时序列数据库武斗大会之 OpenTSDB 篇
【编者按】 刘斌,OneAPM后端研发工程师,拥有10多年编程经验,参与过大型金融、通信以及Android手机操作系的开发,熟悉Linux及后台开发技术。曾参与翻译过《第一本Docker书》、《GitHub入门与实践》、《Web应用安全权威指南》、《WEB+DB PRESS》、《Software Design》等书籍,也是Docker入门与实践课程主讲人。本文所阐述的「时间序列数据库」,系笔者所负责产品 Cloud Insight 对性能指标进行聚合、分组、过滤过程中的梳理和总结。
什么是 OpenTSDB
OpenTSDB ,可以认为是一个时系列数据(库),它基于HBase存储数据,充分发挥了HBase的分布式列存储特性,支持数百万每秒的读写,它的特点就是容易扩展,灵活的tag机制。
架构简介
这里我们简单看一下它的架构,如下图所示:
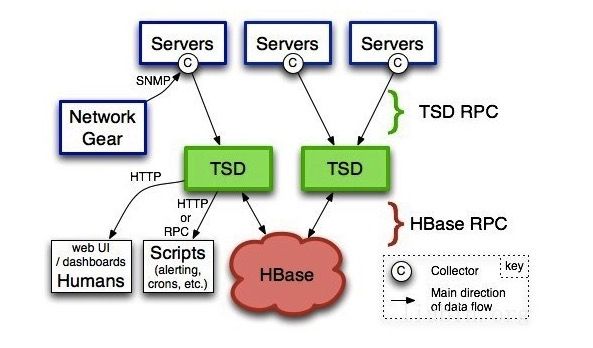
其最主要的部件就是TSD了,这是接收数据并存储到HBase处理的核心所在。而带有C(collector)标志的Server,则是数据采集源,将数据发给 TSD服务。
安装 OpenTSDB
为了安装 OpenTSDB ,都需要以下条件和软件:
Linux操作系统
JRE 1.6 or later
HBase 0.92 or later
安装GnuPlot
如果你还想使用自带的界面,则需要安装GnuPlot 4.2及以后版本,以及gd和gd-devel等。这里我们选择了GnuPlot 5.0.1的版本。
根据情况执行(没有就装),安装所需软件
$ sudo yum install -y gd gd-devel libpng libpng-devel
之后安装GnuPlot:
$ tar zxvf gnuplot-5.0.1.tar.gz$ cd gnuplot-5.0.1$ ./configure$ make$ sudo make install
安装HBase
首先,确保设置了JAVA_HOME:
$ echo $JAVA_HOME/usr
这个不多说了,非常简单,只需要按照 https://hbase.apache.org/book.html#quickstart 这里所说,下载、解压、修改配置文件、启动即可。
这时候,再设置HBASE_HOME:
$ echo $HBASE_HOME/opt/hbase-1.0.1.1
之后便可启动hbase:
$ /opt/hbase-1.0.1.1/bin/start-hbase.sh
starting master, logging to /opt/hbase-1.0.1.1/logs/hbase-vagrant-master-localhost.localdomain.out
安装 OpenTSDB
这个也很简单,如果build失败,那肯定是缺少Make或者Autotools等东西,用包管理器安装即可。
$ git clone git://github.com/OpenTSDB/opentsdb.git$ cd opentsdb$ ./build.sh
创建表OpenTSDB所需要的表结构:
$ env COMPRESSION=NONE ./src/create_table.sh2016-01-08 06:17:58,045 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
HBase Shell; enter ‘help‘ for list of supported commands.
Type “exit” to leave the HBase Shell
Version 1.0.1.1, re1dbf4df30d214fca14908df71d038081577ea46, Sun May 17 12:34:26 PDT 2015create ‘tsdb-uid’,
{NAME => ‘id’, COMPRESSION => ‘NONE’, BLOOMFILTER => ‘ROW’},
{NAME => ‘name’, COMPRESSION => ‘NONE’, BLOOMFILTER => ‘ROW’}0 row(s) in 1.3180 secondsHbase::Table – tsdb-uidcreate ‘tsdb’,
{NAME => ‘t’, VERSIONS => 1, COMPRESSION => ‘NONE’, BLOOMFILTER => ‘ROW’}0 row(s) in 0.2400 secondsHbase::Table – tsdbcreate ‘tsdb-tree’,
{NAME => ‘t’, VERSIONS => 1, COMPRESSION => ‘NONE’, BLOOMFILTER => ‘ROW’}0 row(s) in 0.2160 secondsHbase::Table – tsdb-treecreate ‘tsdb-meta’,
{NAME => ‘name’, COMPRESSION => ‘NONE’, BLOOMFILTER => ‘ROW’}0 row(s) in 0.4480 secondsHbase::Table – tsdb-meta
在habse shell里,可以看到表已经创建成功。
> listTABLE
tsdb
tsdb-metatsdb-treetsdb-uid4 row(s) in 0.0160 seconds
表创建之后,即可启动tsd服务,只需要运行如下命令:
$ build/tsdb tsd
如果看到输出:
2016-01-09 05:51:10,875 INFO [main] TSDMain: Ready to serve on /0.0.0.0:4242
即可认为启动成功。
保存数据到OpenTSDB.
在安装并启动所有服务之后,我们就来尝试发送1条数据吧。
最简单的保存数据方式就是使用telnet。
$ telnet localhost 4242put sys.cpu.user 1436333416 23 host=web01 user=10001
这时,从 OpenTSDB 自带界面都可以看到这些数据。 由于sys.cpu.sys的数据只有一条,所以 OpenTSDB 只能看到一个点。
下图为 OpenTSDB 自带的查询界面,访问http://localhost:4242即可。

OpenTSDB中的数据存储结构
我们来看看 OpenTSDB 的重要概念uid,先从HBase中存储的数据开始吧,我们来看一下它都有哪些表,以及这些表都是干什么的。
tsdb:存储数据点
hbase(main):003:0> scan 'tsdb'
ROW COLUMN+CELL
\x00\x00\x01U\x9C\xAEP\x00\x column=t:q\x80,timestamp=1436350142588, value=\x17
00\x01\x00\x00\x01\x00\x00\x
02\x00\x00\x02
1 row(s) in 0.2800 seconds
可以看出,该表只有一条数据,我们先不管rowid,只来看看列,只有一列,值为0x17,即十进制23,即该metric的值。
左面的row key则是 OpenTSDB 的特点之一,其规则为:
metric + timestamp + tagk1 + tagv1… + tagkN + tagvN
以上属性值均为对应名称的uid。
我们上面添加的metric为:
sys.cpu.user 1436333416 23 host=web01 user=10001
一共涉及到5个uid,即名为sys.cpu.user的metric,以及host和user两个tagk及其值web01和10001。
上面数据的row key为:
\x00\x00\x01U\x9C\xAEP\x00\x00\x01\x00\x00\x01\x00\x00\x02\x00\x00\x02
具体这个row key是怎么算出来的,我们来看看tsdb-uid表。
tsdb-uid:存储name和uid的映射关系
下面tsdb-uid表的数据,各行之间人为加了空行,为方便显示。
tsdb-uid用来保存名字和UID(metric,tagk,tagv)之间互相映射的关系,都是成组出现的,即给定一个name和uid,会保存(name,uid)和(uid,name)两条记录。

我们一共看到了8行数据。
前面我们在tsdb表中已经看到,metric数据的row key为\x00\x00\x01U\x9C\xAEP\x00\x00\x01\x00\x00\x01\x00\x00\x02\x00\x00\x02 ,我们将其分解下,用+号连起来(从name到uid的映射为最后5行):
\x00\x00\x01 + U + \x9C\xAE + P + \x00\x00\x01 + \x00\x00\x01 + \x00\x00\x02 + \x00\x00\x02
sys.cpu.user 1436333416 host = web01 user = 10001
可以看出,这和我们前面说到的row key的构成方式是吻合的。
需要着重说明的是时间戳的存储方式。
虽然我们指定的时间是以秒为单位的,但是,row key中用到的却是以一小时为单位的,即:1436333416 – 1436333416 % 3600 = 1436331600。
1436331600转换为16进制,即0x55 0x9c 0xae 0x50,而0x55即大写字母U,0x50为大写字母P,这就是4个字节的时间戳存储方式。相信下面这张图能帮助各位更好理解这个意思,即一小时只有一个row key,每秒钟的数据都会存为一列,大大提高查询的速度。
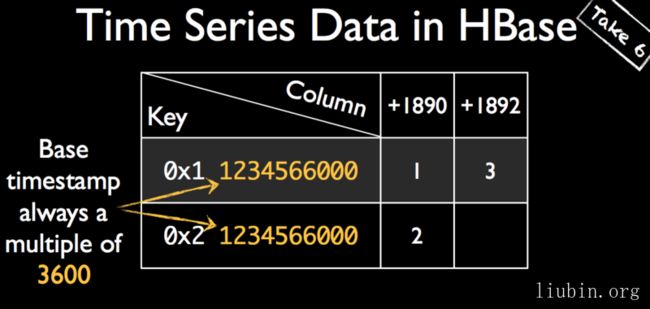
反过来,从uid到name也一样,比如找uid为\x00\x00\x02的tagk,我们从上面结果可以看到,该row key(\x00\x00\x02)有4列,而column=name:tagk的value就是user,非常简单直观。
重要:我们看到,上面的metric也好,tagk或者tagv也好,uid只有3个字节,这是 OpenTSDB 的默认配置,三个字节,应该能表示1600多万的不同数据,这对metric名或者tagk来说足够长了,对tagv来说就不一定了,比如tagv是ip地址的话,或者电话号码,那么这个字段就不够长了,这时可以通过修改源代码来重新编译 OpenTSDB 就可以了,同时要注意的是,重编以后,老数据就不能直接使用了,需要导出后重新导入。
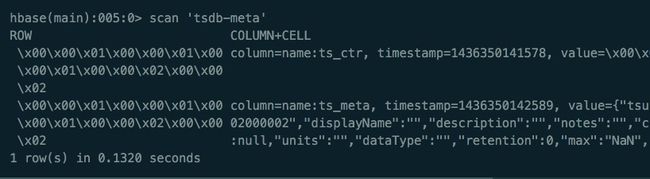
tsdb-meta:元数据表
我们再看下第三个表tsdb-meta,这是用来存储时间序列索引和元数据的表。这也是一个可选特性,默认是不开启的,可以通过配置文件来启用该特性,这里不做特殊介绍了。
tsdb-tree:树形表
第4个表是tsdb-tree,用来以树状层次关系来表示metric的结构,只有在配置文件开启该特性后,才会使用此表,这里我们不介绍了,可以自己尝试。
通过HTTP接口保存数据
保存数据除了我们前面用到的telnet方式,也可以选择HTTP API或者批量导入工具
import( http://opentsdb.net/docs/build/html/user_guide/cli/import.html )
这里我们再对HTTP API进行简单示例说明。
假设我们有如下数据,保存为文件mysql.json:
[
{
"metric": "mysql.innodb.row_lock_time",
"timestamp": 1435716527,
"value": 1234,
"tags": {
"host": "web01",
"dc": "beijing" } },
{
"metric": "mysql.innodb.row_lock_time",
"timestamp": 1435716529,
"value": 2345,
"tags": {
"host": "web01",
"dc": "beijing" } },
{
"metric": "mysql.innodb.row_lock_time",
"timestamp": 1435716627,
"value": 3456,
"tags": {
"host": "web02",
"dc": "beijing" } },
{
"metric": "mysql.innodb.row_lock_time",
"timestamp": 1435716727,
"value": 6789,
"tags": {
"host": "web01",
"dc": "tianjin" } }
]
之后执行如下命令:
$ curl -X POST -H “Content-Type: application/json” http://localhost:4242/api/put -d @mysql.json
即可将数据保存到 OpenTSDB 了。
查询数据
看完了如何保存数据,我们再来看看如何查询数据。
查询数据可以使用query接口,它既可以使用get的query string方式,也可以使用post方式以JSON格式指定查询条件,这里我们以后者为例,对刚才保存的数据进行说明。
首先,保存如下内容为search.json:
{
"start": 1435716527,
"queries": [
{
"metric": "mysql.innodb.row_lock_time",
"aggregator": "avg",
"tags": {
"host": "*",
"dc": "beijing" } }
]}
执行如下命令进行查询:
$ curl -s -X POST -H "Content-Type: application/json" http://localhost:4242/api/query -d @search.json | jq .
[
{ "metric": "mysql.innodb.row_lock_time", "tags": { "host": "web01", "dc": "beijing"
}, "aggregateTags": [], "dps": { "1435716527": 1234, "1435716529": 2345
}
},
{ "metric": "mysql.innodb.row_lock_time", "tags": { "host": "web02", "dc": "beijing"
}, "aggregateTags": [], "dps": { "1435716627": 3456
}
}
]
可以看出,我们保存了dc=tianjin的数据,但是并没有在此查询中返回,这是因为,我们指定了dc=beijing这一条件。
值得注意的是,tags参数在新版本2.2中,将不被推荐,取而代之的是filters参数。
总结
可以看出来, OpenTSDB 还是非常容易上手的,尤其是单机版,安装也很简单。有HBase作为后盾,查询起来也非常快,很多大公司,类似雅虎等,也都在用此软件。
但是,大规模用起来,多个TDB以及多存储节点等,应该都需要专业、细心的运维工作了。
相关阅读
这是本系列文章的其他部分:
时序列数据库武斗大会之什么是TSDB
时序列数据库武斗大会之TSDB名录 Part 1
时序列数据库武斗大会之TSDB名录 Part 2
时序列数据库武斗大会之KairosDB篇
Cloud Insight 集监控、管理、计算、协作、可视化于一身,帮助所有 IT 公司,减少在系统监控上的人力和时间成本投入,让运维工作更加高效、简单。
本文转自 OneAPM 官方博客