R语言︱异常值检验、离群点分析、异常值处理
笔者寄语:异常值处理一般分为以下几个步骤:异常值检测、异常值筛选、异常值处理。
其中异常值检测的方法主要有:箱型图、简单统计量(比如观察极值)
异常值处理方法主要有:删除法、插补法、替换法。
提到异常值不得不说一个词:鲁棒性。就是不受异常值影响,一般是鲁棒性高的数据,比较优质。
一、异常值检验
异常值大概包括缺失值、离群值、重复值。
1、缺失值检验
关于缺失值的检测应该包括:缺失值数量、缺失值比例、缺失值与完整值数据筛选。
#缺失值解决方案 sum(complete.cases(saledata)) #is.na(saledata) sum(!complete.cases(saledata)) mean(!complete.cases(saledata)) #1/201数字,缺失值比例 saledata[!complete.cases(saledata),] #筛选出缺失值的数值
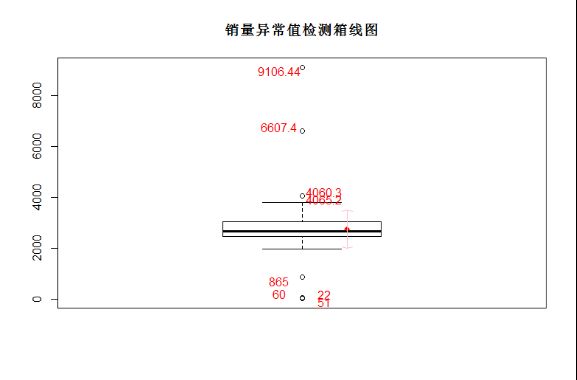
2、箱型图检验离群值
箱型图的检测包括:四分位数检测(箱型图自带)+1δ标准差上下+异常值数据点。
箱型图有一个非常好的地方是,boxplot之后,结果中会自带异常值,就是下面代码中的sp$out,这个是做箱型图,按照上下边界之外为异常值进行判定的。
上下边界,分别是Q3+(Q3-Q1)、Q1-(Q3-Q1)。
sp=boxplot(saledata$"销量",boxwex=0.7)
title("销量异常值检测箱线图")
xi=1.1
sd.s=sd(saledata[complete.cases(saledata),]$"销量")
mn.s=mean(saledata[complete.cases(saledata),]$"销量")
points(xi,mn.s,col="red",pch=18)
arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1)
text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels=sp$out[order(sp$out)],
sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col="red")
代码中text函数的格式为text(x,label,y,col);points加入均值点;arrows加入均值上下1δ标准差范围箭头。
3、数据去重
数据去重与数据分组合并存在一定区别,去重是纯粹的所有变量都是重复的,而数据分组合并可能是因为一些主键的重复。
数据去重包括重复检测(table、unique函数)以及重复数据处理(unique/duplicated)。
常见的有unique、数据框中duplicated函数。
二、异常值处理
常见的异常值处理办法是删除法、替代法(连续变量均值替代、离散变量用众数以及中位数替代)、插补法(回归插补、多重插补)
除了直接删除,可以先把异常值变成缺失值、然后进行后续缺失值补齐。
1、异常值识别
利用图形——箱型图进行异常值检测。
#异常值识别 par(mfrow=c(1,2))#将绘图窗口划为1行两列,同时显示两图 dotchart(inputfile$sales)#绘制单变量散点图,多兰图 pc=boxplot(inputfile$sales,horizontal=T)#绘制水平箱形图代码来自 《R语言数据分析与挖掘实战》第四节。
2、异常值查找与分段
#异常数据处理 inputfile$sales[5]=NA #将异常值处理成缺失值 fix(inputfile)#表格形式呈现数据 which(inputfile$sales==6607.4)#可以找到极值点序号是啥把缺失值数据集、非缺失值数据集分开。
#缺失值的处理 inputfile$date=as.numeric(inputfile$date)#将日期转换成数值型变量 sub=which(is.na(inputfile$sales))#识别缺失值所在行数 inputfile1=inputfile[-sub,]#将数据集分成完整数据和缺失数据两部分 inputfile2=inputfile[sub,]
3、异常值处理——均值替换
数据集分为缺失值、非缺失值两块内容。缺失值处理如果是连续变量,可以选择均值;离散变量,可以选择众数或者中位数。
计算非缺失值数据的均值,
然后赋值给缺失值数据。
#均值替换法处理缺失,结果转存 #思路:拆成两份,把缺失值一份用均值赋值,然后重新合起来 avg_sales=mean(inputfile1$sales)#求变量未缺失部分的均值 inputfile2$sales=rep(avg_sales,n)#用均值替换缺失 result2=rbind(inputfile1,inputfile2)#并入完成插补的数据
4、异常值处理——回归插补法
#回归插补法处理缺失,结果转存 model=lm(sales~date,data=inputfile1)#回归模型拟合 inputfile2$sales=predict(model,inputfile2)#模型预测 result3=rbind(inputfile1,inputfile2)
5、异常值处理——多重插补——mice包
比较详细的来介绍一下这个多重插补法。笔者整理了大致的步骤简介如下:
缺失数据集——MCMC估计插补成几个数据集——每个数据集进行插补建模(glm、lm模型)——将这些模型整合到一起(pool)——评价插补模型优劣(模型系数的t统计量)——输出完整数据集(compute)
步骤详细介绍:
函数mice()首先从一个包含缺失数据的数据框开始,然后返回一个包含多个(默认为5个)完整数据集的对象。
每个完整数据集都是通过对原始数据框中的缺失数据进行插补而生成的。 由于插补有随机的成分,因此每个完整数据集都略有不同。
然后, with()函数可依次对每个完整数据集应用统计模型(如线性模型或广义线性模型) ,
最后, pool()函数将这些单独的分析结果整合为一组结果。最终模型的标准误和p值都将准确地反映出由于缺失值和多重插补而产生的不确定性。
#多重插补法处理缺失,结果转存 library(lattice) #调入函数包 library(MASS) library(nnet) library(mice) #前三个包是mice的基础 imp=mice(inputfile,m=4) #4重插补,即生成4个无缺失数据集 fit=with(imp,lm(sales~date,data=inputfile))#选择插补模型 pooled=pool(fit) summary(pooled) result4=complete(imp,action=3)#选择第三个插补数据集作为结果
结果解读:
(1)imp对象中,包含了:每个变量缺失值个数信息、每个变量插补方式(PMM,预测均值法常见)、插补的变量有哪些、预测变量矩阵(在矩阵中,行代表插补变量,列代表为插补提供信息的变量, 1和0分别表示使用和未使用);
同时 利用这个代码imp$imp$sales 可以找到,每个插补数据集缺失值位置的数据补齐具体数值是啥。
> imp$imp$sales
1 2 3 4
9 3614.7 3393.1 4060.3 3393.1
15 2332.1 3614.7 3295.5 3614.7
(2)with对象。插补模型可以多样化,比如lm,glm都是可以直接应用进去,详情可见《R语言实战》第十五章;
(3)pool对象。summary之后,会出现lm模型系数,可以如果出现系数不显著,那么则需要考虑换插补模型;
(4)complete对象。m个完整插补数据集,同时可以利用此函数输出。
其他:
mice包提供了一个很好的函数md.pattern(),用它可以对缺失数据的模式有个更好的理解。还有一些可视化的界面,通过VIM、箱型图、lattice来展示缺失值情况。可见博客:在R中填充缺失数据—mice包
三、离群点检测
离群点检测与第二节异常值主要的区别在于,异常值针对单一变量,而离群值指的是很多变量综合考虑之后的异常值。下面介绍一种基于聚类+欧氏距离的离群点检测方法。
基于聚类的离群点检测的步骤如下:数据标准化——聚类——求每一类每一指标的均值点——每一类每一指标生成一个矩阵——计算欧式距离——画图判断。
Data=read.csv(".data.csv",header=T)[,2:4]
Data=scale(Data)
set.seed(12)
km=kmeans(Data,center=3)
print(km)
km$centers #每一类的均值点
#各样本欧氏距离,每一行
x1=matrix(km$centers[1,], nrow = 940, ncol =3 , byrow = T)
juli1=sqrt(rowSums((Data-x1)^2))
x2=matrix(km$centers[2,], nrow = 940, ncol =3 , byrow = T)
juli2=sqrt(rowSums((Data-x2)^2))
x3=matrix(km$centers[3,], nrow = 940, ncol =3 , byrow = T)
juli3=sqrt(rowSums((Data-x3)^2))
dist=data.frame(juli1,juli2,juli3)
##欧氏距离最小值
y=apply(dist, 1, min)
plot(1:940,y,xlim=c(0,940),xlab="样本点",ylab="欧氏距离")
points(which(y>2.5),y[which(y>2.5)],pch=19,col="red")