DBUtils源码分析
其实,在这篇文章里,我只是分析了dbutis的query的运作流程。
至于类为什么要这样设计,蕴含的设计模式等等高级知识点咱们在下节再探讨。
先看看最简单的DBUtils是如何工作的。
数据库里有一张表,student,里面就三个属性 姓名,学号,出生日期( xm,xh,birth)其中前两个是vchar,birth是date;package dbutils;
import model.Student;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.ResultSetHandler;
import org.junit.Test;
import java.sql.SQLException;
public class BeanExample {
@Test
public void testBean() {
QueryRunner qr = new QueryRunner(new MyDBSource());
String sql = "select * from student where xh=?";
Object params[] = { "02" };
Student s=null;
try {
ResultSetHandler<Student> rsh=new BeanHandler<>(Student.class);
s = qr.query(sql,rsh,params);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(s.getXm());
}
}
其中,MyDBSource就是个提供数据源的工具而已。
public class MyDBSource implements DataSource {
private static String driverClassName = "com.mysql.jdbc.Driver";
private static String url = "jdbc:mysql://localhost:3306/webexample";
private static String userName = "root";
private static String passWord = "root";
@Override
public Connection getConnection() throws SQLException {
try {
Class.forName(driverClassName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return DriverManager.getConnection(url, userName, passWord);
}
//....
}我们再看看BeanHandler的内部。
//BeanHandler.java
public BeanHandler(Class<T> type) {
this(type, ArrayHandler.ROW_PROCESSOR);
}
public BeanHandler(Class<T> type, RowProcessor convert) {
this.type = type;
this.convert = convert;
}
//ArrayHandler.java
public class ArrayHandler implements ResultSetHandler<Object[]> {
static final RowProcessor ROW_PROCESSOR = new BasicRowProcessor();
//....
}
//BasicRowProcessor.java
public class BasicRowProcessor implements RowProcessor {
private static final BeanProcessor defaultConvert = new BeanProcessor();
public BasicRowProcessor() {
this(defaultConvert);
}
//...
}
ok,我们可以看到在BeanHandler中的convert,最终是BeanProcessor类型。
再下来就是我们的重头戏了。
s = qr.query(sql,rsh,params);
我们看时序图
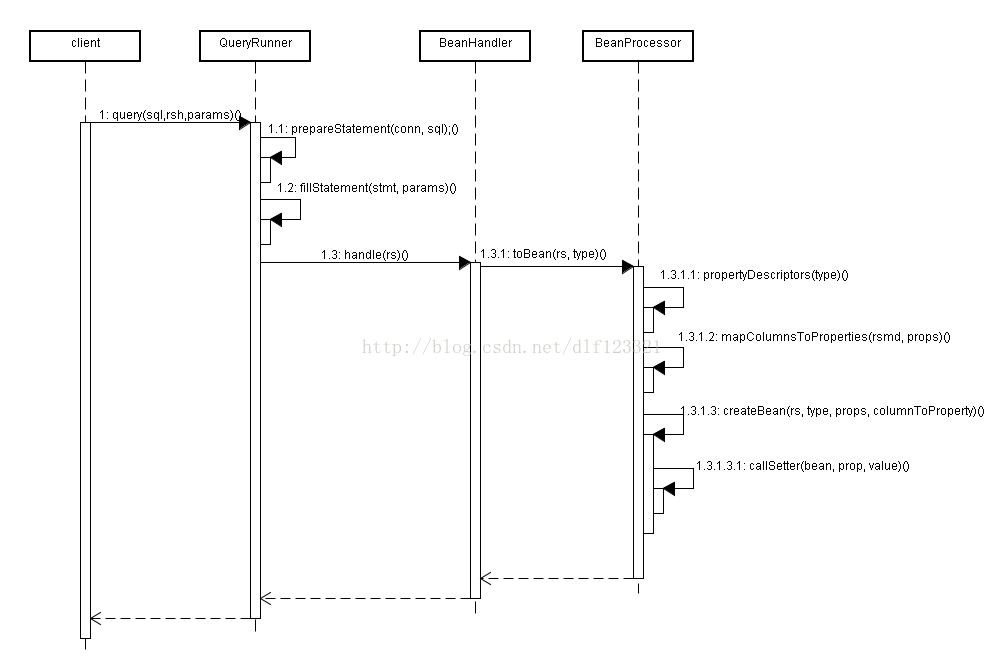
1.1 prepareStatement(conn, sql);
protected PreparedStatement prepareStatement(Connection conn, String sql)
throws SQLException {
return conn.prepareStatement(sql);
} 就是生成prepareStatement
1.2 fillStatement(stmt, params)
大家就是看名字也该知道,fillStatement就是填参数
其核心代码如下:
for (int i = 0; i < params.length; i++) {
if (params[i] != null) {
stmt.setObject(i + 1, params[i]);
}
//...
} 当然fillStatement在核心代码上面还有一块,就是检查sql中的问号数量与params的长度是否相等。
1.3 handle(rs)
BeanHandler.java
public T handle(ResultSet rs) throws SQLException {
return rs.next() ? this.convert.toBean(rs, this.type) : null;
} 在最开始分析BeanHandler的构造函数时,我们就已经知道了convert是BeanProcessor。
1.3.1 toBean(rs, this.type)
public <T> T toBean(ResultSet rs, Class<T> type) throws SQLException {
PropertyDescriptor[] props = this.propertyDescriptors(type);
ResultSetMetaData rsmd = rs.getMetaData();
int[] columnToProperty = this.mapColumnsToProperties(rsmd, props);
return this.createBean(rs, type, props, columnToProperty);
} 1.3.1.1 propertyDescriptors(type)
这是运用内省(Introspector)获得类型(就是代码里的Student.class)的属性(property)
1.3.1.2 mapColumnsToProperties(rsmd, props)
这一步比较麻烦,为什么说麻烦呢。
数据库里,一张表上有字段,现在这些字段存放在ResultSetMetaData里面
在我们的bean里面,有属性(property),现在存放在props这个数组里。
columnToProperty这里面就放的是字段与属性的对应关系。
例如 columnToProperty[3]=4 就是说ResultSetMetaData里的第三个字段对应于bean的PropertyDescriptor里面的第四个属性。
1.3.1.3 createBean(rs, type, props, columnToProperty)
//对源码略微有删改
//但绝对不影响核心思想
private <T> T createBean(ResultSet rs, Class<T> type,
PropertyDescriptor[] props, int[] columnToProperty)
throws SQLException {
T bean = this.newInstance(type);
for (int i = 1; i < columnToProperty.length; i++) {
PropertyDescriptor prop = props[columnToProperty[i]];
Class<?> propType = prop.getPropertyType();
Object value = null;
if(propType != null)
value = this.processColumn(rs, i, propType);
this.callSetter(bean, prop, value);
}
return bean;
} 在createBean里面
this.processColumn(rs, i, propType)
就是获得value,那么我们已经知道resultset,还有这个value在resultset中的序列号还有value类型,那么该如何获取呢?
代码我就不贴了,大家自己看源码吧,看上5秒钟就能知道内部逻辑了。
1.3.1.3.1 callSetter(bean, prop, value)
这里面的核心就是下面的代码
// Don't call setter if the value object isn't the right type
if (this.isCompatibleType(value, params[0])) {
setter.invoke(target, new Object[]{value});
} else {
throw new SQLException(
"Cannot set " + prop.getName() + ": incompatible types, cannot convert "
+ value.getClass().getName() + " to " + params[0].getName());
// value cannot be null here because isCompatibleType allows null
}
如果value是个String,params却是个double那就得抛出异常了。