oracle and postgresql join method
先介绍oracle的几种多表连接方式:
NESTED LOOP:嵌套循环,其实就是双FOR循环
1.这里要分为驱动表(外部表)和查找表(内部表)
2.查找表要有索引,可以用过索引查找匹配,提高效率,
3.将小的表作为驱动表
4.两表的数据量不大
有些时候oracle优化器选定的驱动表和查找表并不合适,所以这里需要我们来指定查找表和驱动表,通过添加hint ,USE_NL提示,但是并不是总是有效,可以使用ordered use_nl(tab1 tab2)强制tab1为驱动表。注意,这里提到的所有环境都是CBO。
所以NESTED LOOP一般用在连接表中有索引,而且索引选择性较好。这里的内部原理就是选定一个驱动表(outer),一个查找表(inner),驱动表的每行都与查找表的记录匹配核对.驱动表的记录越少,则返回的结果集越快。
cost=outer access cost+(inner access cost*outer cardinality)
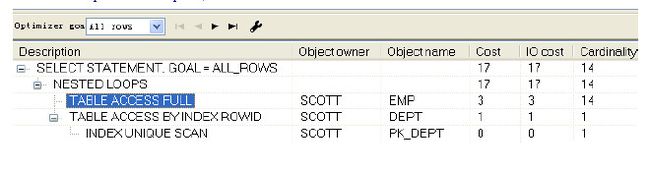
根据公式得出cost=3+(1*14)=17
HASH JOIN:哈希连接用于连接大的数据集,或者大表和小表的关联,优化器使用小表的连接字段在内存中建立哈希表,随后扫描大表,计算出大表连接字段的哈希值,判断能否在哈希列表中找到,成功返回数据,否则丢弃掉。如果表很大的情况下,无法完全放入到内存,那么优化器将会将它分为若干分区,不能放入内存的,那么就写入磁盘的临时段,所以此时要有较大的临时段来提高IO性能。
1.根据表的大小在内存中建立哈希表,然后对哈希表进行探测。
2.较小的表作为散列表,基于连接键建立哈希
3.CBO下工作
4.哈希表最好能够完全放入HASH_AREA_SIZE声明的内存中。

上图是最理想的情况下,实际环境中并非那么理想。解释一下图,首先在small data set过滤不必要的数据,生成hash表,也就是build hash,放入hash_area中,然后扫描big data set对行的简直做哈希运算然后到hash area中探测生成的哈希表,这里有bucket,bucket里有哈希列表,不多解释了,扫描列表 ,匹配成功返回数据,否则丢弃。
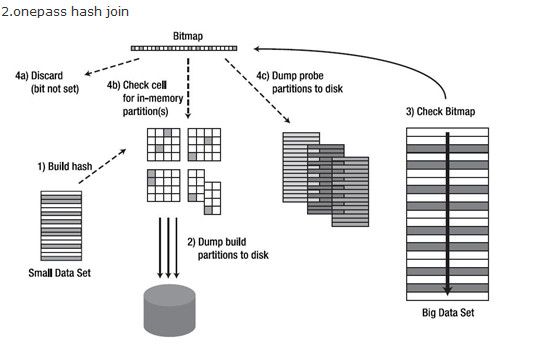
上图是onepass的情况,
当hash area无法容纳所有的分区,但是却足够容纳至少一个分区时,这种情况就是onepass hash join。需要首先对hash table做分区,然后将其写入到磁盘的临时空间,当hash table完成分区后,然后对probe table也用同样的hash函数作分区,然后对应的分区分别做join。需要注意的是,除了第一个分区,从第二个分区开始,Oracle会自动根据分区的大小来交换build table和probe table,以期望达到更好的性能。因为所有的分区只需要从磁盘上读取一次就可以完成,所以叫onepass.
1.扫描第二张表,对join键做hash运算,确定好对应的partition和bucket
2.查看bitmap,确定bucket是否有数据,没有则直接丢弃
3.如果有数据,并且这个partition是在内存中的,就进入对应的桶去精确匹配,能匹配上,就返回这行数据,否则丢弃
4.如果partition是在磁盘上的,则将这行数据放入磁盘中暂存起来,保存的形式也是partition,bucket的方式
5.当第二张表被扫描完后,剩下的是驱动表和探测表生成的一大堆partition,保留在磁盘上
6.由于两边的数据都按照相同的hash算法做了partition和bucket,现在只要成对的比较两边partition数据即可,并且在比较的时候,oracle也做了优化处理,没有严格的驱动与被驱动关系,他会在partition对中选较小的一个作为驱动来进行,直到磁盘上所有的partition对都join完
multipass
最差的hash join,此时hash area小到连一个partition也容纳不下,当扫描好驱动表后,可能只有半个partition留在hash area中,另半个加其他的partition全在磁盘上,剩下的步骤和onepass比价类似,不同的是针对partition的处理
由于驱动表只有半个partition在内存中,探测表对应的partition数据做探测时,如果匹配不上,这行还不能直接丢弃,需要继续保留到磁盘,和驱动表剩下的半个partition再做join,这里举例的是内存可以装下半个partition,如果装的更少的话,反复join的次数将更多,当发生multipass时,partition物理读的次数会显著增加。
cost = (outer access cost * # of hash partitions) + inner access cost
SORT MERGE JOIN
两表行源进行排序,这里没有驱动表和查找表,由于两边都已经排序,所以直接可以通过连接条件进行结果确定。
hash join偏重消耗CPU,而sort merge join偏重消耗IO,可以通过USE_MERGE(TAB1,TAB2)强制使用
触发规则:
RBO模式,不等价连接(>,>+,<,<=)
hash_join_enabled=false
数据源已经排序
cost的算法和hash join一样。
postgresql 连接方式:
和oracle一样,提供了三种连接方式,nested loop ,hash_join,merge join
NESTED LOOP:
举例:
SELECT oid
FROM pg_proc
ORDER BY 1
LIMIT 8;
CREATE TEMPORARY TABLE sample1 (id, junk) AS
SELECT oid, repeat('x', 250)
FROM pg_proc
ORDER BY random(); -- add rows in random order
CREATE TEMPORARY TABLE sample2 (id, junk) AS
SELECT oid, repeat('x', 250)
FROM pg_class
ORDER BY random(); -- add rows in random order
创建的这些表没有索引和统计信息
EXPLAIN SELECT sample2.junk
FROM sample1 JOIN sample2 ON (sample1.id = sample2.id)
WHERE sample1.id = 33;
QUERY PLAN
---------------------------------------------------------------------
Nested Loop (cost=0.00..253.42 rows=378 width=32)
-> Seq Scan on sample1 (cost=0.00..220.76 rows=54 width=4)
Filter: (id = 33::oid)
-> Materialize (cost=0.00..27.95 rows=7 width=36)
-> Seq Scan on sample2 (cost=0.00..27.91 rows=7 width=36)
Filter: (id = 33::oid)
(6 rows)
嵌套连接顺序扫描源码:
for (i = 0; i < length(outer); i++)
for (j = 0; j < length(inner); j++)
if (outer[i] == inner[j])
output(outer[i], inner[j]);
这里和oracle 的原理是一样的,就不再多解释。
HASH JOIN:
EXPLAIN SELECT sample1.junk
FROM sample1 JOIN sample2 ON (sample1.id = sample2.id)
WHERE sample2.id > 33;
QUERY PLAN
----------------------------------------------------------------------
Hash Join (cost=33.55..1097.55 rows=24131 width=32)
Hash Cond: (sample1.id = sample2.id)
-> Seq Scan on sample1 (cost=0.00..194.01 rows=10701 width=36)
-> Hash (cost=27.91..27.91 rows=451 width=4)
-> Seq Scan on sample2 (cost=0.00..27.91 rows=451 width=4)
Filter: (id > 33::oid)
HASH JOIN源码:
for (j = 0; j < length(inner); j++)
hash_key = hash(inner[j]);
append(hash_store[hash_key], inner[j]);
for (i = 0; i < length(outer); i++)
hash_key = hash(outer[i]);
for (j = 0; j < length(hash_store[hash_key]); j++)
if (outer[i] == hash_store[hash_key][j])
output(outer[i], inner[j]);
merge join:
EXPLAIN SELECT sample1.junk
FROM sample1 JOIN sample2 ON (sample1.id = sample2.id);
QUERY PLAN
--------------------------------------------------------------------------
Merge Join (cost=1005.10..2097.74 rows=72392 width=32)
Merge Cond: (sample2.id = sample1.id)
-> Sort (cost=94.90..98.28 rows=1353 width=4)
Sort Key: sample2.id
-> Seq Scan on sample2 (cost=0.00..24.53 rows=1353 width=4)
-> Sort (cost=910.20..936.95 rows=10701 width=36)
Sort Key: sample1.id
-> Seq Scan on sample1 (cost=0.00..194.01 rows=10701 width=36)
这里两表位置变化无影响。
merge join源码:
sort(outer);
sort(inner);
i = 0;
j = 0;
save_j = 0;
while (i < length(outer))
if (outer[i] == inner[j])
output(outer[i], inner[j]);
if (outer[i] <= inner[j] && j < length(inner))
j++;
if (outer[i] < inner[j])
save_j = j;
else
i++;
j = save_j;
ANALYZE sample1;
ANALYZE sample2;
有了统计信息后:
postgres=# EXPLAIN SELECT sample2.junk
postgres-# FROM sample1 JOIN sample2 ON (sample1.id = sample2.id);
QUERY PLAN
------------------------------------------------------------------------
Hash Join (cost=17.39..139.45 rows=284 width=254)
Hash Cond: (sample1.id = sample2.id)
-> Seq Scan on sample1 (cost=0.00..110.43 rows=2343 width=4)
-> Hash (cost=13.84..13.84 rows=284 width=258)
-> Seq Scan on sample2 (cost=0.00..13.84 rows=284 width=258)
CREATE INDEX i_sample1 on sample1 (id);
CREATE INDEX i_sample2 on sample2 (id);
建立相关索引后:
postgres=# EXPLAIN SELECT sample2.junk
postgres-# FROM sample1 JOIN sample2 ON (sample1.id = sample2.id)
postgres-# WHERE sample1.id = 33;
QUERY PLAN
---------------------------------------------------------------------------------
Nested Loop (cost=0.00..16.55 rows=1 width=254)
-> Index Scan using i_sample1 on sample1 (cost=0.00..8.27 rows=1 width=4)
Index Cond: (id = 33::oid)
-> Index Scan using i_sample2 on sample2 (cost=0.00..8.27 rows=1 width=258)
Index Cond: (id = 33::oid)
不再是Inner Sequential Scan,而是Inner Index Scan