机器学习:林智仁libsvm 工具箱 在matlab下的应用总结
好久没有写blog了,现在把之前做的东西做一下总结,也算是给上个学期一个交代。
- 简单介绍一下机器学习中的libsvm
- libsvm工具箱在matlab下的安装
- libsvm工具箱在matlab下的应用
- libsvm的实际应用
- 小结
一、机器学习中的libsvm介绍
支持向量机(SUPPORT VECTOR MACHINE),是非常强大且流行的算法,在一些情况下,能面向一些复杂的非线性问题提供比逻辑回归或神经网络要更加简洁的解决方案。
下面具体讲一下SVM

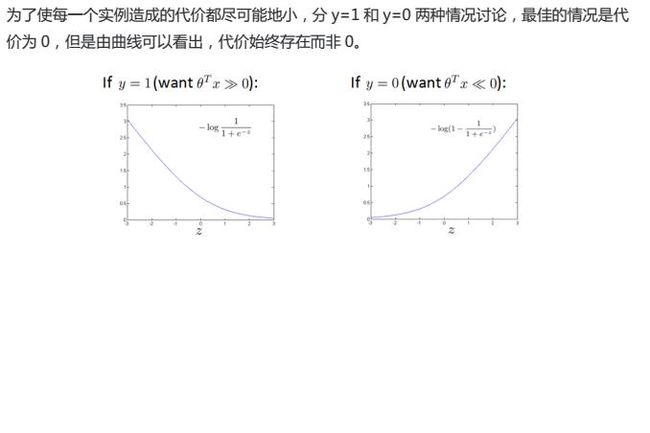

LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。该软件可以解决C-SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。
下面一个网站里面是大牛写的关于libsvm的一些东西,可以看看 关于libsvm的那点破事
二、libsvm在matlab下的安装
1、首先下载libsvm工具箱
下载网址:LIBSVM a library for support vector machines
上述网址是林智仁官网,可以从github中下载最新版本的libsvm
2、接着是将下载的工具箱安装
- 将libsvm-mat所在工具箱添加到matlab工作搜索目录
(File ——》
Set Path… ——》
Add with Subfolders…);- 选择编译器(mex -setup);
- 编译文件(make)。
详细的步骤讲解请看 LIBSVM 在matlab下的安装
这里我只说我遇到的问题,在选择编译器的时候不管是 y还是n 都找不到自己所安装的编译器,有可能是安装顺序的问题,我所解决的方法是,讲编译器和matlab卸载,然后重新安装,重安装的时候注意先安装编译器,再安装matlab
在编译文件make的时候出现找不到文件,需要进入到libsvm-master>matlab 中再make就可以了
三、 libsvm工具箱在matlab下的应用
详细的使用说明请看网址 如何使用LIBSVM进行分类
//%获取traindata、trainlabel,testdata、testlabel
traindata =[ train( : , 2 ), train( : , 4 ), train( : , 8 ), train( : , 10 )];
trainlabel = train( : , 14 );
testdata = [ test( : , 2 ), test( : , 4 ), test( : , 8 ), test( : , 10 ) ];
testlabel = test( : , 14 );
//%用traindata和trainlabel来训练出一个模型,引号里面参数的详细解释看上述网址的详解
model = svmtrain(trainlabel ,traindata,'-s 0 -t 2 -c 4 -g 1.2 -b 1');
save model model
//%用testdata、testlabel和训练出的模型进行做预测
[plabel, accuracy, dec_values] = svmpredict(testlabel,testdata,model,'-b 1');
save label.txt plabel -ascii
//%evaluate training results evaluate是自己写的一个评估函数
[TP,FN,FP,TN,POD,FAR,CSI,AUC,P,R,F] = Evaluate(plabel,testlabel);
save result P R F AUC CSI POD FAR TP FN FP TN dec_values
四、 libsvm的实际应用
1、获取原始数据
获取所需要的特征值和标签
2、将数据进行预处理
差分、归一化
(1)差分
由于气象中的特征,差分后的特征值会包含一些有用的信息,所以需要差分。新的特征值=原始特征值+差分(差分用的是向前差分 d(t)=data(t)-data(t-1))
(2)归一化
现在的归一化方法有两种max_min归一化和mu_sigma归一化。公式如下:
new—data=(data-min)/(max-min)
new—data=(data-mu)/sigma
经对比结果发现第一种归一化方法更适用于我们的应用。
3、训练、预测
这里的训练、预测如‘三、libsvm工具箱在matlab下的应用’中的代码
4、评估
对评估结果分析发现POD、CSI、FAR达不到要求,分析可能是由于正例置信度为0.5,即:当某一个样例的概率大于50%,预测此样例为正样例。如果想要提高各项预测值,需要获得每个样本的预测概率以此来修改置信度。
具体解决方法如下

如上图椭圆框出来的,在训练 svmtrain和预测 svmpredict的时候都加上参数‘-b 1’会得到 dec_values。 在我们的实验中(二分,label 有1和-1)dec_values分为2列,第一列为样例预测为-1的概率,第二列为样例预测为1的概率。这样我们就可以根据dec_values来调整阈值(正例置信度),以达到提高精确度的效果。
五、小结
通过这一阶段的学习我发现,不能怕遇到问题,遇到问题后不能急仔细查找各种解决的方法。要仔细分析。。。心细。。。