【Oracle】RAC11gR2 Grid启动顺序及启动故障诊断思路
从11gR2开始,Oracle RAC的架构有了比较大的变化,集群层面相交于之前的版本有了比较大的变动,原来的rac架构基本上属于cssd、crsd、evmd三大光秃秃的主干进程,日志数量较少,对于rac无法启动原因,采用最原始的方法逐一查看各个进程的日志也可找到无法启动的原因。然而从11gR2之后,集群层发生了比较大的变动,以下是$GRID_HOME/log/rac1/下的目录情况:
[grid@rac1 rac1]$ ls
acfs acfsrepl acfssec agent client crfmond cssd cvu evmd gnsd mdnsd racg
acfslog acfsreplroot admin alertrac1.log crflogd crsd ctssd diskmon gipcd gpnpd ohasd srvm
可以看到在这个目录中的文件夹非常多,在rac无法启动的情况下,如果去所有日志下查看无法启动的原因无疑效率极低。所以我们需要一个比较明确的诊断思路。
OK,接下来进入正题,希望可以为大家的日常诊断提供帮助。
第一步,在诊断Grid无法启动的情况之前我们需要先了解11gR2中Grid的启动流程,下面这张图比较清晰的说明了现在Grid的启动顺序:
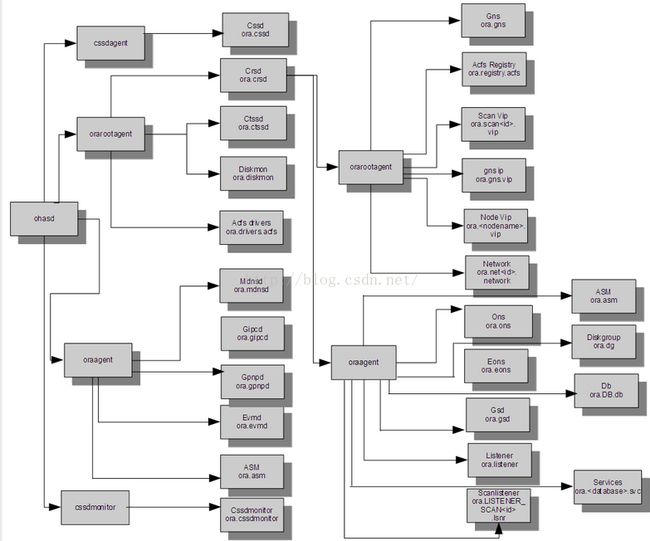
从图中我们可以看到,相比的原来Oracle 10g的集群架构,11gR2有了比较大的改动。具体的进程作用在这里不再赘述,不了解的可以自己去恶补一下,这里只说进程启动顺序相关的内容。在启动集群的过程中首先启动的是ohasd进程,在ohasd进程启动之后会启动4个agent:
1.cssd agent
以root用户权限启动,负责启动cssd进程。
2.orarootagent
以root用户权限启动,负责启动以下这些守护进程:crsd进程、ctssd进程、Diskmon进程、acfs进程。这些进程也都是以root用户权限启动。
3.oraagent
以grid用户权限启动,负责mdnsd进程、gipcd进程、gpnpd进程、evmd进程、asm进程(11gR2之后的asm在集群中被放置到了更底层,和之前版本区别较大)。
4.cssdmonitor。
以root用户权限启动,负责cssdmonitor进程的启动。
从图中我们可以看到之后又由crsd进程负责启动了两个agent:orarootagent和oraagent(最后的进程中我们可以看到两个oraagent进程,就是之前启动的那个加上这个),之后再由orarootagent和oraagent去负责启动之后的用户资源,进程启动到这里我认为grid底层启动完毕,之后再由orarootagent和oraagent启动的资源出现的问题不再本文的讨论范围内了。
第二步,我们已经对grid的进程启动顺序进行了梳理,之后对于grid无法启动的诊断也就变得简单。我们只要通过ps -ef|grep /oracle/app/grid/product/11.2.0($GRID_HOME)就可以了解到grid已经启动到哪一步,哪些进程已经启动,哪些进程还未启动,卡在了哪个进程上,这样我们就能快速找到应该查看的日志。比如crsd进程没有启动,我们就可以通过查看$GRID_HOME/log/rac1/crsd目录下的crsd.log来进行查看,究竟在crsd进程启动过程中遭遇了哪些错误导致进程无法正常启动。
举例:
[grid@rac1 crsd]$ ps -ef|grep /oracle
root 15235 1 0 14:12 ? 00:00:06 /oracle/app/grid/product/11.2.0/bin/ohasd.bin reboot
grid 15356 1 0 14:12 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/oraagent.bin
grid 15367 1 0 14:12 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/mdnsd.bin
grid 15378 1 0 14:12 ? 00:00:02 /oracle/app/grid/product/11.2.0/bin/gpnpd.bin
grid 15388 1 2 14:12 ? 00:00:19 /oracle/app/grid/product/11.2.0/bin/gipcd.bin
root 15390 1 0 14:12 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/orarootagent.bin
root 15403 1 0 14:12 ? 00:00:08 /oracle/app/grid/product/11.2.0/bin/osysmond.bin
root 15477 1 0 14:12 ? 00:00:02 /oracle/app/grid/product/11.2.0/bin/ologgerd -M -d /oracle/app/grid/product/11.2.0/crf/db/rac1
root 15637 1 0 14:22 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/cssdmonitor
root 15665 1 0 14:22 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/cssdagent
grid 15676 1 0 14:22 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/ocssd.bin
grid 15730 13826 0 14:27 pts/1 00:00:00 grep /oracle
从以上的输出我们就可以看到,此时grid无法启动的原因在于cssd进程无法启动,所以我们直接查看ocssd.log,查看无法启动的原因,在日志中找到以下内容:
2016-05-09 14:30:26.476: [ CSSD][1104030016]clssnmvDHBValidateNcopy: node 2, rac2, has a disk HB, but no network HB, DHB has rcfg 358258450, wrtcnt, 177436, LATS 10923264, lastSeqNo 177435, uniqueness 1462763679, timestamp 1462775426/10874194
可以看到是因为私网出现了问题,导出有disk HB,而没有network HB,修复私网问题后,集群可以正常启动。
第三步,附送一篇MOS文章:ID 1623340.1,里边罗列了grid各个进程无法启动的常见原因以及对应的日志:
1.1.1. 集群状态
查询集群和守护进程的状态:
$GRID_HOME/bin/crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
$GRID_HOME/bin/crsctl stat res -t -init
--------------------------------------------------------------------------------
NAME TARGET STATE SERVER STATE_DETAILS
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.asm
1 ONLINE ONLINE rac1 Started
ora.crsd
1 ONLINE ONLINE rac1
ora.cssd
1 ONLINE ONLINE rac1
ora.cssdmonitor
1 ONLINE ONLINE rac1
ora.ctssd
1 ONLINE ONLINE rac1 OBSERVER
ora.diskmon
1 ONLINE ONLINE rac1
ora.drivers.acfs
1 ONLINE ONLINE rac1
ora.evmd
1 ONLINE ONLINE rac1
ora.gipcd
1 ONLINE ONLINE rac1
ora.gpnpd
1 ONLINE ONLINE rac1
ora.mdnsd
1 ONLINE ONLINE rac1
对于11.2.0.2 和以上的版本,会有以下两个额外的进程:
ora.cluster_interconnect.haip
1 ONLINE ONLINE rac1
ora.crf
1 ONLINE ONLINE rac1
对于11.2.0.3 以上的非EXADATA的系统,ora.diskmon会处于offline的状态,如下:
ora.diskmon
1 OFFLINE OFFLINE rac1
对于 12c 以上的版本, 会出现ora.storage资源:
ora.storage
1 ONLINE ONLINE racnode1 STABLE
如果守护进程 offline 我们可以通过以下命令启动:
$GRID_HOME/bin/crsctl start res ora.crsd -init
1.1.2. 问题 1: OHASD 无法启动
由于 ohasd.bin 的责任是直接或者间接的启动集群所有的其它进程,所以只有这个进程正常启动了,其它的进程才能起来,如果 ohasd.bin 的进程没有起来,当我们检查资源状态的时候会报错 CRS-4639 (Could not contact Oracle High Availability Services); 如果 ohasd.bin 已经启动了,而再次尝试启时,错误 CRS-4640 会出现;如果它启动失败了,那么我们会看到以下的错误信息:
CRS-4124: Oracle High Availability Services startup failed.
CRS-4000: Command Start failed, or completed with errors.
自动启动 ohasd.bin 依赖于以下的配置:
1. 操作系统配置了正确的 run level:
OS 需要在 CRS 启动之前设置成指定的 run level 来确保 CRS 的正常启动。
我们可以通过以下方式找到 CRS 需要 OS 设置的 run level:
cat /etc/inittab|grep init.ohasd
h1:35:respawn:/etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
以上例子展示了,CRS 需要 OS 运行在 run level 3 或 5;请注意,由于操作系统的不同,CRS 启动需要的 OS 的 run level 也会不同。
找到当前 OS 正在运行的 run level:
who -r
2. "init.ohasd run" 启动
在 Linux/Unix 平台上,由于"init.ohasd run" 是配置在 /etc/inittab中,进程 init(进程id 1,linux,Solars和HP-UX上为/sbin/init ,Aix上为/usr/sbin/init)会启动并且产生"init.ohasd run"进程,如果这个过程失败了,就不会有"init.ohasd run"的启动和运行,ohasd.bin 也是无法启动的:
ps -ef|grep init.ohasd|grep -v grep
root 2279 1 0 18:14 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
注意:Oracle Linux (OL6)以及 Red Hat Linux 6 (RHEL6) 已经不再支持 inittab 了,所以 init.ohasd 会被配置在 /etc/init 中,并被 /etc/init 启动,尽管如此,我们还是应该能看到进程 "/etc/init.d/init.ohasd run" 被启动;
如果任何 rc Snncommand 的脚本(在 rcn.d 中,如 S98gcstartup)在启动的过程中挂死,此时 init 的进程可能无法启动"/etc/init.d/init.ohasd run";您需要寻求 OS 厂商的帮助,找到为什么 Snncommand 脚本挂死或者无法正常启动的原因;
错误"[ohasd(<pid>)] CRS-0715:Oracle High Availability Service has timed out waiting for init.ohasd to be started." 可能会在 init.ohasd 无法在指定时间内启动后出现
如果系统管理员无法在短期内找到 init.ohasd 无法启动的原因,以下办法可以作为一个临时的解决办法:
cd <location-of-init.ohasd>
nohup ./init.ohasd run &
3. Clusterware 自动启动;--自动启动默认是开启的
默认情况下 CRS 自动启动是开启的,我们可以通过以下方式开启:
$GRID_HOME/bin/crsctl enable crs
检查这个功能是否被开启:
$GRID_HOME/bin/crsctl config crs
如果以下信息被输出在OS的日志中
Feb 29 16:20:36 racnode1 logger: Oracle Cluster Ready Services startup disabled.
Feb 29 16:20:36 racnode1 logger: Could not access /var/opt/oracle/scls_scr/racnode1/root/ohasdstr
原因是由于这个文件不存在或者不可访问,产生这个问题的原因一般是人为的修改或者是打 GI 补丁的过程中使用了错误的 opatch (如:使用 Solaris 平台上的 opatch 在 Linux 上打补丁)
4. syslogd 启动并且 OS 能够执行 init 脚本 S96ohasd
节点启动之后,OS 可能停滞在一些其它的 Snn 的脚本上,所以可能没有机会执行到脚本 S96ohasd;如果是这种情况,我们不会在 OS 日志中看到以下信息
(aix /var/adm/syslog linux /var/log/messages)
Jan 20 20:46:51 rac1 logger: Oracle HA daemon is enabled for autostart.
如果在 OS 日志里看不到上面的信息,还有一种可能是 syslogd((/usr/sbin/syslogd)没有被完全启动。GRID 在这种情况下也是无法正常启动的,这种情况不适用于 AIX 的平台。
为了了解 OS 启动之后是否能够执行 S96ohasd 脚本,可以按照以下的方法修改该脚本:
From:
case `$CAT $AUTOSTARTFILE` in
enable*)
$LOGERR "Oracle HA daemon is enabled for autostart."
To:
case `$CAT $AUTOSTARTFILE` in
enable*)
/bin/touch /tmp/ohasd.start."`date`"
$LOGERR "Oracle HA daemon is enabled for autostart."
重启节点后,如果您没有看到文件 /tmp/ohasd.start.timestamp 被创建,那么就是说 OS 停滞在其它的 Snn 的脚本上。如果您能看到 /tmp/ohasd.start.timestamp 生成了,但是"Oracle HA daemon is enabled for autostart"没有写入到messages 文件里,就是 syslogd 没有被完全启动了。以上的两种情况,您都需要寻求系统管理员的帮助,从 OS 的层面找到问题的原因,对于后一种情况,有个临时的解决办法是“休眠”2分钟, 按照以下的方法修改 ohasd 脚本:
From:
case `$CAT $AUTOSTARTFILE` in
enable*)
$LOGERR "Oracle HA daemon is enabled for autostart."
To:
case `$CAT $AUTOSTARTFILE` in
enable*)
/bin/sleep 120
$LOGERR "Oracle HA daemon is enabled for autostart."
5. GRID_HOME 所在的文件系统在执行初始化脚本 S96ohasd 的时候在线;正常情况下一旦 S96ohasd 执行结束,我们会在 OS message 里看到以下信息:
Jan 20 20:46:51 rac1 logger: Oracle HA daemon is enabled for autostart.
..
Jan 20 20:46:57 rac1 logger: exec /ocw/grid/perl/bin/perl -I/ocw/grid/perl/lib /ocw/grid/bin/crswrapexece.pl /ocw/grid/crs/install/s_crsconfig_rac1_env.txt /ocw/grid/bin/ohasd.bin "reboot"
如果您只看到了第一行,没有看到最后一行的信息,很可能是 GRID_HOME 所在的文件系统在脚本 S96ohasd 执行的时候还没有正常挂载。
6. Oracle Local Registry (OLR, $GRID_HOME/cdata/${HOSTNAME}.olr) 有效并可以正常读写
ls -l $GRID_HOME/cdata/*.olr
-rw------- 1 root oinstall 272756736 Feb 2 18:20 rac1.olr
如果 OLR 是不可读写的或者损坏的,我们会在 ohasd.log 中看到以下的相关信息
..
2010-01-24 22:59:10.470: [ default][1373676464] Initializing OLR
2010-01-24 22:59:10.472: [ OCROSD][1373676464]utopen:6m':failed in stat OCR file/disk /ocw/grid/cdata/rac1.olr, errno=2, os err string=No such file or directory
2010-01-24 22:59:10.472: [ OCROSD][1373676464]utopen:7:failed to open any OCR file/disk, errno=2, os err string=No such file or directory
2010-01-24 22:59:10.473: [ OCRRAW][1373676464]proprinit: Could not open raw device
2010-01-24 22:59:10.473: [ OCRAPI][1373676464]a_init:16!: Backend init unsuccessful : [26]
2010-01-24 22:59:10.473: [ CRSOCR][1373676464] OCR context init failure. Error: PROCL-26: Error while accessing the physical storage Operating System error [No such file or directory] [2]
2010-01-24 22:59:10.473: [ default][1373676464] OLR initalization failured, rc=26
2010-01-24 22:59:10.474: [ default][1373676464]Created alert : (:OHAS00106:) : Failed to initialize Oracle Local Registry
2010-01-24 22:59:10.474: [ default][1373676464][PANIC] OHASD exiting; Could not init OLR
或者
..
2010-01-24 23:01:46.275: [ OCROSD][1228334000]utread:3: Problem reading buffer 1907f000 buflen 4096 retval 0 phy_offset 102400 retry 5
2010-01-24 23:01:46.275: [ OCRRAW][1228334000]propriogid:1_1: Failed to read the whole bootblock. Assumes invalid format.
2010-01-24 23:01:46.275: [ OCRRAW][1228334000]proprioini: all disks are not OCR/OLR formatted
2010-01-24 23:01:46.275: [ OCRRAW][1228334000]proprinit: Could not open raw device
2010-01-24 23:01:46.275: [ OCRAPI][1228334000]a_init:16!: Backend init unsuccessful : [26]
2010-01-24 23:01:46.276: [ CRSOCR][1228334000] OCR context init failure. Error: PROCL-26: Error while accessing the physical storage
2010-01-24 23:01:46.276: [ default][1228334000] OLR initalization failured, rc=26
2010-01-24 23:01:46.276: [ default][1228334000]Created alert : (:OHAS00106:) : Failed to initialize Oracle Local Registry
2010-01-24 23:01:46.277: [ default][1228334000][PANIC] OHASD exiting; Could not init OLR
或者
..
2010-11-07 03:00:08.932: [ default][1] Created alert : (:OHAS00102:) : OHASD is not running as privileged user
2010-11-07 03:00:08.932: [ default][1][PANIC] OHASD exiting: must be run as privileged user
或者
ohasd.bin comes up but output of "crsctl stat res -t -init"shows no resource, and "ocrconfig -local -manualbackup" fails
或者
..
2010-08-04 13:13:11.102: [ CRSPE][35] Resources parsed
2010-08-04 13:13:11.103: [ CRSPE][35] Server [] has been registered with the PE data model
2010-08-04 13:13:11.103: [ CRSPE][35] STARTUPCMD_REQ = false:
2010-08-04 13:13:11.103: [ CRSPE][35] Server [] has changed state from [Invalid/unitialized] to [VISIBLE]
2010-08-04 13:13:11.103: [ CRSOCR][31] Multi Write Batch processing...
2010-08-04 13:13:11.103: [ default][35] Dump State Starting ...
..
2010-08-04 13:13:11.112: [ CRSPE][35] SERVERS:
:VISIBLE:address{{Absolute|Node:0|Process:-1|Type:1}}; recovered state:VISIBLE. Assigned to no pool
------------- SERVER POOLS:
Free [min:0][max:-1][importance:0] NO SERVERS ASSIGNED
2010-08-04 13:13:11.113: [ CRSPE][35] Dumping ICE contents...:ICE operation count: 0
2010-08-04 13:13:11.113: [ default][35] Dump State Done.
解决办法就是使用下面的命令,恢复一个好的备份 "ocrconfig -local -restore <ocr_backup_name>"。
默认情况下,OLR 在系统安装结束后会自动的备份在 $GRID_HOME/cdata/$HOST/backup_$TIME_STAMP.olr 。
7. ohasd.bin可以正常的访问到网络的 socket 文件:
2010-06-29 10:31:01.570: [ COMMCRS][1206901056]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=procr_local_conn_0_PROL))
2010-06-29 10:31:01.571: [ OCRSRV][1217390912]th_listen: CLSCLISTEN failed clsc_ret= 3, addr= [(ADDRESS=(PROTOCOL=ipc)(KEY=procr_local_conn_0_PROL))]
2010-06-29 10:31:01.571: [ OCRSRV][3267002960]th_init: Local listener did not reach valid state
在 Grid Infrastructure 环境中,和 ohasd 有关的 socket 文件属主应该是 root 用户,但是在 Oracle Restart 的环境中,他们应该是属于 grid 用户的,关于更多的关于网络 socket 文件权限和属主,请参考章节"网络 socket 文件,属主和权限" 给出的例子.
8. ohasd.bin 能够访问日志文件的位置:
OS messages/syslog 显示以下信息:
Feb 20 10:47:08 racnode1 OHASD[9566]: OHASD exiting; Directory /ocw/grid/log/racnode1/ohasd not found.
请参考章节"日志位置, 属主和权限"部分的例子,并确定这些必要的目录是否有丢失的,并且是按照正确的权限和属主创建的。
9. 节点启动后,在 SUSE Linux 的系统上,ohasd 可能无法启动,此问题请参考 note 1325718.1 - OHASD not Starting After Reboot on SLES
10. OHASD 无法启动,使用 "ps -ef| grep ohasd.bin" 显示 ohasd.bin 的进程已经启动,但是 $GRID_HOME/log/<node>/ohasd/ohasd.log 在好几分钟之后都没有任何信息更新,使用 OS 的 truss 工具 可以看到该进程一致在循环的执行关闭从未被打开的文件句柄的操作:
..
15058/1: 0.1995 close(2147483646) Err#9 EBADF
15058/1: 0.1996 close(2147483645) Err#9 EBADF
..
通过 ohasd.bin 的 Call stack ,可以看到以下信息:
_close sclssutl_closefiledescriptors main ..
这是由于 bug 11834289 导致的, 该问题在 11.2.0.3 和之上的版本已经被修复,该 bug 的其它症状还有:集群的进程无法启动,而且做 call stack 和 truss 查看的时候也会看到相同的情况(循环的执行 OS 函数 "close") . 如果该 bug 发生在启动其它的资源时,我们会看到错误信息: "CRS-5802: Unable to start the agent process" 提示。
11. 其它的一些潜在的原因和解决办法请参见 note 1069182.1 - OHASD Failed to Start: Inappropriate ioctl for device
12. ohasd.bin 正常启动,但是, "crsctl check crs" 只显示以下一行信息:
CRS-4638: Oracle High Availability Services is online
并且命令 "crsctl stat res -p -init" 无法显示任何信息
这个问题是由于 OLR 损坏导致的,请参考 note 1193643.1 进行恢复。
13. 如果 ohasd 仍然无法启动,请参见 ohasd 的日志 <grid-home>/log/<nodename>/ohasd/ohasd.log 和 ohasdOUT.log 来获取更多的信息;
1.1.3. 问题 2: OHASD Agents 未启动
OHASD.BIN 会启动 4 个 agents/monitors 来启动其它的资源:
oraagent: 负责启动 ora.asm, ora.evmd, ora.gipcd, ora.gpnpd, ora.mdnsd 等
orarootagent: 负责启动 ora.crsd, ora.ctssd, ora.diskmon, ora.drivers.acfs 等
cssdagent / cssdmonitor: 负责启动 ora.cssd(对应 ocssd.bin) 和 ora.cssdmonitor(对应 cssdmonitor)
如果 ohasd.bin 不能正常地启动以上任何一个 agents,集群都无法运行在正常的状态。
1. 通常情况下,agents 无法启动的原因是 agent 的日志或者日志所在的目录没有正确设置属主和权限。
关于日志文件和文件夹的权限和属主设置,请参见章节 "日志文件位置, 属主和权限" 中的介绍。
2. 如果 agent 的二进制文件(oraagent.bin 或者 orarootagent.bin 等)损坏, agent 也将无法启动,从而导致相关的资源也无法启动:
2011-05-03 11:11:13.189
[ohasd(25303)]CRS-5828:Could not start agent '/ocw/grid/bin/orarootagent_grid'. Details at (:CRSAGF00130:) {0:0:2} in /ocw/grid/log/racnode1/ohasd/ohasd.log.
2011-05-03 12:03:17.491: [ AGFW][1117866336] {0:0:184} Created alert : (:CRSAGF00130:) : Failed to start the agent /ocw/grid/bin/orarootagent_grid
2011-05-03 12:03:17.491: [ AGFW][1117866336] {0:0:184} Agfw Proxy Server sending the last reply to PE for message:RESOURCE_START[ora.diskmon 1 1] ID 4098:403
2011-05-03 12:03:17.491: [ AGFW][1117866336] {0:0:184} Can not stop the agent: /ocw/grid/bin/orarootagent_grid because pid is not initialized
..
2011-05-03 12:03:17.492: [ CRSPE][1128372576] {0:0:184} Fatal Error from AGFW Proxy: Unable to start the agent process
2011-05-03 12:03:17.492: [ CRSPE][1128372576] {0:0:184} CRS-2674: Start of 'ora.diskmon' on 'racnode1' failed
..
2011-06-27 22:34:57.805: [ AGFW][1131669824] {0:0:2} Created alert : (:CRSAGF00123:) : Failed to start the agent process: /ocw/grid/bin/cssdagent Category: -1 Operation: fail Loc: canexec2 OS error: 0 Other : no exe permission, file [/ocw/grid/bin/cssdagent]
2011-06-27 22:34:57.805: [ AGFW][1131669824] {0:0:2} Created alert : (:CRSAGF00126:) : Agent start failed
..
2011-06-27 22:34:57.806: [ AGFW][1131669824] {0:0:2} Created alert : (:CRSAGF00123:) : Failed to start the agent process: /ocw/grid/bin/cssdmonitor Category: -1 Operation: fail Loc: canexec2 OS error: 0 Other : no exe permission, file [/ocw/grid/bin/cssdmonitor]
解决办法: 您可以和正常节点上的 agent 文件进行比较,并且恢复一个好的副本回来。
1.1.4. 问题 3: OCSSD.BIN 无法启动
cssd.bin 的正常启动依赖于以下几个必要的条件:
1. GPnP profile 可正常读写 - gpnpd 需要完全正常启动来为profile服务。
如果 ocssd.bin 能够正常的获取 profile,通常情况下,我们会在 ocssd.log 中看到以下类似的信息:
2010-02-02 18:00:16.251: [ GPnP][408926240]clsgpnpm_exchange: [at clsgpnpm.c:1175] Calling "ipc://GPNPD_rac1", try 4 of 500...
2010-02-02 18:00:16.263: [ GPnP][408926240]clsgpnp_profileVerifyForCall: [at clsgpnp.c:1867] Result: (87) CLSGPNP_SIG_VALPEER. Profile verified. prf=0x165160d0
2010-02-02 18:00:16.263: [ GPnP][408926240]clsgpnp_profileGetSequenceRef: [at clsgpnp.c:841] Result: (0) CLSGPNP_OK. seq of p=0x165160d0 is '6'=6
2010-02-02 18:00:16.263: [ GPnP][408926240]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2186] Result: (0) CLSGPNP_OK. Successful get-profile CALL to remote "ipc://GPNPD_rac1" disco ""
否则,我们会看到以下信息显示在 ocssd.log 中。
2010-02-03 22:26:17.057: [ GPnP][3852126240]clsgpnpm_connect: [at clsgpnpm.c:1100] GIPC gipcretConnectionRefused (29) gipcConnect(ipc-ipc://GPNPD_rac1)
2010-02-03 22:26:17.057: [ GPnP][3852126240]clsgpnpm_connect: [at clsgpnpm.c:1101] Result: (48) CLSGPNP_COMM_ERR. Failed to connect to call url "ipc://GPNPD_rac1"
2010-02-03 22:26:17.057: [ GPnP][3852126240]clsgpnp_getProfileEx: [at clsgpnp.c:546] Result: (13) CLSGPNP_NO_DAEMON. Can't get GPnP service profile from local GPnP daemon
2010-02-03 22:26:17.057: [ default][3852126240]Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running).
2010-02-03 22:26:17.057: [ CSSD][3852126240]clsgpnp_getProfile failed, rc(13)
2. Voting Disk 可以正常读写
在 11gR2 的版本中, ocssd.bin 通过 GPnP profile 中的记录获取 Voting disk 的信息, 如果没有足够多的选举盘是可读写的,那么 ocssd.bin 会终止掉自己。
2010-02-03 22:37:22.212: [ CSSD][2330355744]clssnmReadDiscoveryProfile: voting file discovery string(/share/storage/di*)
..
2010-02-03 22:37:22.227: [ CSSD][1145538880]clssnmvDiskVerify: Successful discovery of 0 disks
2010-02-03 22:37:22.227: [ CSSD][1145538880]clssnmCompleteInitVFDiscovery: Completing initial voting file discovery
2010-02-03 22:37:22.227: [ CSSD][1145538880]clssnmvFindInitialConfigs: No voting files found
2010-02-03 22:37:22.228: [ CSSD][1145538880]###################################
2010-02-03 22:37:22.228: [ CSSD][1145538880]clssscExit: CSSD signal 11 in thread clssnmvDDiscThread
如果所有节点上的 ocssd.bin 因为以下错误无法启动,这是因为 voting file 正在被修改:
2010-05-02 03:11:19.033: [ CSSD][1197668093]clssnmCompleteInitVFDiscovery: Detected voting file add in progress for CIN 0:1134513465:0, waiting for configuration to complete 0:1134513098:0
解决的办法是,参照 note 1364971.1 中的步骤,以 exclusive 模式启动 ocssd.bin。
如果选举盘的位置是非 ASM 的设备,它的权限和属主应该是如下显示:
-rw-r----- 1 ogrid oinstall 21004288 Feb 4 09:13 votedisk1
3. 网络功能是正常的,并且域名解析能够正常工作:
如果 ocssd.bin 无法正常的绑定到任何网络上,我们会在 ocssd.log 中看到以下类似的日志信息:
2010-02-03 23:26:25.804: [GIPCXCPT][1206540320]gipcmodGipcPassInitializeNetwork: failed to find any interfaces in clsinet, ret gipcretFail (1)
2010-02-03 23:26:25.804: [GIPCGMOD][1206540320]gipcmodGipcPassInitializeNetwork: EXCEPTION[ ret gipcretFail (1) ] failed to determine host from clsinet, using default
..
2010-02-03 23:26:25.810: [ CSSD][1206540320]clsssclsnrsetup: gipcEndpoint failed, rc 39
2010-02-03 23:26:25.811: [ CSSD][1206540320]clssnmOpenGIPCEndp: failed to listen on gipc addr gipc://rac1:nm_eotcs- ret 39
2010-02-03 23:26:25.811: [ CSSD][1206540320]clssscmain: failed to open gipc endp
如果私网上出现了联通性的故障(包含多播功能关闭),我们会在 ocssd.log 中看到以下类似的日志信息:
2010-09-20 11:52:54.014: [ CSSD][1103055168]clssnmvDHBValidateNCopy: node 1, racnode1, has a disk HB, but no network HB, DHB has rcfg 180441784, wrtcnt, 453, LATS 328297844, lastSeqNo 452, uniqueness 1284979488, timestamp 1284979973/329344894
2010-09-20 11:52:54.016: [ CSSD][1078421824]clssgmWaitOnEventValue: after CmInfo State val 3, eval 1 waited 0
.. >>>> after a long delay
2010-09-20 12:02:39.578: [ CSSD][1103055168]clssnmvDHBValidateNCopy: node 1, racnode1, has a disk HB, but no network HB, DHB has rcfg 180441784, wrtcnt, 1037, LATS 328883434, lastSeqNo 1036, uniqueness 1284979488, timestamp 1284980558/329930254
2010-09-20 12:02:39.895: [ CSSD][1107286336]clssgmExecuteClientRequest: MAINT recvd from proc 2 (0xe1ad870)
2010-09-20 12:02:39.895: [ CSSD][1107286336]clssgmShutDown: Received abortive shutdown request from client.
2010-09-20 12:02:39.895: [ CSSD][1107286336]###################################
2010-09-20 12:02:39.895: [ CSSD][1107286336]clssscExit: CSSD aborting from thread GMClientListener
2010-09-20 12:02:39.895: [ CSSD][1107286336]###################################
验证网络是否正常,请参见:note 1054902.1
$GRID_HOME/bin/lsnodes -n
racnode1 1
racnode1 0
如果第三方的集群管理软件没有完全正常启动,我们在 ocssd.log 中看到以下类似的日志信息:
2010-08-30 18:28:13.207: [ CSSD][36]clssnm_skgxninit: skgxncin failed, will retry
2010-08-30 18:28:14.207: [ CSSD][36]clssnm_skgxnmon: skgxn init failed
2010-08-30 18:28:14.208: [ CSSD][36]###################################
2010-08-30 18:28:14.208: [ CSSD][36]clssscExit: CSSD signal 11 in thread skgxnmon
未安装集群管理软件之前,请使用 grid 用户执行以下操作验证:
$INSTALL_SOURCE/install/lsnodes -v
5. 在错误的 GRID_HOME 下执行命令"crsctl"
命令"crsctl" 必须在正确的 GRID_HOME 下执行,才能正常启动其它进程,否则我们会看到以下的错误信息提示:
2012-11-14 10:21:44.014: [ CSSD][1086675264]ASSERT clssnm1.c 3248
2012-11-14 10:21:44.014: [ CSSD][1086675264](:CSSNM00056:)clssnmvStartDiscovery: Terminating because of the release version(11.2.0.2.0) of this node being lesser than the active version(11.2.0.3.0) that the cluster is at
2012-11-14 10:21:44.014: [ CSSD][1086675264]###################################
2012-11-14 10:21:44.014: [ CSSD][1086675264]clssscExit: CSSD aborting from thread clssnmvDDiscThread#
1.1.5. 问题 4: CRSD.BIN 无法启动
crsd.bin 的正常启动依赖于以下几个必要的条件:
1. ocssd 已经完全正常启动
如果 ocssd.bin 没有完全正常启动,我们会在 crsd.log 中看到以下提示信息:
2010-02-03 22:37:51.638: [ CSSCLNT][1548456880]clssscConnect: gipc request failed with 29 (0x16)
2010-02-03 22:37:51.638: [ CSSCLNT][1548456880]clsssInitNative: connect failed, rc 29
2010-02-03 22:37:51.639: [ CRSRTI][1548456880] CSS is not ready. Received status 3 from CSS. Waiting for good status ..
2. OCR 可以正常读写
如果 OCR 保存在 ASM 中,那么 ora.asm 资源(ASM 实例) 必须已经启动而且 OCR 所在的磁盘组必须已经被挂载,否则我们在 crsd.log 会看到以下的类似信息:
2010-02-03 22:22:55.186: [ OCRASM][2603807664]proprasmo: Error in open/create file in dg [GI]
[ OCRASM][2603807664]SLOS : SLOS: cat=7, opn=kgfoAl06, dep=15077, loc=kgfokge
ORA-15077: could not locate ASM instance serving a required diskgroup
2010-02-03 22:22:55.189: [ OCRASM][2603807664]proprasmo: kgfoCheckMount returned [7]
2010-02-03 22:22:55.189: [ OCRASM][2603807664]proprasmo: The ASM instance is down
2010-02-03 22:22:55.190: [ OCRRAW][2603807664]proprioo: Failed to open [+GI]. Returned proprasmo() with [26]. Marking location as UNAVAILABLE.
2010-02-03 22:22:55.190: [ OCRRAW][2603807664]proprioo: No OCR/OLR devices are usable
2010-02-03 22:22:55.190: [ OCRASM][2603807664]proprasmcl: asmhandle is NULL
2010-02-03 22:22:55.190: [ OCRRAW][2603807664]proprinit: Could not open raw device
2010-02-03 22:22:55.190: [ OCRASM][2603807664]proprasmcl: asmhandle is NULL
2010-02-03 22:22:55.190: [ OCRAPI][2603807664]a_init:16!: Backend init unsuccessful : [26]
2010-02-03 22:22:55.190: [ CRSOCR][2603807664] OCR context init failure. Error: PROC-26: Error while accessing the physical storage ASM error [SLOS: cat=7, opn=kgfoAl06, dep=15077, loc=kgfokge
ORA-15077: could not locate ASM instance serving a required diskgroup
] [7]
2010-02-03 22:22:55.190: [ CRSD][2603807664][PANIC] CRSD exiting: Could not init OCR, code: 26
注意:在11.2 的版本中 ASM 会比 crsd.bin 先启动,并且会把含有 OCR 的磁盘组自动挂载。
如果您的 OCR 在非 ASM 的存储中,该文件的属主和权限如下:
-rw-r----- 1 root oinstall 272756736 Feb 3 23:24 ocr
如果 OCR 是在非 ASM 的存储中,并且不能被正常访问,在 crsd.log 会看到以下的类似信息
2010-02-03 23:14:33.583: [ OCROSD][2346668976]utopen:7:failed to open any OCR file/disk, errno=2, os err string=No such file or directory
2010-02-03 23:14:33.583: [ OCRRAW][2346668976]proprinit: Could not open raw device
2010-02-03 23:14:33.583: [ default][2346668976]a_init:7!: Backend init unsuccessful : [26]
2010-02-03 23:14:34.587: [ OCROSD][2346668976]utopen:6m':failed in stat OCR file/disk /share/storage/ocr, errno=2, os err string=No such file or directory
2010-02-03 23:14:34.587: [ OCROSD][2346668976]utopen:7:failed to open any OCR file/disk, errno=2, os err string=No such file or directory
2010-02-03 23:14:34.587: [ OCRRAW][2346668976]proprinit: Could not open raw device
2010-02-03 23:14:34.587: [ default][2346668976]a_init:7!: Backend init unsuccessful : [26]
2010-02-03 23:14:35.589: [ CRSD][2346668976][PANIC] CRSD exiting: OCR device cannot be initialized, error: 1:26
如果 OCR 是坏掉了,在 crsd.log 会看到以下的类似信息:
2010-02-03 23:19:38.417: [ default][3360863152]a_init:7!: Backend init unsuccessful : [26]
2010-02-03 23:19:39.429: [ OCRRAW][3360863152]propriogid:1_2: INVALID FORMAT
2010-02-03 23:19:39.429: [ OCRRAW][3360863152]proprioini: all disks are not OCR/OLR formatted
2010-02-03 23:19:39.429: [ OCRRAW][3360863152]proprinit: Could not open raw device
2010-02-03 23:19:39.429: [ default][3360863152]a_init:7!: Backend init unsuccessful : [26]
2010-02-03 23:19:40.432: [ CRSD][3360863152][PANIC] CRSD exiting: OCR device cannot be initialized, error: 1:26
如果您的 grid 用户的权限或者所在组发生了变化,尽管 ASM 还是可以访问的,在 crsd.log 会看到以下的类似信息:
2010-03-10 11:45:12.510: [ OCRASM][611467760]proprasmo: Error in open/create file in dg [SYSTEMDG]
[ OCRASM][611467760]SLOS : SLOS: cat=7, opn=kgfoAl06, dep=1031, loc=kgfokge
ORA-01031: insufficient privileges
2010-03-10 11:45:12.528: [ OCRASM][611467760]proprasmo: kgfoCheckMount returned [7]
2010-03-10 11:45:12.529: [ OCRASM][611467760]proprasmo: The ASM instance is down
2010-03-10 11:45:12.529: [ OCRRAW][611467760]proprioo: Failed to open [+SYSTEMDG]. Returned proprasmo() with [26]. Marking location as UNAVAILABLE.
2010-03-10 11:45:12.529: [ OCRRAW][611467760]proprioo: No OCR/OLR devices are usable
2010-03-10 11:45:12.529: [ OCRASM][611467760]proprasmcl: asmhandle is NULL
2010-03-10 11:45:12.529: [ OCRRAW][611467760]proprinit: Could not open raw device
2010-03-10 11:45:12.529: [ OCRASM][611467760]proprasmcl: asmhandle is NULL
2010-03-10 11:45:12.529: [ OCRAPI][611467760]a_init:16!: Backend init unsuccessful : [26]
2010-03-10 11:45:12.530: [ CRSOCR][611467760] OCR context init failure. Error: PROC-26: Error while accessing the physical storage ASM error [SLOS: cat=7, opn=kgfoAl06, dep=1031, loc=kgfokge
ORA-01031: insufficient privileges
] [7]
如果 GRID_HOME 下的 oracle 二进制文件的属主或者权限错误,尽管 ASM 正常启动并运行,在 crsd.log 会看到以下的类似信息:
2012-03-04 21:34:23.139: [ OCRASM][3301265904]proprasmo: Error in open/create file in dg [OCR]
[ OCRASM][3301265904]SLOS : SLOS: cat=7, opn=kgfoAl06, dep=12547, loc=kgfokge
2012-03-04 21:34:23.139: [ OCRASM][3301265904]ASM Error Stack : ORA-12547: TNS:lost contact
2012-03-04 21:34:23.633: [ OCRASM][3301265904]proprasmo: kgfoCheckMount returned [7]
2012-03-04 21:34:23.633: [ OCRASM][3301265904]proprasmo: The ASM instance is down
2012-03-04 21:34:23.634: [ OCRRAW][3301265904]proprioo: Failed to open [+OCR]. Returned proprasmo() with [26]. Marking location as UNAVAILABLE.
2012-03-04 21:34:23.634: [ OCRRAW][3301265904]proprioo: No OCR/OLR devices are usable
2012-03-04 21:34:23.635: [ OCRASM][3301265904]proprasmcl: asmhandle is NULL
2012-03-04 21:34:23.636: [ GIPC][3301265904] gipcCheckInitialization: possible incompatible non-threaded init from [prom.c : 690], original from [clsss.c : 5326]
2012-03-04 21:34:23.639: [ default][3301265904]clsvactversion:4: Retrieving Active Version from local storage.
2012-03-04 21:34:23.643: [ OCRRAW][3301265904]proprrepauto: The local OCR configuration matches with the configuration published by OCR Cache Writer. No repair required.
2012-03-04 21:34:23.645: [ OCRRAW][3301265904]proprinit: Could not open raw device
2012-03-04 21:34:23.646: [ OCRASM][3301265904]proprasmcl: asmhandle is NULL
2012-03-04 21:34:23.650: [ OCRAPI][3301265904]a_init:16!: Backend init unsuccessful : [26]
2012-03-04 21:34:23.651: [ CRSOCR][3301265904] OCR context init failure. Error: PROC-26: Error while accessing the physical storage
ORA-12547: TNS:lost contact
2012-03-04 21:34:23.652: [ CRSMAIN][3301265904] Created alert : (:CRSD00111:) : Could not init OCR, error: PROC-26: Error while accessing the physical storage
ORA-12547: TNS:lost contact
2012-03-04 21:34:23.652: [ CRSD][3301265904][PANIC] CRSD exiting: Could not init OCR, code: 26
正常的 GRID_HOME 下该文件的属主和权限应该是如下显示:
-rwsr-s--x 1 grid oinstall 184431149 Feb 2 20:37 /ocw/grid/bin/oracle
如果 OCR 文件或者它的镜像文件无法正常访问 (可能是 ASM 已经启动, 但是 OCR/mirror 所在的磁盘组没有挂载),在 crsd.log 会看到以下的类似信息:
2010-05-11 11:16:38.578: [ OCRASM][18]proprasmo: Error in open/create file in dg [OCRMIR]
[ OCRASM][18]SLOS : SLOS: cat=8, opn=kgfoOpenFile01, dep=15056, loc=kgfokge
ORA-17503: ksfdopn:DGOpenFile05 Failed to open file +OCRMIR.255.4294967295
ORA-17503: ksfdopn:2 Failed to open file +OCRMIR.255.4294967295
ORA-15001: diskgroup "OCRMIR
..
2010-05-11 11:16:38.647: [ OCRASM][18]proprasmo: kgfoCheckMount returned [6]
2010-05-11 11:16:38.648: [ OCRASM][18]proprasmo: The ASM disk group OCRMIR is not found or not mounted
2010-05-11 11:16:38.648: [ OCRASM][18]proprasmdvch: Failed to open OCR location [+OCRMIR] error [26]
2010-05-11 11:16:38.648: [ OCRRAW][18]propriodvch: Error [8] returned device check for [+OCRMIR]
2010-05-11 11:16:38.648: [ OCRRAW][18]dev_replace: non-master could not verify the new disk (8)
[ OCRSRV][18]proath_invalidate_action: Failed to replace [+OCRMIR] [8]
[ OCRAPI][18]procr_ctx_set_invalid_no_abort: ctx set to invalid
..
2010-05-11 11:16:46.587: [ OCRMAS][19]th_master:91: Comparing device hash ids between local and master failed
2010-05-11 11:16:46.587: [ OCRMAS][19]th_master:91 Local dev (1862408427, 1028247821, 0, 0, 0)
2010-05-11 11:16:46.587: [ OCRMAS][19]th_master:91 Master dev (1862408427, 1859478705, 0, 0, 0)
2010-05-11 11:16:46.587: [ OCRMAS][19]th_master:9: Shutdown CacheLocal. my hash ids don't match
[ OCRAPI][19]procr_ctx_set_invalid_no_abort: ctx set to invalid
[ OCRAPI][19]procr_ctx_set_invalid: aborting...
2010-05-11 11:16:46.587: [ CRSD][19] Dump State Starting ...
3. crsd.bin 的进程号文件(<GRID_HOME>/crs/init/<节点名>.pid)存在,但是却指向其它的进程
如果进程号文件不存在,在日志 $GRID_HOME/log/$HOST/agent/ohasd/orarootagent_root/orarootagent_root.log 我们会看到以下的提示信息:
2010-02-14 17:40:57.927: [ora.crsd][1243486528] [check] PID FILE doesn't exist.
..
2010-02-14 17:41:57.927: [ clsdmt][1092499776]Creating PID [30269] file for home /ocw/grid host racnode1 bin crs to /ocw/grid/crs/init/
2010-02-14 17:41:57.927: [ clsdmt][1092499776]Error3 -2 writing PID [30269] to the file []
2010-02-14 17:41:57.927: [ clsdmt][1092499776]Failed to record pid for CRSD
2010-02-14 17:41:57.927: [ clsdmt][1092499776]Terminating process
2010-02-14 17:41:57.927: [ default][1092499776] CRSD exiting on stop request from clsdms_thdmai
解决办法,我们可以手工创建一个进程号文件:使用 grid 用户执行 "touch" 命令,然后重新启动 ora.crsd 资源。
如果进程号文件存在,但是记录的 PID 是指向了其它的进程,而不是 crsd.bin 的进程,在日志 $GRID_HOME/log/$HOST/agent/ohasd/orarootagent_root/orarootagent_root.log 我们会看到以下的提示信息:
2011-04-06 15:53:38.777: [ora.crsd][1160390976] [check] PID will be looked for in /ocw/grid/crs/init/racnode1.pid
2011-04-06 15:53:38.778: [ora.crsd][1160390976] [check] PID which will be monitored will be 1535 >> 1535 is output of "cat /ocw/grid/crs/init/racnode1.pid"
2011-04-06 15:53:38.965: [ COMMCRS][1191860544]clsc_connect: (0x2aaab400b0b0) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=racnode1DBG_CRSD))
[ clsdmc][1160390976]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=racnode1DBG_CRSD)) with status 9
2011-04-06 15:53:38.966: [ora.crsd][1160390976] [check] Error = error 9 encountered when connecting to CRSD
2011-04-06 15:53:39.023: [ora.crsd][1160390976] [check] Calling PID check for daemon
2011-04-06 15:53:39.023: [ora.crsd][1160390976] [check] Trying to check PID = 1535
2011-04-06 15:53:39.203: [ora.crsd][1160390976] [check] PID check returned ONLINE CLSDM returned OFFLINE
2011-04-06 15:53:39.203: [ora.crsd][1160390976] [check] DaemonAgent::check returned 5
2011-04-06 15:53:39.203: [ AGFW][1160390976] check for resource: ora.crsd 1 1 completed with status: FAILED
2011-04-06 15:53:39.203: [ AGFW][1170880832] ora.crsd 1 1 state changed from: UNKNOWN to: FAILED
..
2011-04-06 15:54:10.511: [ AGFW][1167522112] ora.crsd 1 1 state changed from: UNKNOWN to: CLEANING
..
2011-04-06 15:54:10.513: [ora.crsd][1146542400] [clean] Trying to stop PID = 1535
..
2011-04-06 15:54:11.514: [ora.crsd][1146542400] [clean] Trying to check PID = 1535
在 OS 层面检查该问题:
ls -l /ocw/grid/crs/init/*pid
-rwxr-xr-x 1 ogrid oinstall 5 Feb 17 11:00 /ocw/grid/crs/init/racnode1.pid
cat /ocw/grid/crs/init/*pid
1535
ps -ef| grep 1535
root 1535 1 0 Mar30 ? 00:00:00 iscsid >> 注意:进程 1535 不是 crsd.bin
解决办法是,使用 root 用户,创建一个空的进程号文件,然后重启资源 ora.crsd:
# > $GRID_HOME/crs/init/<racnode1>.pid
# $GRID_HOME/bin/crsctl stop res ora.crsd -init
# $GRID_HOME/bin/crsctl start res ora.crsd -init
4. 网络功能是正常的,并且域名解析能够正常工作:
如果网络功能不正常,ocssd.bin 进程仍然可能被启动, 但是 crsd.bin 可能会失败,同时在 crsd.log 中会提示以下信息:
2010-02-03 23:34:28.412: [ GPnP][2235814832]clsgpnp_Init: [at clsgpnp0.c:837] GPnP client pid=867, tl=3, f=0
2010-02-03 23:34:28.428: [ OCRAPI][2235814832]clsu_get_private_ip_addresses: no ip addresses found.
..
2010-02-03 23:34:28.434: [ OCRAPI][2235814832]a_init:13!: Clusterware init unsuccessful : [44]
2010-02-03 23:34:28.434: [ CRSOCR][2235814832] OCR context init failure. Error: PROC-44: Error in network address and interface operations Network address and interface operations error [7]
2010-02-03 23:34:28.434: [ CRSD][2235814832][PANIC] CRSD exiting: Could not init OCR, code: 44
或者:
2009-12-10 06:28:31.974: [ OCRMAS][20]proath_connect_master:1: could not connect to master clsc_ret1 = 9, clsc_ret2 = 9
2009-12-10 06:28:31.974: [ OCRMAS][20]th_master:11: Could not connect to the new master
2009-12-10 06:29:01.450: [ CRSMAIN][2] Policy Engine is not initialized yet!
2009-12-10 06:29:31.489: [ CRSMAIN][2] Policy Engine is not initialized yet!
或者:
2009-12-31 00:42:08.110: [ COMMCRS][10]clsc_receive: (102b03250) Error receiving, ns (12535, 12560), transport (505, 145, 0)
关于网络和域名解析的验证,请参考:note 1054902.1
5. crsd 可执行文件(crsd.bin 和 crsd in GRID_HOME/bin) 的权限或者属主正确并且没有进行过手工的修改, 一个简单可行的检查办法是对比好的节点和坏节点的以下命令输出 "ls -l <grid-home>/bin/crsd <grid-home>/bin/crsd.bin".
6. 关于CRSD进程启动问题的进一步深入诊断,请参考 note 1323698.1 - Troubleshooting CRSD Start up Issue
1.1.6. 问题 5: GPNPD.BIN 无法启动
1. 网络的域名解析不正常
gpnpd.bin 进程启动失败,以下信息提示在 gpnpd.log 中:
2010-05-13 12:48:11.540: [ GPnP][1171126592]clsgpnpm_exchange: [at clsgpnpm.c:1175] Calling "tcp://node2:9393", try 1 of 3...
2010-05-13 12:48:11.540: [ GPnP][1171126592]clsgpnpm_connect: [at clsgpnpm.c:1015] ENTRY
2010-05-13 12:48:11.541: [ GPnP][1171126592]clsgpnpm_connect: [at clsgpnpm.c:1066] GIPC gipcretFail (1) gipcConnect(tcp-tcp://node2:9393)
2010-05-13 12:48:11.541: [ GPnP][1171126592]clsgpnpm_connect: [at clsgpnpm.c:1067] Result: (48) CLSGPNP_COMM_ERR. Failed to connect to call url "tcp://node2:9393"
以上的例子,请确定当前节点能够正常的 ping 到“node2” ,并且确认两个节点之间没有任何防火墙。
2. bug 10105195
由于 bug 10105195, gpnp 的调度线程(dispatch thread)可能被阻断,例如:网络扫描。这个 bug 在 11.2.0.2 GI PSU2,11.2.0.3 及以上版本被修复,具体信息,请参见 note 10105195.8。
1.1.7. 问题 6: 其它的一些守护进程无法启动
常见原因:
1. 守护进程的日志文件或者日志所在的路径权限或者属主不正确。
如果日志文件或者日志文件所在的路径权限或者属主设置有问题,通常我们会看到进程尝试启动,但是日志里的信息却始终没有更新.
关于日志位置和权限属主的限制,请参见 "日志文件位置, 属主和权限" 获取更多的信息。
2. 网络的 socket 文件权限或者属主错误
这种情况下,守护进程的日志会显示以下信息:
2010-02-02 12:55:20.485: [ COMMCRS][1121433920]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=rac1DBG_GIPCD))
2010-02-02 12:55:20.485: [ clsdmt][1110944064]Fail to listen to (ADDRESS=(PROTOCOL=ipc)(KEY=rac1DBG_GIPCD))
3. OLR 文件损坏
这种情况下,守护进程的日志会显示以下信息(以下是个 ora.ctssd 无法启动的例子):
2012-07-22 00:15:16.565: [ default][1]clsvactversion:4: Retrieving Active Version from local storage.
2012-07-22 00:15:16.575: [ CTSS][1]clsctss_r_av3: Invalid active version [] retrieved from OLR. Returns [19].
2012-07-22 00:15:16.585: [ CTSS][1](:ctss_init16:): Error [19] retrieving active version. Returns [19].
2012-07-22 00:15:16.585: [ CTSS][1]ctss_main: CTSS init failed [19]
2012-07-22 00:15:16.585: [ CTSS][1]ctss_main: CTSS daemon aborting [19].
2012-07-22 00:15:16.585: [ CTSS][1]CTSS daemon aborting
解决办法,请恢复一个好的OLR的副本,具体办法请参见 note 1193643.1
1.1.8. 问题 7: CRSD Agents 无法启动
CRSD.BIN 会负责衍生出两个 agents 进程来启动用户的资源,这两个 agents 的名字和 ohasd.bin 的 agents 的名字相同:
orarootagent: 负责启动 ora.netn.network, ora.nodename.vip, ora.scann.vip 和 ora.gns
oraagent: 负责启动 ora.asm, ora.eons, ora.ons, listener, SCAN listener, diskgroup, database, service 等资源
我们可以通过以下命令查看用户的资源状态:
$GRID_HOME/crsctl stat res -t
如果 crsd.bin 无法正常启动以上任何一个 agent,用户的资源都将无法正常启动.
1. 通常这些 agent 无法启动的常见原因是 agent 的日志或者日志所在的路径没有设置合适的权限或者属主。
请参见以下 "日志文件位置, 属主和权限" 部分关于日志权限的设置。
2. agent 可能因为 bug 11834289 无法启动,此时我们会看到 "CRS-5802: Unable to start the agent process"错误信息,请参见 "OHASD 无法启动" #10 获取更多信息。
1.1.9. 问题 8: HAIP 无法启动
HAIP 无法启动的原因有很多,例如:
[ohasd(891)]CRS-2807:Resource 'ora.cluster_interconnect.haip' failed to start automatically.
请参见 note 1210883.1 获取更多关于 HAIP 的信息。
1.1.10. 网络和域名解析的验证
CRS 的启动,依赖于网络功能和域名解析的正常工作,如果网络功能或者域名解析不能正常工作,CRS 将无法正常启动。
关于网络和域名解析的验证,请参考: note 1054902.1
1.1.11. 日志文件位置, 属主和权限
正确的设置 $GRID_HOME/log 和这里的子目录以及文件对 CRS 组件的正常启动是至关重要的。
1.1.11.1. 在 Grid Infrastructure 的环境中:
我们假设一个 Grid Infrastructure 环境,节点名字为 rac1, CRS 的属主是 grid, 并且有两个单独的 RDBMS 属主分别为: rdbmsap 和 rdbmsar,以下是 $GRID_HOME/log 中正常的设置情况:
drwxrwxr-x 5 grid oinstall 4096 Dec 6 09:20 log
drwxr-xr-x 2 grid oinstall 4096 Dec 6 08:36 crs
drwxr-xr-t 17 root oinstall 4096 Dec 6 09:22 rac1
drwxr-x--- 2 grid oinstall 4096 Dec 6 09:20 admin
drwxrwxr-t 4 root oinstall 4096 Dec 6 09:20 agent
drwxrwxrwt 7 root oinstall 4096 Jan 26 18:15 crsd
drwxr-xr-t 2 grid oinstall 4096 Dec 6 09:40 application_grid
drwxr-xr-t 2 grid oinstall 4096 Jan 26 18:15 oraagent_grid
drwxr-xr-t 2 rdbmsap oinstall 4096 Jan 26 18:15 oraagent_rdbmsap
drwxr-xr-t 2 rdbmsar oinstall 4096 Jan 26 18:15 oraagent_rdbmsar
drwxr-xr-t 2 grid oinstall 4096 Jan 26 18:15 ora_oc4j_type_grid
drwxr-xr-t 2 root root 4096 Jan 26 20:09 orarootagent_root
drwxrwxr-t 6 root oinstall 4096 Dec 6 09:24 ohasd
drwxr-xr-t 2 grid oinstall 4096 Jan 26 18:14 oraagent_grid
drwxr-xr-t 2 root root 4096 Dec 6 09:24 oracssdagent_root
drwxr-xr-t 2 root root 4096 Dec 6 09:24 oracssdmonitor_root
drwxr-xr-t 2 root root 4096 Jan 26 18:14 orarootagent_root
-rw-rw-r-- 1 root root 12931 Jan 26 21:30 alertrac1.log
drwxr-x--- 2 grid oinstall 4096 Jan 26 20:44 client
drwxr-x--- 2 root oinstall 4096 Dec 6 09:24 crsd
drwxr-x--- 2 grid oinstall 4096 Dec 6 09:24 cssd
drwxr-x--- 2 root oinstall 4096 Dec 6 09:24 ctssd
drwxr-x--- 2 grid oinstall 4096 Jan 26 18:14 diskmon
drwxr-x--- 2 grid oinstall 4096 Dec 6 09:25 evmd
drwxr-x--- 2 grid oinstall 4096 Jan 26 21:20 gipcd
drwxr-x--- 2 root oinstall 4096 Dec 6 09:20 gnsd
drwxr-x--- 2 grid oinstall 4096 Jan 26 20:58 gpnpd
drwxr-x--- 2 grid oinstall 4096 Jan 26 21:19 mdnsd
drwxr-x--- 2 root oinstall 4096 Jan 26 21:20 ohasd
drwxrwxr-t 5 grid oinstall 4096 Dec 6 09:34 racg
drwxrwxrwt 2 grid oinstall 4096 Dec 6 09:20 racgeut
drwxrwxrwt 2 grid oinstall 4096 Dec 6 09:20 racgevtf
drwxrwxrwt 2 grid oinstall 4096 Dec 6 09:20 racgmain
drwxr-x--- 2 grid oinstall 4096 Jan 26 20:57 srvm
请注意,绝大部分的子目录都继承了父目录的属主和权限,以上仅作为一个参考,来判断 CRS HOME 中是否有一些递归的权限和属主改变,如果您已经有一个相同版本的正在运行的工作节点,您可以把该运行的节点作为参考。
1.1.11.2. 在 Oracle Restart 的环境中:
这里显示了在 Oracle Restart 环境中 $GRID_HOME/log 目录下的权限和属主设置:
drwxrwxr-x 5 grid oinstall 4096 Oct 31 2009 log
drwxr-xr-x 2 grid oinstall 4096 Oct 31 2009 crs
drwxr-xr-x 3 grid oinstall 4096 Oct 31 2009 diag
drwxr-xr-t 17 root oinstall 4096 Oct 31 2009 rac1
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 admin
drwxrwxr-t 4 root oinstall 4096 Oct 31 2009 agent
drwxrwxrwt 2 root oinstall 4096 Oct 31 2009 crsd
drwxrwxr-t 8 root oinstall 4096 Jul 14 08:15 ohasd
drwxr-xr-x 2 grid oinstall 4096 Aug 5 13:40 oraagent_grid
drwxr-xr-x 2 grid oinstall 4096 Aug 2 07:11 oracssdagent_grid
drwxr-xr-x 2 grid oinstall 4096 Aug 3 21:13 orarootagent_grid
-rwxr-xr-x 1 grid oinstall 13782 Aug 1 17:23 alertrac1.log
drwxr-x--- 2 grid oinstall 4096 Nov 2 2009 client
drwxr-x--- 2 root oinstall 4096 Oct 31 2009 crsd
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 cssd
drwxr-x--- 2 root oinstall 4096 Oct 31 2009 ctssd
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 diskmon
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 evmd
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 gipcd
drwxr-x--- 2 root oinstall 4096 Oct 31 2009 gnsd
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 gpnpd
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 mdnsd
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 ohasd
drwxrwxr-t 5 grid oinstall 4096 Oct 31 2009 racg
drwxrwxrwt 2 grid oinstall 4096 Oct 31 2009 racgeut
drwxrwxrwt 2 grid oinstall 4096 Oct 31 2009 racgevtf
drwxrwxrwt 2 grid oinstall 4096 Oct 31 2009 racgmain
drwxr-x--- 2 grid oinstall 4096 Oct 31 2009 srvm
1.1.12. 网络socket文件的位置,属主和权限
网络的 socket 文件可能位于目录: /tmp/.oracle, /var/tmp/.oracle or /usr/tmp/.oracle 中。
当网络的 socket 文件权限或者属主设置不正确的时候,我们通常会在守护进程的日志中看到以下类似的信息:
2011-06-18 14:07:28.545: [ COMMCRS][772]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=racnode1DBG_EVMD))
2011-06-18 14:07:28.545: [ clsdmt][515]Fail to listen to (ADDRESS=(PROTOCOL=ipc)(KEY=lena042DBG_EVMD))
2011-06-18 14:07:28.545: [ clsdmt][515]Terminating process
2011-06-18 14:07:28.559: [ default][515] EVMD exiting on stop request from clsdms_thdmai
以下错误也有可能提示:
CRS-5017: The resource action "ora.evmd start" encountered the following error:
CRS-2674: Start of 'ora.evmd' on 'racnode1' failed
..
解决的办法:请使用 root 用户停掉 GI,删除这些 socket 文件,并重新启动 GI。
我们假设一个 Grid Infrastructure 环境,节点名为 rac1, CRS 的属主是 grid,以下是 socket 文件夹(../.oracle)正常的设置情况:
1.1.12.1. 在 Grid Infrastructure cluster 环境中:
以下例子是集群环境中的例子:
drwxrwxrwt 2 root oinstall 4096 Feb 2 21:25 .oracle
./.oracle:
drwxrwxrwt 2 root oinstall 4096 Feb 2 21:25 .
srwxrwx--- 1 grid oinstall 0 Feb 2 18:00 master_diskmon
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 mdnsd
-rw-r--r-- 1 grid oinstall 5 Feb 2 18:00 mdnsd.pid
prw-r--r-- 1 root root 0 Feb 2 13:33 npohasd
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 ora_gipc_GPNPD_rac1
-rw-r--r-- 1 grid oinstall 0 Feb 2 13:34 ora_gipc_GPNPD_rac1_lock
srwxrwxrwx 1 grid oinstall 0 Feb 2 13:39 s#11724.1
srwxrwxrwx 1 grid oinstall 0 Feb 2 13:39 s#11724.2
srwxrwxrwx 1 grid oinstall 0 Feb 2 13:39 s#11735.1
srwxrwxrwx 1 grid oinstall 0 Feb 2 13:39 s#11735.2
srwxrwxrwx 1 grid oinstall 0 Feb 2 13:45 s#12339.1
srwxrwxrwx 1 grid oinstall 0 Feb 2 13:45 s#12339.2
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 s#6275.1
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 s#6275.2
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 s#6276.1
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 s#6276.2
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 s#6278.1
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 s#6278.2
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 sAevm
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 sCevm
srwxrwxrwx 1 root root 0 Feb 2 18:01 sCRSD_IPC_SOCKET_11
srwxrwxrwx 1 root root 0 Feb 2 18:01 sCRSD_UI_SOCKET
srwxrwxrwx 1 root root 0 Feb 2 21:25 srac1DBG_CRSD
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 srac1DBG_CSSD
srwxrwxrwx 1 root root 0 Feb 2 18:00 srac1DBG_CTSSD
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 srac1DBG_EVMD
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 srac1DBG_GIPCD
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 srac1DBG_GPNPD
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 srac1DBG_MDNSD
srwxrwxrwx 1 root root 0 Feb 2 18:00 srac1DBG_OHASD
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 sLISTENER
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 sLISTENER_SCAN2
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:01 sLISTENER_SCAN3
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 sOCSSD_LL_rac1_
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 sOCSSD_LL_rac1_eotcs
-rw-r--r-- 1 grid oinstall 0 Feb 2 18:00 sOCSSD_LL_rac1_eotcs_lock
-rw-r--r-- 1 grid oinstall 0 Feb 2 18:00 sOCSSD_LL_rac1__lock
srwxrwxrwx 1 root root 0 Feb 2 18:00 sOHASD_IPC_SOCKET_11
srwxrwxrwx 1 root root 0 Feb 2 18:00 sOHASD_UI_SOCKET
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 sOracle_CSS_LclLstnr_eotcs_1
-rw-r--r-- 1 grid oinstall 0 Feb 2 18:00 sOracle_CSS_LclLstnr_eotcs_1_lock
srwxrwxrwx 1 root root 0 Feb 2 18:01 sora_crsqs
srwxrwxrwx 1 root root 0 Feb 2 18:00 sprocr_local_conn_0_PROC
srwxrwxrwx 1 root root 0 Feb 2 18:00 sprocr_local_conn_0_PROL
srwxrwxrwx 1 grid oinstall 0 Feb 2 18:00 sSYSTEM.evm.acceptor.auth
1.1.12.2. 在 Oracle Restart 环境中:
以下是 Oracle Restart 环境中的输出例子:
drwxrwxrwt 2 root oinstall 4096 Feb 2 21:25 .oracle
./.oracle:
srwxrwx--- 1 grid oinstall 0 Aug 1 17:23 master_diskmon
prw-r--r-- 1 grid oinstall 0 Oct 31 2009 npohasd
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 s#14478.1
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 s#14478.2
srwxrwxrwx 1 grid oinstall 0 Jul 14 08:02 s#2266.1
srwxrwxrwx 1 grid oinstall 0 Jul 14 08:02 s#2266.2
srwxrwxrwx 1 grid oinstall 0 Jul 7 10:59 s#2269.1
srwxrwxrwx 1 grid oinstall 0 Jul 7 10:59 s#2269.2
srwxrwxrwx 1 grid oinstall 0 Jul 31 22:10 s#2313.1
srwxrwxrwx 1 grid oinstall 0 Jul 31 22:10 s#2313.2
srwxrwxrwx 1 grid oinstall 0 Jun 29 21:58 s#2851.1
srwxrwxrwx 1 grid oinstall 0 Jun 29 21:58 s#2851.2
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sCRSD_UI_SOCKET
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 srac1DBG_CSSD
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 srac1DBG_OHASD
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sEXTPROC1521
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sOCSSD_LL_rac1_
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sOCSSD_LL_rac1_localhost
-rw-r--r-- 1 grid oinstall 0 Aug 1 17:23 sOCSSD_LL_rac1_localhost_lock
-rw-r--r-- 1 grid oinstall 0 Aug 1 17:23 sOCSSD_LL_rac1__lock
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sOHASD_IPC_SOCKET_11
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sOHASD_UI_SOCKET
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sgrid_CSS_LclLstnr_localhost_1
-rw-r--r-- 1 grid oinstall 0 Aug 1 17:23 sgrid_CSS_LclLstnr_localhost_1_lock
srwxrwxrwx 1 grid oinstall 0 Aug 1 17:23 sprocr_local_conn_0_PROL
1.1.13. 诊断文件收集
如果通过本文没有找到问题原因,请使用 root 用户,在所有的节点上执行 $GRID_HOME/bin/diagcollection.sh ,并上传在当前目录下生成所有的 .gz 压缩文件来做进一步诊断。
1.1. 参考
BUG:10105195 - PROC-32 ACCESSING OCR; CRS DOES NOT COME UP ON NODE
NOTE:1323698.1 - Troubleshooting CRSD Start up Issue
NOTE:1325718.1 - OHASD not Starting After Reboot on SLES
NOTE:1077094.1 - How to fix the "DiscoveryString in profile.xml" or "asm_diskstring in ASM" if set wrongly
NOTE:1068835.1 - What to Do if 11gR2 Grid Infrastructure is Unhealthy
NOTE:942166.1 - How to Proceed from Failed 11gR2 Grid Infrastructure (CRS) Installation
NOTE:969254.1 - How to Proceed from Failed Upgrade to 11gR2 Grid Infrastructure on Linux/Unix
NOTE:10105195.8 - Bug 10105195 - Clusterware fails to start after reboot due to gpnpd fails to start
NOTE:1053147.1 - 11gR2 Clusterware and Grid Home - What You Need to Know
NOTE:1053970.1 - Troubleshooting 11.2 Grid Infrastructure root.sh Issues
NOTE:1069182.1 - OHASD Failed to Start: Inappropriate ioctl for device
NOTE:1054902.1 - How to Validate Network and Name Resolution Setup for the Clusterware and RAC
BUG:11834289 - OHASD FAILED TO START TIMELY
NOTE:1564555.1 - 11.2.0.3 PSU5/PSU6/PSU7 or 12.1.0.1 CSSD Fails to Start if Multicast Fails on Private Network
NOTE:1427234.1 - autorun file for ohasd is missing