NGINX应用性能优化指南(第五部分):吞吐量
【编者的话】本文是“NGINX应用性能优化指南”系列文章的第五篇,主要介绍了如何从吞吐量方面实现NGINX应用性能优化。
注:本文最初发布于MaxCDN博客,InfoQ中文站在获得作者授权的基础上对文章进行了翻译。
正文
NGINX反向代理配置设置了两个网络路径:客户端到代理和代理到服务器。这两个路径不仅“HTTP跨度(HTTP spans)”不同,TCP网络传输域也不同。

尤其是提供大资源时,我们的目标是确保TCP充分利用了端到端连接。理论上讲,如果TCP流同HTTP数据紧密打包在一起,而且数据尽可能快地发送出去,那么我们就会获得最大的吞吐量。
但是,我时常在想,为什么我没有看到更快的下载速度。知道这种感觉吗?所以让我们深入底层,了解下基本原理。
网络传输入门
TCP采用两个基本原则决定何时发送以及发送多少数据:
- 流量控制是为了确保接收者可以接收数据;
- 拥塞控制是为了管理网络带宽。
流量控制是通过接收者指定的接收窗口实现的,后者会规定接收者一次希望接收和存储的最大数据量。这个窗口可能会变大——从几个KB到若干MB——这取决于测得的连接带宽延迟乘积(BDP,对此下文会有更多介绍)。
拥塞控制是由发送者实现为RWND大小的一个约束函数。发送者会将它传输的数据量限制为CWND和RWND的最小值。可以将此看作是遵从“网络公平性”的一种自我约束。窗口大小(CWND)会随着时间增长,或者随着发送者接收到先前传输的数据的确认而增长。如果检测到网络拥塞,那么它也会缩小窗口。

同时,发送者和接收者在决定最大可用TCP吞吐量时各自扮演一个重要的角色。如果接收者的RWND太小,或者发送者对网络拥塞过于敏感或者对网络拥塞减退反应太慢,那么TCP吞吐量都不会是最理想的。
管道填充
网络连接通常以管道为模型。发送者在一端泵入数据,接收者在另一端抽取数据。
BDP(以KB或MB为单位)是比特率同RTT的乘积,是一个表示需要多少数据填充管道的指标。例如,如果你在使用一个100Mbps的端到端连接,而RTT为80毫秒,那么BDP就为1MB(100 Mbps * 0.080 sec = 1 MB)。
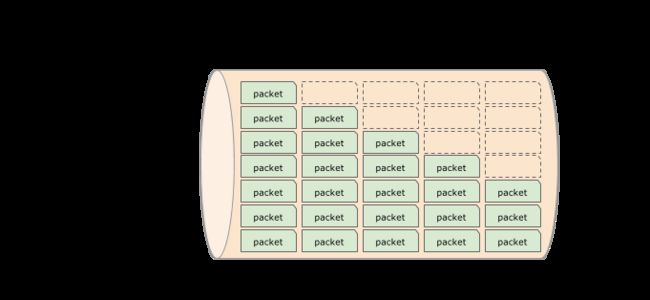
TCP会设法填充管道,并保证没有管道泄露或破裂,因此,BDP是RWND的理想值:TCP可以发出的最大动态(还没有收到接收者的确认)数据量。
假设有足够的数据待发送(大文件),而且没有什么阻止发送应用程序(NGINX)以管道能够接受的速度向管道泵入数据,RWND和CWND可能会成为实现最大吞吐量的限制因素。
大多数现代TCP栈会使用TCP时间戳以及窗口缩放选项自动优化这些参数。但是旧系统不会,有些应用程序会出现异常行为。因此,有两个明显的问题:
- 我如何检查?
- 我如何修复?
我们下面会处理第一个问题,但是修复TCP涉及学习如何优化TCP栈——这本身就是一项全职工作。更可行的方案是TCP加速软件或硬件。而且,这类供应商非常多,包括我每天都在研究的产品SuperTCP。
检查RWND和CWND
设法确认RWND或CWND是否是限制因素,包括将它们同BDP进行比较。
为此,我们会嗅探在(无头)NGINX代理上使用tcpdump工具进行大资源HTTP(S)传输的数据包,并将捕获的文件加载到带有图形界面的机器上的Wireshark中。然后,我们可以绘制一个有意义的图形,从而对这些基本变量是否得到了正确设置有一些了解。
# tcpdump -w http_get.pcap -n -s 100 -i eth0 port <80|443>
如果你使用了一个不同的捕获过滤器,那么只要确保它捕获了TCP HTTP对话的双向数据。另外,还要确保是在发送设备上进行捕获,因为我们需要使用Wireshark正确地计算动态数据量。(在接收者一端进行捕获会使Wireshark相信RTT接近为0,因为接收者ACK可能会在数据进来后立即发送出去)。
将http_get.pcap文件加载到Wireshark中,找到感兴趣的HTTP流,然后仔细看下它的tcp.stream索引:
打开Statistics->IO Graph,并进行如下配置:
- Y-axis -> Unit:
Advanced - Scale:
Auto - Graph 5 (pink)
- Filter:
tcp.dstport==<80|443> &&tcp.stream==< index> - Calc:
MAXandtcp.window_size - Style:
Impulse
- Filter:
- Graph 4 (blue)
- Filter:
tcp.srcport==<80|443> &&tcp.stream==< index> - Calc:
MAXandtcp.analysis.bytes_in_flight - Style:
FBar
- Filter:
接下来,务必按下(启用)Graph 4和Graph 5按钮,根据那些结果进行绘图。下面的例子可能是你期望看到的:
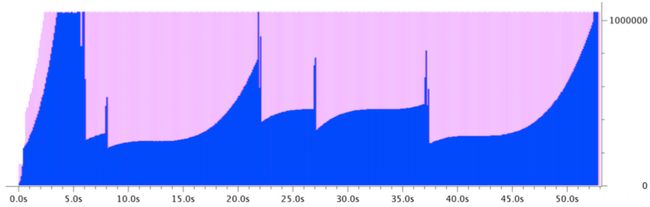
我使用一个100Mbps的连接从一个80毫秒远的NGINX代理上GET一个128MB的文件(从AWS俄勒冈州到我们在加拿大渥太华的办公室)。相应的BDP为1MB。
注意看下RWND(粉色)的变化,开始时很小,数个往返后增长到稍稍超过1MB。这证明接收者能够调整RWND,并且可以察觉BDP(好极了)。或者,如果我们看到RWND变小了(又称为关闭中),那表明接收应用程序读取数据的速度不够快——也许没有获得足够的CPU时间。
对于发送者的性能——CWND(蓝色)——我们想要一个指征,就是动态数据量会受到RWND限制。我们看到,在3秒到6秒这个时间段里,NGINX代理能够发出的动态数据量是RWND允许的最大数据量。这证明发送者能够推送足够的数据以满足BDP。
不过,在快到6秒时,似乎有东西出现了大问题。发送者发出的动态数据量显著减少。自我约束行为通常是由发送者检测到拥塞引起的。回想一下,GET响应从西海岸传送到东海岸,遇到网络拥塞还是很可能的。
识别网络拥塞
当发送者检测到拥塞,它会缩小CWND,以便减少它对网络拥塞的贡献。但是,我们如何才能知道?
通常,TCP栈可以使用两类指示器检测或度量网络拥塞:数据包丢失和延迟变化(bufferbloat)。
- 数据包丢失:任何网络都会出现数据包丢失,Wi-Fi网络尤为突出,或者在网络元素积极管理它们的队列(比如随机早期丢弃)的时候,或者在它们根本没有管理它们的队列(尾部丢弃)的时候。TCP会将丢失ACK或者从接收者那里收到了非递增ACK(又称重复ACK)当作数据包丢失。
-
Bufferbloat是由数据包积压越来越多导致的端点间延迟(RTT)增加。
TIP:使用简单的工具
ping或者更加复杂的工具mtr,有时候可以检测到有意义的bufferbloat——尤其是当发送者推送数据速率较高的时候。那会给你深刻的印象,让你对更深层次的网络上可能正在发生什么有个真实的感受。
在同一个Wireshark IO Graph窗口中加入下列内容:
- Graph 2 (red)
- Filter:
tcp.dstport==<80|443> &&tcp.stream==< index> - Calc:
COUNT FIELDSandtcp.analysis.duplicate_ack - Style:
FBar
- Filter:
- 另外将Scale改为
Logarithmic
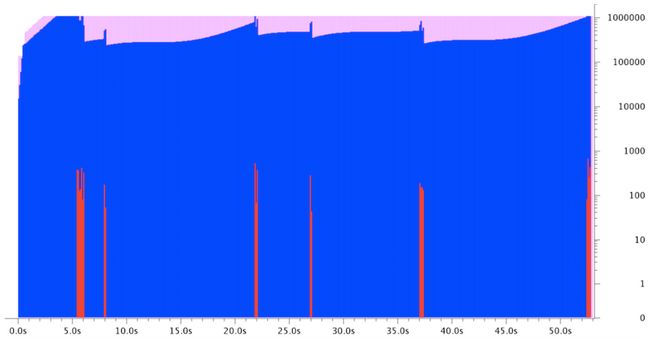
瞧!证据有了,接收者发送了重复ACK,表明实际上有数据包丢失。这解释了为什么发送者缩小了CWND,即动态数据量。
你可能还想寻找tcp.analysis.retransmission出现的证据,当出现数据包丢失报告,数据包必须重发时,或者当发送者等待来自接收者的ACK超时时(假设数据包丢失或者ACK丢失)。在后一种情况下,查下tcp.analysis.rto。
对于上述两种情况,务必将Filter设置为tcp.srcport=*<80|443>*,因为重传源于发送者。
查看英文原文:NGINX Application Performance Optimization:Throughput
感谢郭蕾对本文的策划和审校。