twemproxy_name=$(echo $monitor_name |awk -F'_' '{print $1"_"$2}') ##注意
## 本文前面已经提了2次让大家记住一个地方 master-group-name ,我这边的命名规则 redis_14555_g1_4500 , 这里我就是为了获取redis_14555 , 因为twemproxy 的配置文件名用的是 redis_14555.yml ;
## 这里通过获取 master-group-name 来修改 twemproxy 的配置文件,这里定的一点规范而已
twemproxy_bin="/usr/local/twemproxy/sbin/nutcracker"
twemproxy_conf="/usr/local/twemproxy/conf/${twemproxy_name}.yml"
twemproxy_pid="/usr/local/twemproxy/conf/${twemproxy_name}.pid"
twemproxy_log="/usr/local/twemproxy/logs/${twemproxy_name}.log"
twemproxy_cmd="${twemproxy_bin} -c ${twemproxy_conf} -p ${twemproxy_pid} -o ${twemproxy_log} -v 11 -d"
## 将新的master 端口和ip 替换掉 twemproxy 配置文件中旧的master 信息
sed -i "s/${master_old_ip}:${master_old_port}/${master_new_ip}:${master_new_port}/" ${twemproxy_conf}
## kill 掉根据redis_14555.yml配置启动的nutcracker 进程 ,并重新启动
ps -ef |grep "${twemproxy_cmd}" |grep -v grep |awk '{print $2}'|xargs kill
${twemproxy_cmd}
sleep 1
ps -ef |grep "${twemproxy_cmd}" |grep -v grep
动态修改192.168.16.23:26379 sentinel 的配置,添加 client-reconfig-script 项
[root@vm16-23 sentinel]# redis-cli -h 192.168.16.23 -p 26379 sentinel set redis_14555_g1_4500 client-reconfig-script /data/nosql/sentinel/client-reconfig.sh OK [root@vm16-23 sentinel]# redis-cli -h 192.168.16.23 -p 26379 sentinel set redis_14555_g2_4501 client-reconfig-script /data/nosql/sentinel/client-reconfig.sh OK [root@vm16-23 sentinel]#
5、再次测试 twemproxy
我们确认一下 twemproxy的配置文件的 servers 信息:(/usr/local/twemproxy/conf/redis_14555.yml)
[root@vm16-23 sentinel]# cat /usr/local/twemproxy/conf/redis_14555.yml redis_14555: listen: 192.168.16.23:14555 hash: fnv1a_64 distribution: ketama auto_eject_hosts: true redis: true server_retry_timeout: 2000 server_failure_limit: 1 servers: - 192.168.16.22:4500:1 - 192.168.16.22:4501:1 ### 确定servers项的信息为 192.168.16.22:4500:1 和 192.168.16.22:4501:1
好了,在192.168.16.22服务器上,我们把 192.168.16.22:4501 master 干掉,直接kill 掉
[root@vm16-22 sentinel]# ps -ef |grep 4501 |grep -v grep root 61109 1 0 00:41 ? 00:00:00 /usr/local/bin/redis-server 192.168.16.22:4501 [root@vm16-22 sentinel]# kill 61109 [root@vm16-22 sentinel]# ps -ef |grep 4501 |grep -v grep
通过twemproxy 代理192.168.16.23:14555 获取key “huang” 和 “huangggggggggggggggggggggggggg"的值
[root@vm16-22 sentinel]# redis-cli -h 192.168.16.23 -p 14555 get huang "123" [root@vm16-22 sentinel]# redis-cli -h 192.168.16.23 -p 14555 get huangggggggggggggggggggggggggg "dccccccccccccccccccccccccccccccccccccc" [root@vm16-22 sentinel]# ## oh oh 获取到了
再次查看twemproxy 的配置文件的 servers 信息:(/usr/local/twemproxy/conf/redis_14555.yml)
[root@vm16-23 sentinel]# cat /usr/local/twemproxy/conf/redis_14555.yml redis_14555: listen: 192.168.16.23:14555 hash: fnv1a_64 distribution: ketama auto_eject_hosts: true redis: true server_retry_timeout: 2000 server_failure_limit: 1 servers: - 192.168.16.22:4500:1 - 192.168.16.24:4501:1
看到没有,看到没有,看到没有,192.168.16.22:4501 已经被替换为 192.168.16.24:4501 了。
twemproxy + redis + sentinel + 脚本 实现redis高可用架构(高可用集群)
twemproxy 有个缺点:如果 Twemproxy 的后端节点数量发生变化,Twemproxy 相同算法的的情况下,原来的数据必须重新处理分布,否则会存在找不到key值的情况