spark基础(二)-----------scala在spark shell里的应用
这篇教程为使用spark提供一个快速的介绍。我们将先介绍spark shell的API(python or scala),然后展示如何用JAVA,PYTHON,SCALA写应用。
请先安装SPARK,下载地址http://spark.apache.org/downloads.html,由于我们不使用HDFS,可以基于任何hadoop版本。
通过spark shell进行交互式分析
启动spark shell
./bin/spark-shell
可以看到,交互shell已经为我们准备好了Spark context,变量名为sc,现在用它来提交一个作业。
RDD是Spark的一个关键概念,它对分布式数据集合进行了抽象,称为弹性分布式数据。RDDs可以由Hadoop的输入数据,比如HDFS文件创建,也可以由其它RDDs转换而来。下面由README.md文本文件创建了一个RDD.

RDD有动作,返回一个值。也有转换,返回一个新的RDDs.我们先来执行一些动作。

我们再来执行一次转换,我们使用filter转换操.返回一个新RDD,它包含了文本文件的一个子集合,只包含"Spark"字符串的行。

我们也可以连续进行转换和执行动作

更多的RDD操作
RDD的动作和转换可以进行更复杂的计算。我们现在找出包含单词最多的行。

第一个map操作将每一行映射为这一行的单词数,创建了一个新RDD。然后reduce操作找出单词数最多的行。map,reduce的参数是一个scala函数(闭包),我们可以使用任何Scala/Java的语言特性。比如,我们可以很容易的调用声明的函数,我们将使用Math.max函数将代码变得更易读。

另外一个常用的数据计算模型MapReduce,基于RDD模型,Spark也可以很容易的实现.
![]()
这里,我们组合使用flatMap,map和reduceByKey转换来计算文件中每个单词的个数。文件被抽象为一个(String,Int)元组的RDD。我们用collect操作在spark shell里收集每个单词的个数
![]()
缓存
Spark也支持将数据提取到集群范围内的缓存中。这对频繁访问的数据十分有用。比如,我们访问一小组热点的数据在PageRank这种迭代算法中。作为一个简单的示例,让我们把我们的lineWithSpark数据集合标记为缓存的。
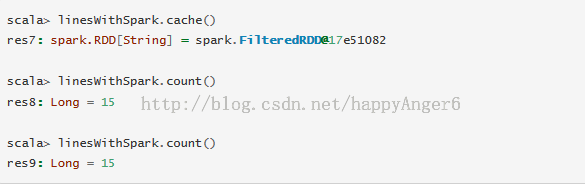
将一个几百行的文本文件用spark来浏览和缓存看起来很愚蠢。但它是看起来很有趣,因为同样的函数可以用在每一个大的数据集上,而不用关心它们分布的数百上行的节点之上。
自己写应用程序
我们现在用spark API写一个应用程序.这个简单的应用程序,可以使用SBT(SCALA),Maven(JAVA),Python.
先用SCALA写一个示例
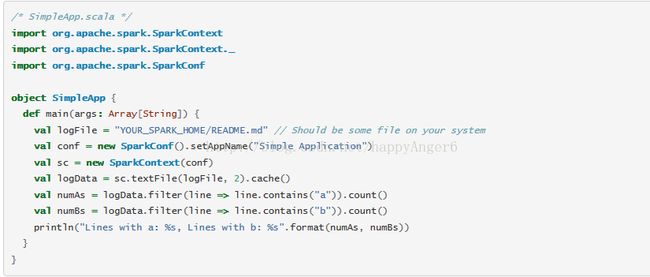
这个程序只是简单的统计文件中包含'a'和'b'的行数。YOUR_SPARK_HOME是你的spark安装目录。
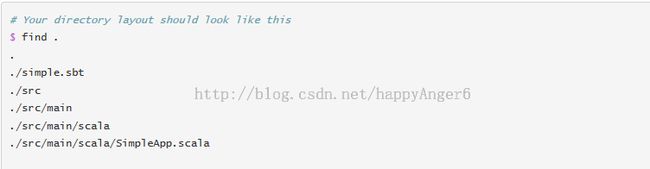
我们的程序依懒spark api的lib所以还要编辑simple.sbt配置文件:

注意,我们使用sbt构建这个程序,所以要先下载安装sbt.并且程序的目录结构要符合sbt的约定。
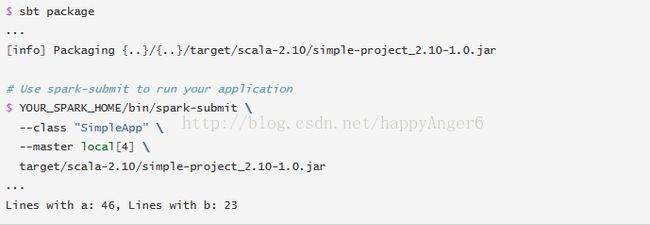
最后我们用sbt打包刚才的程序,并用spark-submit提交运行
翻译自:
http://spark.apache.org/docs/latest/quick-start.html