径向基函数(RBF)神经网络及matlab实现
本文摘自:《模式识别与智能计算——matlab技术实现第三版》与《matlab神经网络43个案例分析》
径向基函数神经网络的优点:逼近能力,分类能力和学习速度等方面都优于BP神经网络,结构简单、训练简洁、学习收敛速度快、能够逼近任意非线性函数,克服局部极小值问题。
RBF是具有单隐层的三层前向网络。第一层为输入层,由信号源节点组成。第二层为隐藏层,隐藏层节点数视所描述问题的需要而定,隐藏层中神经元的变换函数即径向基函数是对中心点径向对称且衰减的非负线性函数,该函数是局部响应函数。以前的前向网络变换函数都是全局响应的函数。第三层为输出层,是对输入模式做出的响应。输入层仅仅起到传输信号作用,输入层和隐含层之间之间可以看做连接权值为1的连接,输出层与隐含层所完成的任务是不同的,因而他们的学习策略也不同。输出层是对线性权进行调整,采用的是线性优化策略,因而学习速度较快;而隐含层是对激活函数(格林函数,高斯函数,一般取后者)的参数进行调整,采用的是非线性优化策略,因而学习速度较慢。
RBF神经网络的基本思想:用RBF作为隐单元的“基”构成隐藏层空间,隐藏层对输入矢量进行变换,将低维的模式输入数据变换到高维空间内,使得在低维空间内的线性不可分问题在高维空间内线性可分。详细一点就是用RBF的因单元的“基”构成隐藏层空间,这样就可以将输入矢量直接(不通过权连接)映射到隐空间。当RBF的中心店确定以后,这种映射关系也就确定 了。而隐含层空间到输出空间的映射是线性的,即网络输出是因单元输出的线性加权和,此处的权即为网络可调参数。
下图是径向基神经元模型
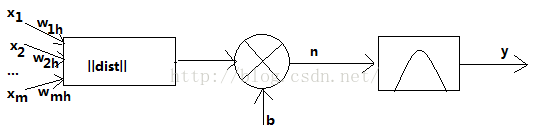
径向基函数的激活函数是以输入向量和权值向量之间的距离||dist||作为自变量的。径向基网络的激活函数的一般表达式为
![]()
随着权值和输入向量之间距离的减少,网络输出是递增的,当输入向量和权值向量一致时,神经元输出为1。图中的b为阈值,用于调整神经元的灵敏度。利用径向基神经元和线性神经元可以建立广义回归神经网络,此种神经网络适用于函数逼近方面的应用。径向基函数和竞争神经元可以建立概率神经网络,此种神经网络适用于解决分类问题。
RBF神经网络学习算法需要三个参数:基函数的中心,方差以及隐含层到输出层的权值。
RBF神经网络中心选取方法:
对于RBF神经网络的学习算法,关键问题是隐藏层神经元中心参数的合理确定。重用的方法是从中心参数(或者其初始值)是从给定的训练样本集里按照某种方法直接选取,或者是采用聚类的方法确定。
①直接计算法(随机选取RBF中心)
隐含层神经元的中心是随机地在输入样本中选取,且中心固定。一旦中心固定下来,隐含层神经元的输出便是已知的,这样的神经网络的连接权就可以通过求解线性方程组来确定。适用于样本数据的分布具有明显代表性。
②自组织学习选取RBF中心法
RBF神经网络的中心可以变化,并通过自组织学习确定其位置。输出层的线性权重则是通过有监督的学习来确定的。这种方法是对神经网络资源的再分配,通过 学习,使RBF得隐含层神经元中心位于输入空间重要的区域。这种方法主要采用K-均值聚类法来选择RBF的中心,属于无监督(导师)的学习方法。
③有监督(导师)学习选取RBF中心
通过训练样本集来获得满足监督要求的网络中心和其他权重参数。常用方法是梯度下降法。
④正交最小二乘法选取RBF中心法
正交最小二乘法(Orthogoal least square)法的思想来源于线性回归模型。神经网络的输出实际上是隐含层神经元某种响应参数(回归因子)和隐含层至输出层间连接权重的线性组合。所有隐含层神经元上的回归因子构成回归向量。学习过程主要是回归向量正交化的过程。
在很多实际问题中,RBF神经网络隐含层神经元的中心并非是训练集中的某些样本点或样本的聚类中心,需要通过学习的方法获得,使所得到的中心能够更好地反应训练集数据所包含的信息。
基于高斯核的RBF神经网络拓扑结构
第一层输入层:由信号源节点构成,仅起到数据信息的传递作用,对输入信息不做任何变换
第二层隐含层:节点数视需要而定。隐含层神经元核函数(作用函数)是高斯函数,对输入信息进行空间映射的变换。
第三层输出层,对输入模式做出相应。输出层神经元的作用函数为线性函数,对隐含层神经元输出的信息进行线性加权后输出,作为整个神经网络的输出结果。


径向基网络传递函数是以输入向量与阈值向量之间的距离|| X-Cj ||作为自变量的。其中|| X-Cj ||是通过输入向量和加权矩阵C的行向量的乘积得到的。径向基神经网络传递参数可以取多种形式。常见的有:
①Gaussian函数(高斯函数)
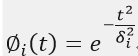
②Reflected sigmoidal函数(反常S型函数)

③逆Multiquadric函数(逆 畸变校正函数)
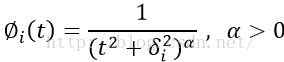
较为常用的还是Gaussian函数,本文采用Gaussian函数:![]()
当输入自变量为0时,传递函数取得最大值1,。随着权值和输入向量间的距离不断减小,网络输出是递增的。也就是说,径向基函数对输入信号在局部产生响应。函数的输入信号X靠近函数的中央范围时,隐含层节点将产生较大的输出。由此可以看出这种网络具有局部逼近能力。

当输入向量加到网络输入端时,径向基层每个神经元都会输出一个值,代表输入向量与神经元权值向量之间的接近程度。如果输入相联关于权值向量相差很多,则径向基层输出接近于0,;如果输入向量与权值向量很接近,则径向基层的输出接近于1,经过第二层(隐含层)的线性神经元,输出值就靠近第二层权值。在这个过程中,如果只有一个径向基神经元的输出为1,而其他神经元输出均为0或者接近0,那么线性神经元的输出就相当于输出为1的神经元对应的第二层(隐含层)权值的值。
RBF网络训练:
训练的目的是求两层的最终权值Cj、Dj和Wj。
训练的过程分为两步:第一步是无监督学习,训练确定输入层与隐含层间的权值Cj、Dj;第二步是有监督学习,训练确定隐含层与输出层间的权值Wj。
训练前提供输入向量X、对应的目标输出向量Y和径向基函数的宽度向量Dj。
在第 l 次输入样品(l=1,2,...,N)进行训练时,各个参数的表达及计算方法如下:
(1)确定参数
①确定输入向量X:
![]() ,n是输入层单元数
,n是输入层单元数
②确定输出向量Y和希望输出向量O
![]() ,q是输出层单元数
,q是输出层单元数
![]()
③初始化隐含层至输出层的连接权值
![]() (k=1,2,...,q)
(k=1,2,...,q)
参考中心初始化的方法: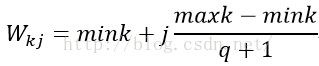 ,mink是训练集中第k个输出神经元中所有期望输出的最小值;maxk是训练集中第k个输出神经元中所有期望输出的最大值。
,mink是训练集中第k个输出神经元中所有期望输出的最小值;maxk是训练集中第k个输出神经元中所有期望输出的最大值。
④初始化隐含层各神经元的中心参数Cj=[cj1,cj2,...,cjn]^T。不同隐含层神经元的中心应有不同的取值,并且与中心的对应宽度能够调节,使得不同的输入信息特征能被不同的隐含层神经元最大的反映出来。在实际应用中,一个输入信息总是包含在一定的取值范围内。不失一般性,将隐含层各神经元的中心分量的初值,按从小到大等间距变化,使较弱的输入信息在较小的中心附近产生较强的响应。间距的大小可由隐藏层神经元的个数来调节。好处是能够通过试凑的方法找到较为合理的隐含层神经元数,并使中心的初始化尽量合理,不同的输入特征更为明显地在不同的中心处反映出来,体现高斯核的特点。
基于上述四项,RBF神经网咯中心参数的初始值为:
 (p为隐含层神经元总个数,j=1,2,...,p),mini是训练集中第i个特征所有输入信息的最小值,maxi为训练集中第i 个特征所有输入信息的最大值。
(p为隐含层神经元总个数,j=1,2,...,p),mini是训练集中第i个特征所有输入信息的最小值,maxi为训练集中第i 个特征所有输入信息的最大值。
⑤初始化宽度向量![]() 。宽度向量影响着神经元对输入信息的作用范围:宽度越小,相应隐含层神经元作用函数的形状越窄,那么处于其他神经元中心附近的信息在该神经元出的响应就越小。计算方法:
。宽度向量影响着神经元对输入信息的作用范围:宽度越小,相应隐含层神经元作用函数的形状越窄,那么处于其他神经元中心附近的信息在该神经元出的响应就越小。计算方法:
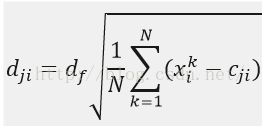 ,df为宽度调节系数,取值小于1,作用是使每个隐含层神经元更容易实现对局部信息的感受能力,有利于提高RBF神经网络的局部响应能力。
,df为宽度调节系数,取值小于1,作用是使每个隐含层神经元更容易实现对局部信息的感受能力,有利于提高RBF神经网络的局部响应能力。
(2)计算隐含层第j 个神经元的输出值zj
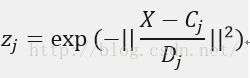 (j=1,2,....,p),Cj是隐含层第 j 个神经元的中心向量,由隐含层第j个神经元对应于输入层所有神经元的中心分量构成,
(j=1,2,....,p),Cj是隐含层第 j 个神经元的中心向量,由隐含层第j个神经元对应于输入层所有神经元的中心分量构成,![]() ;Dj为隐含层第j个神经元的宽度向量,与Cj相对应,
;Dj为隐含层第j个神经元的宽度向量,与Cj相对应,![]() ,Dj越大,隐含层对输入向量的影响范围就越大,且神经元间的平滑度也比较好;||.||为欧式范数。
,Dj越大,隐含层对输入向量的影响范围就越大,且神经元间的平滑度也比较好;||.||为欧式范数。
(3)计算输出层神经元的输出
![]()
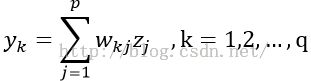 其中wkj为输出层第k个神经元与隐含层第 j 个神经元间的调节权重。
其中wkj为输出层第k个神经元与隐含层第 j 个神经元间的调节权重。
(4)权重参数的迭代计算
RBF神经网络权重参数的训练方法在这里取为梯度下降法。中心、宽度和调节权重参数均通过学习来自适应调节到最佳值,迭代计算如下:
![]()
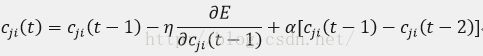

wkj(t) 为第k个输出神经元与第j个隐含层神经元之间在第t 次迭代计算时的调节权重。
cji(t)为第j 个隐含层神经元对于第i个输入神经元在第t 次迭代计算时的中心分量;
dji(t)为与中心cji(t)对应的宽度
η为学习因子
E为RBF神经网络评价函数:
 其中,Olk为第k 个输出神经元在第l 个输入样本时的期望输出值;ylk为第k个输出神经元在第l 个输入样本时的网络输出值。
其中,Olk为第k 个输出神经元在第l 个输入样本时的期望输出值;ylk为第k个输出神经元在第l 个输入样本时的网络输出值。
综上所述,给出RBF神经网络的学习算法:
① 按(1)确定参数的五个步骤对神经网络参数进行初始化,并给定η和α的取值及迭代终止精度ε 的值。
②按下式计算网络输出的均方根误差RMS 的值,若RMS≤ε ,则训练结束,否则转到第③步
③按照(4)权重迭代计算,对调节权重,中心和宽度参数进行迭代计算。
④返回步骤②