推荐系统概述
推荐系统是博主读研时的研究方向。看看自己目前的博客,没有一篇这方面的博文,五一假的最后一天,决定开始整理出来一系列的推荐系统相关的博客,希望能够帮助到有需要的读者。
就从概述开始吧。
一、推荐系统的发展
1992 年, Goldberg等人在帕洛阿尔托研究中心Tapestry系统]中第一次引入了协同过滤的思想。此后的三年内,用来对Usenet新闻消息进行自动协同过滤的Grouplens系统,对音乐专辑及艺术家进行协同过滤的Ringo系统,对电影进行协同过滤的贝尔视频推荐器相继出现,极大的促进了协同过滤技术的发展。
1997 年,Resnick在文献[1]中第一次正式提出推荐系统这个概念。这个时候的推荐系统实际上指的还是协同过滤。
此后,推荐系统受到学术界和商业界越来越多的关注,各种有关推荐系统的研究机构不断出现,关于推荐系统的相关研究成果层出不穷。作为一项技术,推荐系统在电子商务及一些智能管理应用中得到了广泛的应用。与此同时,随着很多学科的方法和研究者的加入,对推荐系统的研究得以获得更加迅猛的发展。2006年10月,在线DVD租赁公司Netflix发布了一个大概包含1亿匿名电影评分的数据集, 要求研究者能在该数据集上建立一个系统能够正确率上超越Netflix公司本身的推荐系统——Cinematch。这一竞赛吸引了大量的研究者加入,极大的促进了推荐系统的发展,提高了推荐系统在学术界和商业界的受关注度。
2007 年,来自明尼苏达大学的Joseph A. Konstan教授组织了第一届ACM推荐系统会议。至今,这一推荐系统领域最高级别的会议已经举办了7届。每一年都会吸引来自不同学科的研究者的参加。
如今,大数据时代给推荐系统的研究带来了新的挑战和机会。各种形式的数据涌现势必会对推荐系统的发展造成更大的影响。
二、主要方法
推荐系统作为一门交叉学科,吸引了来自复杂网络,机器学习,数据挖掘,信息检索,以及心理学和社会学等方面的许多学者。不同的学者纷纷从不同的角度提出了非常多的方法。显然,要对这些算法归类总结是一件非常困难的事。通常可以将推荐系统分为协同过滤系统、基于内容的推荐系统和混合推荐系统[2]。此外,本文还介绍了两种目前同样受到很大关注的推荐系统:基于知识的推荐系统和基于标签的推荐系统。
2.1 协同过滤推荐算法
协同过滤是最早提出,同时也是研究的最多,实际应用也最多的一种推荐技术[2~4]。对于协同过滤算法的分类,主要有两种分类方式。文献[5]考虑算法是否基于基本概率模型,将协同过滤算法分为非概率性算法和概率性算法。文献[2]将算法分为基于记忆的协同过滤算法和基于模型的协同过滤算法。本文采用后一种分类方式。
2.1.1.基于记忆的协同过滤
基于记忆的协同过滤算法[4]本质上是一种启发式的算法。 它是基于之前收集的所有用户的已评分产品来做产品评分预测。通常又包括基于用户的协同过滤算法和基于物品的协同过滤算法。基于用户的协同过滤利用了群体智慧,它的前提假设有两个:(a)过去有相同爱好的人,今后也更可能喜欢相似的产品,(b)用户的偏好随时间保持稳定。图2.1是一个基于用户的协同过滤系统的简单框架。基于物品的协同过滤没有邻居选择过程,直接基于评分矩阵计算物品之间的相似度来实现对待选择物品进行评分预测,最后生成推荐列表。

图2.1 基于用户的协同过滤系统的简单框架
2.1.2.基于模型的协同过滤
基于模型的协同过滤的主要思想是使用收集到的所有评分学习到一个模型,然后使用该模型去做评分预测。文献[4]提出了一种概率模型来计算未知的评分:

其中![]() 为目标用户u对待预测物品i的预测分。
为目标用户u对待预测物品i的预测分。表示u已评价物品集。评分的取值范围为0到n。为了计算概率,文献[4]提出了两种概率模型:聚类模型和贝叶斯网络。文献[6]提出了一个统计模型,以及比较了估计模型参数的几种不同算法,比如k均值聚类和吉布斯采样。文献[7]提出了一个贝叶斯模型,在计算用户相似度时,假定用户能够按照评分概率分布分到不同的子类中去,进而基于子类的后验分布和相关的评分概率来预测未知评分的分布。其他的基于模型的协同过滤方法还包括概率关系模型[8], 最大熵模型[9]和线性回归模型[3]等。此外,基于模型的协同过滤还使用了信息检索和机器学习方面的其他一些技术,比如神经网络,潜在语义索引等。
2.2 基于内容的推荐算法

图2.2 基于内容的推荐系统的框架[11]
2.2.1.内容分析
基于内容的推荐通常用在书籍,文件,网页,新闻等基于文本的物品的推荐上。这些物品通常采用非结构化数据来描述,为了后续的处理,通常需要对这些文本进行结构化。为了得到结构化信息来描述物品,可以借鉴信息检索的相关技术。最通常的方法是采用特征提取技术从非结构化的文本中抽取关键特征,建立一个特征向量来描述物品。基于文本的物品的内容可以用不同的方式转换成关键词向量表示。比如,最简单的方式是将所有可能出现在文本中的词设成一个列表,然后对于每个文本,用一个布尔型向量表示,向量不同位置上的数字如果是1,代表该位置所在的词出现在该文本中,0表示没有出现。这种表示方式存在两个很明显的问题。首先,该方法假定所有词对于文档的重要程度是一样的,显然,出现频率高的词更能代表文档。其次,文档越长,用户偏好与物品匹配的概率更高,造成的结果是推荐系统会倾向于推荐长文档。为了解决这两个问题,可以采用信息检索领域的TF-IDF技术来指定关键字的权重。TF-IDF包含两个子量:词频(TF)和反文档频率(IDF)。其中词频描述词在一篇文档中出现的频率。假设i表示关键字,j表示文档,表示关键字i在文档j中出现的频率,则词频(TF)可以定义如下:
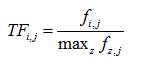
反文档频率(IDF)的宗旨是要根据区分文档的能力来给关键词赋权值。基于的出发点是那些在所有文档中都可能出现的常见词对于文档的区分没什么用,而那些仅在某些文档中出现的词更能区分文档。假设文档总数为N,![]() 表示关键词i出现过的文档数量,则i的反文档频率(IDF)定义如下:
表示关键词i出现过的文档数量,则i的反文档频率(IDF)定义如下:
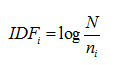
结合两个子量得到关键词i对于文档j最终的TF-IDF权值:
![]()
这样,文档可以用词的TF-IDF值向量,而不是布尔型向量来描述。
IF-IDF模型的一个显著缺陷是她会考虑可能出现的每个词,这样的结果是TF-IDF向量会很大,可能包含很多不相关的信息。处理这一缺陷的方法有删除停用词,词干提取,短语替关键词以及精简规模。
2.2.2.偏好学习
偏好学习也就是对用户的兴趣建模,从图2.2可以看出,它是基于内容分析的。方法首先会获知用户已经评价了的物品,对这些物品进行内容分析,得到用户偏好基于向量的描述形式。或者在用户已评价的物品的内容上,采用决策树,神经网络的方式来抽取用户偏好。
2.2.3.过滤
过滤过程就是一个用户偏好和物品内容匹配的过程。当两者都形式化后(比如都用基于关键词的向量描述),可以采用余弦相似度方法来评价物品和用户偏好的匹配度,也就是用户对物品的喜欢程度。
2.3 基于知识的推荐算法
推荐系统的目的是用一种个性化的方法帮助用户在很多的选择中找到感兴趣和有用的物品。协同过滤和基于内容的推荐系统由于多方面的因素,不管是在学术界还是工商界都得到了广泛的关注。这两种方法尽管具有很多无法替代的优势,但是在一些场景会变得不适用。协同过滤基于用户-物品评分矩阵,当评分矩阵非常稀疏性,推荐效果会不好。在一些书籍、电影、音乐的推荐上,由于用户“消费”这些产品相对会比较频繁,评分数据通常也比较充足,这时的推荐效果会比较好。然而,对于类似于电子产品、房子、汽车这样的产品,用户不会频繁消费,关于这些产品的评分记录自然会非常的少,这时候采用协同过滤效果自然不好。此外,用户对于汽车,房子以及金融产品的偏好可能会随着自己的生活方式,经济能力以及家庭状况发生变化,通过考虑用户几年前喜欢的物品的属性,采用基于内容的推荐算法,推荐的产品只会和过去的偏好匹配,可能无法满足用户现在的需求。最后,用户经常需要明确定义需求,比如“房子的大小不能小于x平米,主卧必须有独立卫生间”。纯粹的协同过滤和基于内容的推荐算法不擅于对这些需求进行形式化处理。
基于知识的推荐系统充分利用用户明确的需求以及关于产品邻域的深度知识,可以帮助处理这些问题。与协同过滤和基于内容的推荐相比,基于知识的推荐由于在每一轮会话中能直接获取需求,因而不存在冷启动问题。基于知识的推荐系统可以分为基于约束的推荐系统和基于案例推理的推荐系统。两者的不同之处在于如何使用获取的知识:基于案例推理的推荐系统着重于根据不同的相似度评估方法来检索相似物品,而基于约束的推荐系统依赖明确的推荐规则集合。
2.3.1 基于约束推荐
基于约束推荐就像是一个满足约束的过程。这些约束可能来自用户,比如用户对衣服的尺码要求;也可能来自产品本身或产品所属的领域,比如某些保险政策可能只提供给不吸烟的用户等。能够满足约束的产品就推荐给目标用户。图2.3是一个基于约束的推荐系统框架。

图2.3 基于约束的推荐系统
1.推荐知识库
基于约束推荐的推荐知识库包含两个不同模块,一个是变量集合模块,一个是约束条件模块。其中变量集合![]() 描述用户需求,
描述用户需求,![]()
描述物品属性;约束条件![]() 其中,CR是一致性约束,限定了用户属性的可能实例,比如短期投资与高风险投资相悖。CF是过滤条件,定义在什么条件下该选择什么产品,相当于定义了用户请求和物品属性间的关系。
其中,CR是一致性约束,限定了用户属性的可能实例,比如短期投资与高风险投资相悖。CF是过滤条件,定义在什么条件下该选择什么产品,相当于定义了用户请求和物品属性间的关系。![]() 是产品约束条件,限定产品属性的实例化。
是产品约束条件,限定产品属性的实例化。
2.过约束处理
在基于约束的推荐系统中,物品集中可能不存在任何物品满足所有的约束条件,这样造成的结果是系统不会推荐任何物品。造成这样的原因可能是约束条件
冲突[10],或者系统本身不存在满足约束的物品。通常来说,推荐系统提供的推荐结果是空集会影响用户的体验,所以应该避免。文献[11]提出了不同的方法,但根本目标都是确认放宽原始限制集合,也就是逐渐放宽推荐问题的限制,直到找到解决方案。
最直接的方法是采用简单的子集搜索找到原始约束的一个最大子集。尽管这种方法看上去可行,但是考虑计算有效性,对于任何一个包含n个限制的限制库,它可能的子集就有2n个,这在一个同时要为大量用户服务的实际推荐系统中来说是不实际的。针对此,国内外学者提出了其他更加有效的方法[12,13]。文献[12]不仅支持线性时间最小放宽计算,而且能够保证推荐物品的数量。文献[12]提出了一种基于人工定义特征层次的放宽方法。采用冲突检测的方法提出了能够交互且增量询问放宽的面向冲突的算法。
3.欠约束处理
如果约束条件不严格,可能导致在结果集中有太多满足的物品,这称之为欠约束问题。为了处理欠约束问题,文献[13]提出了一种互动询问管理方法,尽管目标是针对基于案例推理推荐算法,但同样适用于基于约束的推荐。该方法将一个询问和它的结果集作为输入,选择三个呈现给用户的特征作为建议来精炼询问。文献[14]定义了不同的特征选择方法,方法考虑了一个特征流行度的概率模型。
2.3.2 基于案例推理的推荐
案例推理是一种重要的基于知识的问题求解和学习方法。通过重新使用案例中特定的过去经验来尝试解决新问题,是一个循环和集成的问题解决过程。一个案例对过去的经历建模,保存问题描述以及相应的解。所有的案例保存在案例库中。当一个系统需要解决一个新问题时,它会在案例库中搜寻最相似的案例并重新使用检索出的解的一种修正版本来解决新问题。
案例推理一般包含四个步骤:检索,重用,适应以及保留。适应过程又可以分为两个子步骤:修订和复审。在修订阶段,系统采用解来适应新问题的特定限定。而在复审阶段,通过应用到新问题来评估构建的解,明白什么地方失败以及做一些有必要的改正。图2.4给出了案例推理的一个基本框架[15]

图2.4 基于案例推理的推荐系统
基于案例推理的推荐其实就是一个案例推理问题。下面分别说明基于案例推理的推荐系统的几个重要模块。
1.案例模型
案例保存在案例库中,当获知用户请求后,推荐系统会根据用户的请求从案例库中抽取相似的案例。为了方便比较不同的基于案例推理的推荐系统,文献[16]提出了一种案例库的表示方式:
其中,X是产品内容模型,U是用户模型,S是会话模型,E是评估模型。也就是说,一个案例c={x,u,s,e},其中x,u,s,e是X,U,S,E空间下相应的实体。下面分别介绍这四个模型。
内容模型(X):通常采用一个特征向量来描述产品。
用户模型(U):包含用户私有信息,比如性别,年龄,职业等以及用户过去的记录,比如喜欢的物品。很少基于案例推理的推荐系统利用这一模块。
会话模型(S):收集关于特定的推荐会话的信息。
评估模型(E):描述推荐的结果,也就是判断推荐是否合适。
事实上,有很多的系统只包括内容模块,这时候案例就代表一个产品;还有些系统可能仅包含会话模型。
2.系统与用户之间的交互
在推荐系统中目标描述指的用户的请求的具体描述,比如“买一台笔记本,价格不高于5000元,屏幕尺寸为15.6”。获知用户请求的具体描述后,推荐系统要从案例库中抽出相似的案例来满足用户。系统与用户的交互通常有两种方式:一种是单次交互,也就是被动地基于用户初始的请求来推荐物品。比如AnalogDevices OpAmp[18]、DubLet[10]。这种方式的缺点非常的明显:首先,对于某些产品,用户可能缺少相关的领域知识,初始很难提供正确的请求;其次,用户的初始请求通常是模糊的,随着系统提供的推荐物品,用户可能会更加明确自己的请求,这时候可能需要修改自己的请求;最后,基于用户初始请求的推荐列表长度可能为零,也就是在案例库中没有满足的案例,单次的交互方式只能够让用户修正自己的请求,系统重新开始推荐。另一种方式是会话式交互。这种方式让用户以一种可扩展性的、互动对话的方式来提供更多详细的请求以改进推荐。由于这种方式具有明显的优势,所以大多数基于案例推理的推荐系统都采用这种方式。
用户与系统的会话式交互又可以分为两种形式:询问式导航和提议式导航。
询问式导航通过询问来获取用户的请求,以此缩小推荐的范围直到最后只剩下少量物品。关于这种类型的推荐的研究有:文献[19]通过评价不同的问题选择标准研究会话中如何考虑会话中需要问的问题,问题的数量以及询问顺序,同时给出了一种基于熵的方式来评估给定特征的信息增益;文献[20]提出了一种叫做simVar的方法,方法考虑了给定特征对于案例库中案例相似性的影响,选择询问和那些对于案例相似性有最大影响的特征相关的问题;Adaptive Place Advisor[21]利用了询问式导航,能够帮助用户选择目的地。
提议式导航最大的特点是在每一轮推荐中向用户呈现不止一种推荐选择,邀请用户对这些选择提供反馈。用户提供的反馈主要有两种[17]:基于评分的反馈;基于评论的反馈。
3.相似度计算
相似度用来描述物品与用户需求间的匹配程度。已知用户的需求![]() ,需求q的权重Wq,物品i,物品相应需求q的属性值
,需求q的权重Wq,物品i,物品相应需求q的属性值![]()
表示物品和用户需求在需求q上的匹配程度,文献[22]提出了一种计算物品p和用户需求Uq的相似度方法:
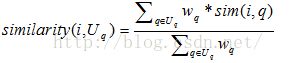
在实际的很多电子商务领域中,存在很多用户希望最大化的属性,比如电脑处理器的速度,这种属性称之为“越多越好”(MIB,More Is Better);也会有用户喜欢最小化的属性,比如电脑的价格,这种属性称之为“越少越好”(LIB,Less Is Better);除此之外,用户对某些属性可能有一个理想偏好值,物品的该属性越接近这一偏好值越好,我们称这样的属性为“越近越好”(NIB,Nearer Is Better)。公式(1)、(2)、(3)分别给出了关于这三种属性的局部相似度计算方法[23]:
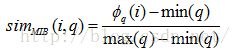 (1)
(1)
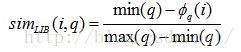 (2)
(2)
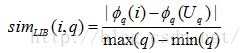 (3)
(3)
其中max(q)和min(q)为案例库中属性q的最大值和最小值。
2.4 基于标签的推荐算法
推荐系统的目的是帮助用户找到他感兴趣物品,这通常需要间接通过不同的媒介来实现。文献[24]表示目前流行的推荐系统基本可以通过3种不同的方式联系用户和感兴趣的物品。如图2.5[25]所示,第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,这是基于内容的推荐方法。第二种是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,这是协同过滤方法。除了这两种方法,第三种重要的方式是通过一些特征联系用户和物品,给用户推荐具有用户喜欢的特征的物品。这里的特征有不同的表现方式,比如可以表现为物品的属性集合,也可以表现为隐语义向量,这可以通过前面提出的隐语义模型学习得到。如果用标签来表示特征的话,将得到基于标签的推荐方法。

图2.5 推荐系统联系用户和物品的途径[25]
1.标签系统的方式
一般来说,一个标签推荐系统包含三个不同的元素:用户、物品和标签。同时可以有两种考虑它的方式:(1)三个集合,分别是:用户-{U1,U2,...,Un};物品-{I1,I2,...,Im};标签-{T1,T2,...,Tr}。这样,每一个二元关系——用户-物品,用户-标签,物品-标签——分别可以用邻接矩阵表示.如果相应的用户选择了物品,或者选择了某个标签,或者某个物品分配到了某个标签,就会把相应矩阵中相应的项的值设置为1,否则为0;(2)一个三元或者基于超图的结构。也就是说,只有完整的三元关系才将它看作一条真实存在的边。
2.分类
文献[26]将目前存在的基于标签的算法分为三类:
1)基于主题的方法。通过使用诸如pLSA和LDA的基于概率的方法从用户或者物品空间中有效的标签中抽取潜在的话题,继而通过使用基于概率的模型来产生推荐。目前该方法广泛的用来推荐物品和标签,在文献[27]中,作者提出了一
个基于pLSA的混合方法,结合用户-物品和物品-标签的共同出现来提供一个更好的物品推荐。
2)基于网络的方法。使用基于图论的方法(例如ProbS[28]),在用户-物品-标签的三元网络中将标签作为节点,继而应用一个扩散过程去产生推荐[29]。最终每个物品会获得两个值(来自两个扩散过程),利用![]() 得到最终的值,然后按值的大小给目标用户推荐物品。具体见参考文献[29].
得到最终的值,然后按值的大小给目标用户推荐物品。具体见参考文献[29].
3)基于张量的方法。使用张量分解将三元关系减少成低阶特征矩阵,减轻在大数据集中的稀疏性问题,最终提供个性化的推荐。具体参考文献[26]。
2.5 混合推荐算法
前面介绍的各种推荐方法都在一定程度上实现了个性化的推荐。但一方面,由于各自的缺陷受限于特定的应用场景;比如协同过滤存在冷启动和数据稀疏的问题,当数据评分稀疏时效果不好;基于内容的推荐,要获取物品的内容属性,在音乐,电影等属性不好抽取的物品上会遇到困难;基于知识的推荐要面对知识的获取和管理问题;而基于标签的方法会碰到标签的多义及同义分析问题等等。另一方面,系统中可能存在一些可以被一类推荐算法或多类算法使用的信息源。比如一个系统可能既包含评分数据,又包含可以方便抽取的物品内容属性。类似情况随着大数据时代的来临越来越容易出现。基于以上两点,越来越多的研究开始关注混合推荐系统,实现结合不同系统的优点,同时又能克服各自的缺点。比如,Netflix Prize竞赛中很多团队提出的推荐算法都是不同算法的混合。文献[2,30]总结出了混合的不同种策略。
文献[2]仅仅讨论了协同过滤和基于内容的混合方案,包括以下四种策略:
1)分别执行协同过滤和基于内容的推荐方法,然后合并预测结果。
2)在协同过滤方法中融入某些基于内容的特性;
3)在基于内容的方法中融入某些协同过滤的特性。
4)建立一个同时包含基于内容和协同过滤特性的整体模型。
文献[30]针对5种推荐算法(协同过滤、基于内容、基于知识、基于效用和基于人口统计属性)总结了七种不同混合策略:加权、切换、混合/交叉、特征组合、串联/层叠、特征补充、元级。
1)加权:加权混合方法首先分别先出候选物品,然后通过交集和并集的方式得到最终候选物品集。在此基础上,不同的推荐方法分开计算每个候选物品的评分,然后通过加权所有评分得到物品的最终评分。加权混合明显的好处是通过简单的加权结合了不同推荐方法的推荐能力。但是,如果结合的推荐方法“推荐方向”不一致,反而可能影响了推荐效果。比如,协同过滤对于物品评分稀疏的推荐效果很差,那么本来采用基于内容的推荐能够实现对这些物品准确推荐的结果由于和协同过滤混合而受影响。
2)切换:通过基于某种标准,在不同的推荐算法之间切换。这种混合方法基于思路是:没有哪种推荐算法在任何情况下都会表现很好。比如系统构建初期,评分非常稀疏,基于内容和协同过滤算法可能都不适应,然而基于知识的推荐算法不受评分稀疏影响,可以采用。当评分不在稀疏的时候,切换混合可以从基于知识的推荐中切换到协同过滤。切换混合面临的最大困难在于如何选择一个准确的切换标准。
3)交叉/混合:直接将各种推荐算法得到的推荐组合在一起展示给用户。该方法非常简单、直接,但同样存在如何对这些推荐排序的问题。
4)特征组合:从不同的知识源获取特征然后提供给单个算法。与前面说的几种混合最大的不同是,特征组合的推荐系统中只存在一个推荐模块。
5)串联/层叠:该混合策略是一种严格的分层混合,通常包含一个弱推荐算法和强推荐算法,预测主要由强推荐算法实现,弱推荐算法只在此基础上做点修善工作。
6)特征补充:使用一种技术从某个信息源中得到特征,进而将得到的特征作为另一种推荐技术输入的一部分。该混合策略的一大好处是,特征补充可以在线下处理。
7)元级/分层:使用一种技术来产生某类模型,进而将获得的模型作为下一种技术的输入。元级混合和特征补充的区别在于,前者是将模型作为输入,而后者是将特征作为下一种技术的输入。然而,并不是任何推荐方法都能够产生适合输入其他方法的模型。
关于这七种策略更具体的说明可以参考文献[30],文献[31]按照基本的设计思路,将这七种混合策略整理成了三类:
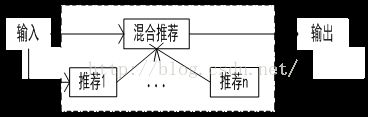
1.整体式混合设计;只包含一个推荐单元,通过对多个知识源预处理和组合来实现将不同的方法组合到一起,如图2.6所示。
2.并行式混合设计,通过利用一种混合机制将多种推荐系统的推荐结果整合到一起,如图2.7所示。

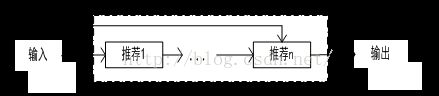
3.流线型混合设计。将整个推荐系统分成多个阶段,多种技术顺序执行,处在前面的推荐技术的输出作为后一种推荐技术的输入。如图2.8所示:
[2]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:A survey of the state-of-the-art and possiblie extensions.IEEE Transon Knowledge and Data Engineering,2005,17(6):734—749.
[3]Sarwar B, G. Karypis, JKonstan,et al. Item-based Collaborative Filtering Recommendation Algorithms. In: Proceedings of the 10th International WWW Conference. ?New York:ACM,2001,285-295.
[4]Breese, D. Heckerman, C. Kadie. Empirical analysis of predictive algorithms for collaborative filtering. In:Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence. Madison: Morgan-Kaufmann,1998,43-52.
[5]X. Su,T. M. Khoshgoftaar. A survey of collaborative filtering techniques. Advances in Articial Intelligence,2009,2009(4):1-19.
[6]Ungar, L. H., D. P. Foster. Clustering methods for collaborative filtering. In: AAAI Workshop on Recommendation Systems. Monona Terrace?:AAAI Press, 1998,114-129.
[7]Chien Y H, George E I. A bayesian model for collaborative filtering.In:Proceedings of the 7th International Workshop on Artificial Intelligence and Statistics. San Francisco: Morgan Kaufman,1999,3-8.
[8]Getoor, L. and M. Sahami. Using probabilistic relational models for collaborative filtering. In:Workshop on Web Usage Analysis and User Profiling (WEBKDD'99), San Diego:KDD,1999,1-6.
[9]Browning J, Miller D J. A maximum entropy approach for collaborative filtering. Journal of VLSI signal processing systems for signal, image and video technology, 2004, 37(2-3):199-209.
[10]Hurley G, Wilson D C. DubLet: An Online CBR System for Rental Property Recommendation.Case-Based Reasoning Research and Development. Berlin: Springer Berlin Heidelberg, 2001: 660-674.
[11]Felfernig A, Mairitsch M, Mandl M, et al. Utility-based repair of inconsistent requirements. Next-Generation Applied Intelligence.Berlin: Springer Berlin Heidelberg, 2009: 162-171.
[12]Jannach D. Fast computation of query relaxations for knowledge-based recommenders. AI Communications, 2009, 22(4): 235-248.
[13]Mirzadeh N, Ricci F, Bansal M. Supporting user query relaxation in a recommender system.E-Commerce and Web Technologies. Berlin:Springer Berlin Heidelberg, 2004: 31-40.
[14]Ricci F, Mirzadeh N, Venturini A. Intelligent query management in a mediator architecture. Proceedings of 2002 First International IEEE Symposium,IEEE, 2002, 3(1): 221-226.
[15]Mirzadeh N, Ricci F, Bansal M. Feature selection methods for conversational recommender systems. In: Proceedings of the 2005 IEEE International Conference on eTechnology, e-Commerce and e-Service on e-Technology, e-Commerce and e-Service, EEE2005. Washington: IEEE Computer Society, 2005, 772–777.
[16]Smyth B. Case-based recommendation.The adaptive web. Berlin: Springer Berlin Heidelberg, 2007: 342-376.
[17]Lorenzi F, Ricci F. Case-based recommender systems: a unifying view.Intelligent Techniques for Web Personalization. Berlin:Springer Berlin Heidelberg, 2005,89-113.
[18]Vollrath I, Wilke W, Bergmann R. Case-based reasoning support for online catalog sales. Internet Computing, IEEE, 1998, 2(4): 47-54.
[19]Doyle M, Cunningham P. A dynamic approach to reducing dialog in on-line decision guides.Advances in Case-Based Reasoning. Berlin:Springer Berlin Heidelberg, 2000: 49-60.
[20]Schmitt S. simvar: A similarity-influenced question selection criterion for e-sales dialogs. Artificial Intelligence Review, 2002, 18(3-4): 195-221..
[21]Thompson C A, G?ker M H, Langley P. A personalized system for conversati-
onal recommendations. J. Artif. Intell. Res.(JAIR), 2004, 21: 393-428.
[22]McSherry D. Similarity and compromise[M]//Case-Based Reasoning Research and Development. Berlin:Springer Berlin Heidelberg, 2003: 291-305.
[23]Polat H, Du W. SVD-based collaborative filtering with privacy. In: Proceedings of the 2005 ACM symposium on Applied computing. Santa Fe: ACM, 2005: 791-795..
[24]Vig J, Sen S, Riedl J. Tagsplanations: explaining recommendations using tags.In:Proceedings of the 14th international conference on Intelligent user interfaces. Sanibel Island: ACM, 2009,47-56.
[25]项亮,陈义,推荐系统实践.北京:图灵出版社,2012:96.
[26]Zhang Z K, Zhou T, Zhang Y C. Tag-aware recommender systems: a state-of-the-art survey. Journal of computer science and technology, 2011, 26(5): 767-777.
[27]Wetzker R, Umbrath W, Said A. A hybrid approach to item recommendation in folksonomies.In:Proceedings of the WSDM'09 Workshop on Exploiting Semantic Annotations in Information Retrieval. Barcelona :ACM, 2009: 25-29..
[28]Zhou T, Jiang L-L, Su R-Q, et al. Effect of initial configuration on network-based recommendation. Europhysics Letters,2008,81(5):1-4.
[29]Zhang Z K, Zhou T, Zhang Y C. Personalized recommendation via integrated diffusion on user–item–tag tripartite graphs. Physica A: Statistical Mechanics and its Applications, 2010, 389(1): 179-186.
[30]Burke R. Hybrid recommender systems: Survey and experiments. User modeling and user-adapted interaction, 2002, 12(4): 331-370.
[31]Zanker M, Felfernig A, Friedrich G. Recommender systems: an introduction[M]. Cambridge:Cambridge University Press, 2011,124-142.
Burke R. Hybrid recommender systems: Survey and experiments. User modeling and user-adapted interaction, 2002, 12(4): 331-370.