CAP、ACID、BASE理论及NWR实践策略详解
注意:架构师不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论,BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)。
电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
ACID是传统数据库常用的设计理念,追求强一致性模型。BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。
ACID和BASE代表了两种截然相反的设计哲学
在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此ACID和BASE又会结合使用。
5、NWR是CAP理论的一个具体实践性的取舍策略:
Amazon写了个论文,描述了一下如果取舍的具体策略,具体到副本数怎么设定,这就是NWR。
N = 副本数
W = 一次成功的写操作必须完成的写副本数
R = 一次成功的读操作需要读的副本数(是的,随便读一个副本是不行的,你必须读到一定数量的副本,再相互比较取最新的数据)
策略来说就有具体的公式可供运算,有两个:
W > N/2
W + R > N
我们结合Swift的设定,N=3,W=2,R=2(or 1),来看看这两个公式是什么意义。
分布式系统通常用来处理大并发请求的应用,很多请求大家同时来,有一堆在读,也有一堆想写。
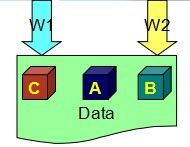
假设有一个数据拥有三副本,每个副本已经同步好,原来的值都是A
我们看看如果不需要满足公式让W小于3/2,也就是W=1的情况下会出现什么问题,W=1,意味着每个写的请求只要写完一个副本即可成功返回。
假设两个进程同时来更新这份数据,进程W1要把值改写成C,进程W2要把值改写成B,那就有可能出现下图的情形,两个进程各拿到一个副本改写,都认为自己的写操作是成功的,结果却留给系统三个不同的副本,这样就出现数据副本不一致的问题。
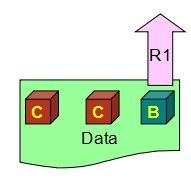
所以公式W> N/2, 实际上变成了一个写的锁,意味着只有写了过半数副本的才算写成功,拿不到的就返回失败,解决了竞争的问题。如下图,W1的会话成功,W2的会话就返回失败。

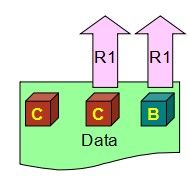
W> N/2,同时意味着不需要把所有的副本都写完,未完成的留给系统自己后台慢慢同步,那这个时候问题就来了,一个新的会话过来读数据的时候,分配到的副本有可能是没来得及更新的。这时候R1读回去的就是过时的数据B,而非最新的数据C
第2个公式变形下就是R> N-W,R=2就避免正好倒霉读到没更新的那一个。这样读回去C和B两个数据,再比较后取最新的C。所以W+R> N 能够保证每个读的请求至少读到一份最新的数据,
所以你也许已经琢磨出来,这两个公式更加强调一致性,在可用性上是有所保留的。
当然NWR还可能取其他值,不同的取值代表了不同的倾向。如果设定N=3, W=3, R=1,那么强调的是一致性,写数据的时候一定要把所有副本都刷新,杜绝中间状态,这样一致性得到很好保证;如果N=3, W=1, R=1,那强调的是可用性,这种情况下一致性是被牺牲掉了,所以上面两个保证一致性的公式在这种情况下就不再适用。之所以可用性提高是因为读和写都放低了要求,只要完成一个副本即可,这样完成时间降低,响应速度是更快的。
N=3, W=2, R=2是一种折中的策略。其实Amazon的Dynamo就是采用的这个参数,据说Swift是照搬S3的。
所以回到Swift的副本设定来看,swift的NWR值是可调的,有两种配置,一种是标准的N3W2R2,但是实际上你也可以使用N3W2R1,这个更实用点。在这种配置下,虽然一个数据拥有三副本,但是容错上读写是不一样的。网络断线,硬盘故障等意外造成一个副本失效时, 系统仍然可读可写,但两个副本失效时,受影响的这部分数据系统就变成只读,无法再写了。
CAP理论和NWR策略在大规模系统下是比较合理的,除了被用来设计分布式存储之外,也用来设计分布式数据库,比如很热的NOSQL。另外,这个理论问世已经不短的时间,也经常看到有人发文要挑战他,也有一些吐槽等等,那个是另外的话题,这里就不再继续了。
6、总结NWR:
R>N/2:表示一次读操作成功,必须是完成超过半数以上的副本读操作(不然有可能读到不一致数据或者出现问题没法根据票数多来进行选举)
R>N-W:表示一次成功的读操作,至少要完成超过所有副本数N减去所有写成功W份数的差值。这样即能保证每个读请求至少能够读到一份最新数据。
N=3,W=3,R=1:总共副本数为3,强调了写的强一致性,写数据的时候一定要把所有副本刷新才能算写成功,杜绝中间状态,这样一致性达到了很好的保证。
N=3,W=1,R=1:总共副本数为3,这样一致性牺牲了,因为读写都放低了要求,所以提高了系统可用性。
swift及Amazon采用的默认策略:
N=3, W=2, R=2:这样保证了每次读写必须完成半数以上副本才能算成功,算是折中方案。