Spark 定制版:001~Spark Streaming(一)
本讲内容:
a. Spark Streaming在线另类实验
b. 瞬间理解Spark Streaming的本质
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
源码定制为什么从Spark Streaming切入?
a. Spark 最初只有Spark Core,通过逐步的发展,扩展出了Spark SQL、Spark Streaming、Spark MLlib(machine learning)、GraphX(graph)、Spark R等。 而Spark Streaming本是Spark Core上的一个子框架,如果我们试着去精通这个子框架,不仅仅能写出非常复杂的应用程序,还能够很好的驾驭Spark,进而研究并达到精通Spark的地步,及其寻找到Spark问题的解决之道。
b. 由于Spark SQL涉及到很多SQL语法解析和优化的细节,对于我们集中精力研究Spark有所干扰。Spark R还不是很成熟,支持功能有限。GraphX最近几个版本基本没有改进,里面有许多数学算法。MLlib也涉及到相当多的数学知识。
c. Spark Streaming的优势是在于可以结合SparkSQL、图计算、机器学习,使其功能更加强大。同时,在Spark中Spark Streaming也是最容易出现问题的,因为它是不断的运行,内部比较复杂。掌握好Spark Streaming,可以去窥视Spark的一切!
Spark Streaming的什么魅力在吸引你 ?
a、 Spark Streaming是流式计算
这是一个流处理的时代,一切数据如果不是以流式来处理或者跟流式的处理不相关的话,都将是次数据。我们必将处在一个流的数据处理时代。
b、Spark Streaming之最强“小宇宙”
首先,对源源不断流进来的数据,能够迅速响应并立即给出你所要是反馈信息,这不是批处理或者数据挖掘能做到的。
其次,Spark非常强大的地方在于它的流式处理可以在线的利用机器学习、图计算、Spark SQL或者Spark R的成果,这得益于Spark多元化、一体化的基础架构设计。也就是说,在Spark技术堆栈中,Spark Streaming可以调用任何的API接口,不需要做任何的设置。这是Spark无可匹敌之处,也是Spark Streaming必将一统天下的根源。
最后、我想说在这个时代,流处理单打独斗已经无法满足我们数据的深层次的应用,所以Spark Streaming必将回合多个Spark子框架,爆发最强的小宇宙,称霸大数据领域。
c、Spark Streaming是“魅力和复杂”的混合体
走进spark,了解了What is Spark ? 你会被它的能力折服,假如你能很好的驾驭Spark、精通 Spark Streaming以及Spark其他子框架,你必将领略Spark的无穷魅力。在Spark的所有程序中,Spark Streaming的应用是最具挑战性、复杂性的,这样的程序应用也是最容易出问题的。为什么这么说呢?因为要对数以万计的不断流进来的数据,做各种操作,包括:能动态控制数据的流入、作业的切分、数据的处理等,这些都会带来极大的复杂性。
d、Spark Streaming独特之处
其实,Spark Streaming很像是基于Spark Core之上的一个应用程序。不像其他子框架,比如机器学习是把数学算法直接应用在Spark的RDD之上,Spark Streaming更像一般的应用程序那样,感知流进来的数据并进行相应的处理。很像顺其自然的一种感知操作,利用自己独有的”神经元“来对数据进行各类操作。
至此,如果要做Spark 的定制开发,Spark Streaming则是最强有力的切入点,掌握了Spark Streaming也就开启了精通Spark的天堂之门。
当然想掌握SparkStreaming,但不去精通Spark Core的话,那是不可能的。Spark Core加Spark Streaming更是双剑合璧,威力无穷。我们选择SparkStreaming来入手,等于是找到了关键点。如果说,Spark算是当今DT龙脉。那么Spark Streaming就是龙穴之所在。解答龙穴之谜,进而能窥视Spark之根本。
如何清晰的看到数据的流入、被处理的过程?
使用一个小技巧,通过调节放大Batch Interval的方式,来降低批处理次数,以方便看清楚各个环节。
我们从已写过的广告点击的在线黑名单过滤的Spark Streaming应用程序入手。一下是具体的实验源码:
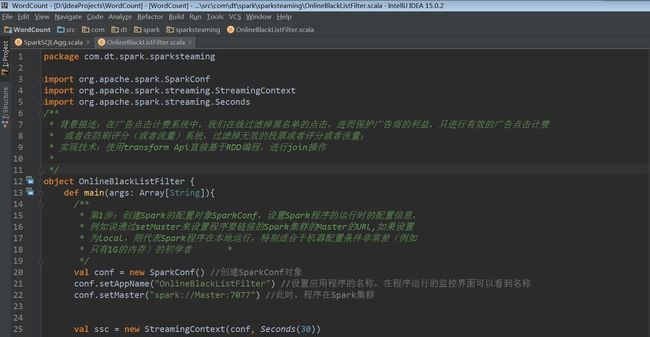

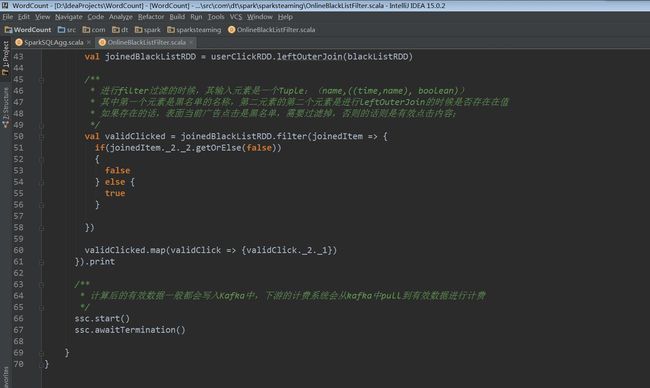
案例过程及其分析
a、打包程序,上传到集群上


b、 集群中需要先执行nc,启动 9999端口
nc -lk 9999
c、执行shell代码
sh内容
/usr/local/spark-1.6.1-bin-hadoop2.6/bin/spark-submit –class com.dt.spark.sparkstreaming.OnlineBlackListFilter –master spark://Master:7077 /root/Documents/SparkApps/WordCount.jar
我们运行完程序,看到过滤结果以后,停止程序,打开HistoryServer http://master:18080/

点击App ID进去,打开,会看到如下图所示的4个Job,从实际执行的Job是1个Job,但是图中显示有4个Job,从这里可以看出Spark Streaming运行的时候自己会启动一些Job。

先看看job id 为0 的详细信息

很明显是我们定义的blackListRDD数据的生成。对应的代码为
val blackList = Array((“Hadoop”, true), (“Mathou”, true))
//把Array变成RDD
val blackListRDD = ssc.sparkContext.parallelize(blackList)
并且它做了reduceBykey的操作(代码中并没有此步操作,SparkStreaming框架自行生成的)。
这里有两个Stage,Stage 0和Stage 1 。
Job 1的详细信息
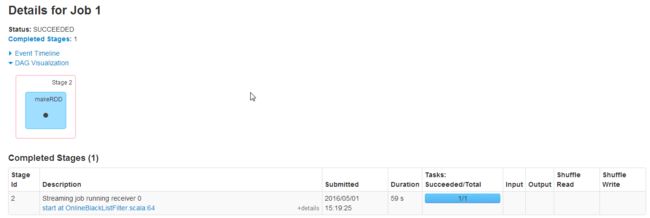
一个makeRDD,这个RDD是receiver不断的接收数据流中的数据,在时间间隔达到batchInterval后,将所有数据变成一个RDD。并且它的耗时也是最长的,59s 。
特别说明:此处可以看出,receiver也是一个独立的job。由此我们可以得出一个结论:我们在应用程序中,可以启动多个job,并且不用的job之间可以相互配合,这就为我们编写复杂的应用程序打下了基础。
我们点击上面的start at OnlineBlackListFilter.scala:64查看详细信息

根据上图的信息,只有一个Executor在接收数据,最最重要的是红色框中的数据本地性为PROCESS_LOCAL,由此可以知道receiver接收到数据后会保存到内存中,只要内存充足是不会写到磁盘中的。
即便在创建receiver时,指定的存储默认策略为MEMORY_AND_DISK_SER_2
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String] = withNamedScope(“socket text stream”) {
socketStream[String](hostname, port, SocketReceiver.bytesToLines, storageLevel)
}
job 2的详细信息


Job 2 将前两个job生成的RDD进行leftOuterJoin操作。
从Stage Id的编号就可以看出,它是依赖于上两个Job的。
Receiver接收数据时是在spark-master节点上,但是Job 2在处理数据时,数据已经到了spark-worker1上了(因为我的环境只有两个worker,数据并没有分散到所有worker节点,worker节点如果多一点,情况可能不一样,每个节点都会处理数据)
点击上面的Stage Id 3查看详细信息:

Executor上运行,并且有5个Task 。
Job 3的详细信息


总结:我们可以看出,一个batchInterval并不是仅仅触发一个Job。
根据上面的描述,我们更细致的了解了DStream和RDD的关系了。DStream就是一个个batchInterval时间内的RDD组成的。只不过DStream带上了时间维度,是一个无边界的集合。
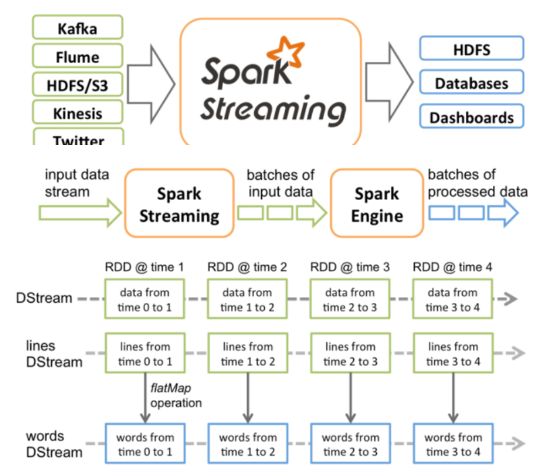
以上的连续4个图,分别对应以下4个段落的描述:
Spark Streaming接收Kafka、Flume、HDFS和Kinesis等各种来源的实时输入数据,进行处理后,处理结果保存在HDFS、Databases等各种地方。
Spark Streaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流。
Spark Streaming提供了表示连续数据流的、高度抽象的被称为离散流的DStream。DStream本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作。
Spark Streaming使用数据源产生的数据流创建DStream,也可以在已有的DStream上使用一些操作来创建新的DStream。
在我们前面的实验中,每300秒会接收一批数据,基于这批数据会生成RDD,进而触发Job,执行处理。
DStream是一个没有边界的集合,没有大小的限制。
DStream代表了时空的概念。随着时间的推移,里面不断产生RDD。
锁定到时间片后,就是空间的操作,也就是对本时间片的对应批次的数据的处理。
下面用实例来讲解数据处理过程。
从Spark Streaming程序转换为Spark执行的作业的过程中,使用了DStreamGraph。
Spark Streaming程序中一般会有若干个对DStream的操作。DStreamGraph就是由这些操作的依赖关系构成。
对DStream的操作会构建成DStream Graph
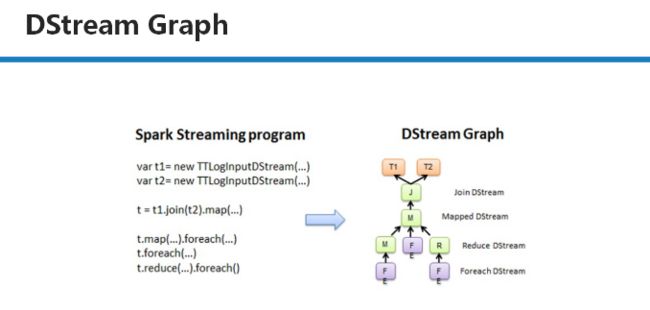
从每个foreach开始,都会进行回溯。从后往前回溯这些操作之间的依赖关系,也就形成了DStreamGraph。
在每到batchInterval时间间隔后,Job被触发,DStream Graph将会被转换成RDD Graph
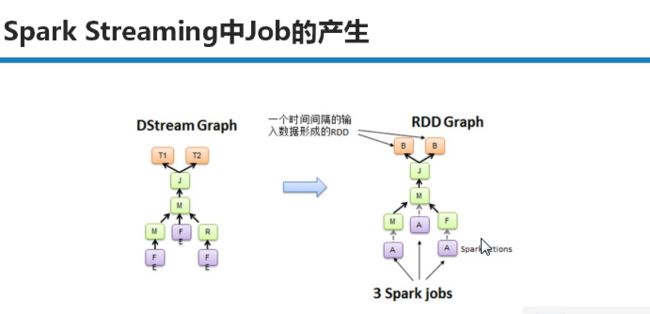
空间维度确定之后,随着时间不断推进,会不断实例化RDD Graph,然后触发Job去执行处理。
备注:
1、DT大数据梦工厂微信公众号DT_Spark
2、Spark大神级专家:王家林
3、新浪微博: http://www.weibo.com/ilovepains