Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.2
[原]Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.2
2015-5-28阅读62 评论0
Spark MLlib Deep Learning Neural Net(深度学习-神经网络)1.2
http://blog.csdn.net/sunbow0
第一章Neural Net(神经网络)
2基础及源码解析
2.1 Neural Net神经网络基础知识2.1.1 神经网络
基础知识参照:
http://deeplearning.stanford.edu/wiki/index.php/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
2.1.2 反向传导算法
基础知识参照:
http://deeplearning.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95
2.1.3 Denoise Autoencoder
当采用无监督的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在网络的可视层(即数据的输入层)引入随机噪声,这种方法称为Denoise Autoencoder(简称dAE),具体加入的方法就是把训练样例中的一些数据调整变为0,inputZeroMaskedFraction表示了调整的比例
这部分请参见《Extracting and Composing Robust Features with Denoising Autoencoders》这篇论文。参照:
http://wenku.baidu.com/link?url=lhFEf7N3n2ZG2K-mfWsts2on9gN5K-KkrMuuNvHU2COdehkDv9vxVsw-F23e5Yiww_38kWYB56hskLXwVp0_9c7DLw7XZX_w8NoNXfxtoIm
2.1.4 Dropout
训练神经网络模型时,如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种trikc供选择。Dropout是hintion最近2年提出的,源于其文章Improving neural networks by preventing co-adaptation of feature detectors.中文大意为:通过阻止特征检测器的共同作用来提高神经网络的性能。
Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。参照:
http://wenku.baidu.com/link?url=WpsRjVTrMIhCNqDSDnzm8M6nz2Q7AoNhpnY2XxM9SFYkGni8t94JOgsZUCbSuccOnO8mJyGx67RGLjPr8D9aoxhyOUkYtvfitU9ilaQ-Rqm
2.1.5 Sparsity Penalty
对神经网络每层节点的sparsity计算,对没达到sparsitytarget的参数的惩罚系数的节点进行惩罚。
2.2 Deep Learning NN源码解析
2.2.1 NN代码结构
NN源码主要包括:NeuralNet,NeuralNetModel两个类,源码结构如下:

NeuralNet结构:

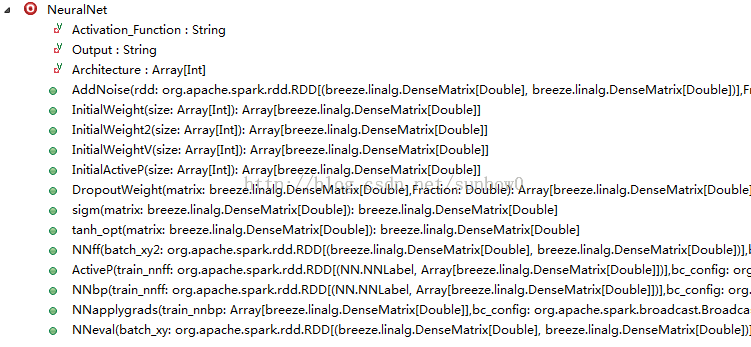
NeuralNetModel结构:

2.2.2 NN训练过程
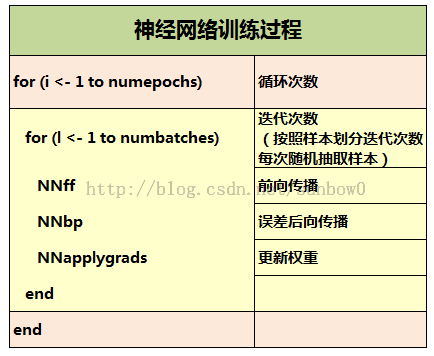
2.2.3 NeuralNet解析
(1)NNLabel
/**
* label:目标矩阵
*nna:神经网络每层节点的输出值,a(0),a(1),a(2)
* error:输出层与目标值的误差矩阵
*/
caseclass NNLabel(label: BDM[Double],nna: ArrayBuffer[BDM[Double]],error: BDM[Double])extends Serializable
NNLabel:自定义数据类型,存储样本数据,格式:目标值,输出值,误差。
(2) NNConfig
/**
*配置参数
*/
caseclassNNConfig(
size: Array[Int],
layer: Int,
activation_function: String,
learningRate: Double,
momentum: Double,
scaling_learningRate: Double,
weightPenaltyL2: Double,
nonSparsityPenalty: Double,
sparsityTarget: Double,
inputZeroMaskedFraction: Double,
dropoutFraction: Double,
testing: Double,
output_function: String)extends Serializable
NNConfig:定义参数配置,存储配置信息。参数说明:
size:神经网络结构
layer:神经网络层数
activation_function:隐含层函数
learningRate:学习率
momentum: Momentum因子
scaling_learningRate:学习迭代因子
weightPenaltyL2:正则化L2因子
nonSparsityPenalty:权重稀疏度惩罚因子
sparsityTarget:权重稀疏度目标值
inputZeroMaskedFraction:权重加入噪声因子
dropoutFraction: Dropout因子
testing: testing
(3) InitialWeight
初始化权重
/**
* 初始化权重
* 初始化为一个很小的、接近零的随机值
*/
def InitialWeight(size: Array[Int]): Array[BDM[Double]] = {
// 初始化权重参数
// weights and weight momentum
// nn.W{i - 1} = (rand(nn.size(i), nn.size(i - 1)+1) - 0.5) * 2 * 4 * sqrt(6 / (nn.size(i) + nn.size(i - 1)));
valn = size.length
valnn_W = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.rand(size(i), size(i - 1) + 1)
d1 :-= 0.5
valf1 =2 *4 * sqrt(6.0 / (size(i) + size(i -1)))
vald2 =d1 :*f1
//val d3 = new DenseMatrix(d2.rows, d2.cols, d2.data, d2.isTranspose)
//val d4 = Matrices.dense(d2.rows, d2.cols, d2.data)
nn_W += d2
}
nn_W.toArray
}
(4) InitialWeightV
初始化权重vW
/**
* 初始化权重vW
* 初始化为0
*/
def InitialWeightV(size: Array[Int]): Array[BDM[Double]] = {
// 初始化权重参数
// weights and weight momentum
// nn.vW{i - 1} = zeros(size(nn.W{i - 1}));
valn = size.length
valnn_vW = ArrayBuffer[BDM[Double]]()
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](size(i), size(i - 1) + 1)
nn_vW += d1
}
nn_vW.toArray
}
(5) InitialActiveP
初始神经网络激活度
/**
* 初始每一层的平均激活度
* 初始化为0
*/
def InitialActiveP(size: Array[Int]): Array[BDM[Double]] = {
// 初始每一层的平均激活度
// average activations (for use with sparsity)
// nn.p{i} = zeros(1, nn.size(i));
valn = size.length
valnn_p = ArrayBuffer[BDM[Double]]()
nn_p += BDM.zeros[Double](1,1)
for (i <-1 ton - 1) {
vald1 = BDM.zeros[Double](1, size(i))
nn_p += d1
}
nn_p.toArray
}
(6) AddNoise
样本数据增加随机噪声
/**
* 增加随机噪声
* 若随机值>=Fraction,值不变,否则改为0
*/
def AddNoise(rdd: RDD[(BDM[Double], BDM[Double])], Fraction: Double): RDD[(BDM[Double], BDM[Double])] = {
valaddNoise = rdd.map { f =>
valfeatures = f._2
vala = BDM.rand[Double](features.rows,features.cols)
vala1 =a :>= Fraction
vald1 =a1.data.map { f =>if (f ==true)1.0else0.0 }
vala2 =new BDM(features.rows,features.cols,d1)
valfeatures2 =features :*a2
(f._1, features2)
}
addNoise
}
(7) DropoutWeight
神经网络权重随机休眠。
/**
* 随机让网络某些隐含层节点的权重不工作
* 若随机值>=Fraction,矩阵值不变,否则改为0
*/
def DropoutWeight(matrix: BDM[Double], Fraction: Double): Array[BDM[Double]] = {
valaa = BDM.rand[Double](matrix.rows, matrix.cols)
valaa1 =aa :> Fraction
vald1 =aa1.data.map { f =>if (f ==true)1.0else0.0 }
valaa2 =new BDM(matrix.rows: Int, matrix.cols: Int,d1: Array[Double])
valmatrix2 = matrix :*aa2
Array(aa2, matrix2)
}
(8) NNff
神经网络进行前向传播,从输入层->隐含层->输出层,计算每一层每一个节点的输出值,其中输入值为样本数据。输入参数:
batch_xy2:样本数据
bc_config:神经网络配置参数
bc_nn_W:神经网络当前权重参数
输出参数:
RDD[(NNLabel, Array[BDM[Double]])],格式为(NNLabel(label, nn_a, error), dropOutMask)。
/**
* nnff是进行前向传播
* 计算神经网络中的每个节点的输出值;
*/
def NNff(
batch_xy2: RDD[(BDM[Double], BDM[Double])],
bc_config: org.apache.spark.broadcast.Broadcast[NNConfig],
bc_nn_W: org.apache.spark.broadcast.Broadcast[Array[BDM[Double]]]): RDD[(NNLabel, Array[BDM[Double]])] = {
// 第1层:a(1)=[1 x]
// 增加偏置项b
valtrain_data1 = batch_xy2.map { f =>
vallable = f._1
valfeatures = f._2
valnna = ArrayBuffer[BDM[Double]]()
valBm1 =new BDM(features.rows,1, Array.fill(features.rows *1)(1.0))
valfeatures2 = BDM.horzcat(Bm1,features)
valerror = BDM.zeros[Double](lable.rows,lable.cols)
nna += features2
NNLabel(lable, nna, error)
}
valtrain_data2 =train_data1.map { f =>
valnn_a = f.nna
valdropOutMask = ArrayBuffer[BDM[Double]]()
dropOutMask += new BDM[Double](1,1, Array(0.0))
for (j <-1 to bc_config.value.layer -2) {
// 计算每层输出
// Calculate the unit's outputs (including the bias term)
// nn.a{i} = sigm(nn.a{i - 1} * nn.W{i - 1}')
// nn.a{i} = tanh_opt(nn.a{i - 1} * nn.W{i - 1}');
valA1 =nn_a(j -1)
valW1 = bc_nn_W.value(j -1)
valaw1 =A1 *W1.t
valnnai1 = bc_config.value.activation_functionmatch {
case"sigm" =>
valaw2 = NeuralNet.sigm(aw1)
aw2
case"tanh_opt" =>
valaw2 = NeuralNet.tanh_opt(aw1)
//val aw2 = Btanh(aw1 * (2.0 / 3.0)) * 1.7159
aw2
}
// dropout计算
// Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分
// 但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
// 参照 http://www.cnblogs.com/tornadomeet/p/3258122.html
valdropoutai =if (bc_config.value.dropoutFraction >0) {
if (bc_config.value.testing ==1) {
valnnai2 =nnai1 * (1.0 - bc_config.value.dropoutFraction)
Array(new BDM[Double](1,1, Array(0.0)),nnai2)
} else {
NeuralNet.DropoutWeight(nnai1, bc_config.value.dropoutFraction)
}
} else {
valnnai2 =nnai1
Array(new BDM[Double](1,1, Array(0.0)),nnai2)
}
valnnai2 =dropoutai(1)
dropOutMask += dropoutai(0)
// Add the bias term
// 增加偏置项b
// nn.a{i} = [ones(m,1) nn.a{i}];
valBm1 = BDM.ones[Double](nnai2.rows,1)
valnnai3 = BDM.horzcat(Bm1,nnai2)
nn_a += nnai3
}
(NNLabel(f.label, nn_a, f.error),dropOutMask.toArray)
}
// 输出层计算
valtrain_data3 =train_data2.map { f =>
valnn_a = f._1.nna
// nn.a{n} = sigm(nn.a{n - 1} * nn.W{n - 1}');
// nn.a{n} = nn.a{n - 1} * nn.W{n - 1}';
valAn1 =nn_a(bc_config.value.layer -2)
valWn1 = bc_nn_W.value(bc_config.value.layer -2)
valawn1 =An1 *Wn1.t
valnnan1 = bc_config.value.output_functionmatch {
case"sigm" =>
valawn2 = NeuralNet.sigm(awn1)
//val awn2 = 1.0 / (Bexp(awn1 * (-1.0)) + 1.0)
awn2
case"linear" =>
valawn2 =awn1
awn2
}
nn_a += nnan1
(NNLabel(f._1.label,nn_a, f._1.error), f._2)
}
// error and loss
// 输出误差计算
// nn.e = y - nn.a{n};
// val nn_e = batch_y - nnan
valtrain_data4 =train_data3.map { f =>
valbatch_y = f._1.label
valnnan = f._1.nna(bc_config.value.layer - 1)
valerror = (batch_y -nnan)
(NNLabel(f._1.label, f._1.nna,error), f._2)
}
train_data4
}
(9) ActiveP
通过神经网络进行前向传播,计算每一层每一个节点的输出值,计算每个节点的平均值,也即节点的稀疏度。输入参数:
train_nnff:NNff的输出数据
bc_config:神经网络配置参数
nn_p_old:更新前数据
输出参数:
Array[BDM[Double]],输出节点的平均值。
/**
* sparsity计算,网络稀疏度
* 计算每个节点的平均值
*/
def ActiveP(
train_nnff: RDD[(NNLabel, Array[BDM[Double]])],
bc_config: org.apache.spark.broadcast.Broadcast[NNConfig],
nn_p_old: Array[BDM[Double]]): Array[BDM[Double]] = {
valnn_p = ArrayBuffer[BDM[Double]]()
nn_p += BDM.zeros[Double](1,1)
// calculate running exponential activations for use with sparsity
// sparsity计算,计算sparsity,nonSparsityPenalty是对没达到sparsitytarget的参数的惩罚系数
for (i <-1 to bc_config.value.layer -1) {
valpi1 = train_nnff.map(f => f._1.nna(i))
valinitpi = BDM.zeros[Double](1, bc_config.value.size(i))
val (piSum,miniBatchSize) =pi1.treeAggregate((initpi,0L))(
seqOp = (c, v) => {
// c: (nnasum, count), v: (nna)
valnna1 = c._1
valnna2 = v
valnnasum =nna1 +nna2
(nnasum, c._2 +1)
},
combOp = (c1, c2) => {
// c: (nnasum, count)
valnna1 = c1._1
valnna2 = c2._1
valnnasum =nna1 +nna2
(nnasum, c1._2 + c2._2)
})
valpiAvg =piSum /miniBatchSize.toDouble
valoldpi = nn_p_old(i)
valnewpi = (piAvg *0.01) + (oldpi *0.09)
nn_p += newpi
}
nn_p.toArray
}
(10) NNbp
神经网络进行后向传播,输出层->隐含层->输入层,计算每个节点的偏导数,也即误差反向传播。输入参数:
train_nnff:NNff输出值
bc_config:神经网络配置参数
bc_nn_W:神经网络当前权重参数
bc_nn_p:节点稀疏度
输出参数:
Array[BDM[Double]],每层节点的偏导数。
/**
* NNbp是后向传播
* 计算权重的平均偏导数
*/
def NNbp(
train_nnff: RDD[(NNLabel, Array[BDM[Double]])],
bc_config: org.apache.spark.broadcast.Broadcast[NNConfig],
bc_nn_W: org.apache.spark.broadcast.Broadcast[Array[BDM[Double]]],
bc_nn_p: org.apache.spark.broadcast.Broadcast[Array[BDM[Double]]]): Array[BDM[Double]] = {
// 第n层偏导数:d(n)=-(y-a(n))*f'(z),sigmoid函数f'(z)表达式:f'(z)=f(z)*[1-f(z)]
// sigm: d{n} = - nn.e .* (nn.a{n} .* (1 - nn.a{n}));
// {'softmax','linear'}: d{n} = - nn.e;
valtrain_data5 = train_nnff.map { f =>
valnn_a = f._1.nna
valerror = f._1.error
valdn = ArrayBuffer[BDM[Double]]()
valnndn = bc_config.value.output_functionmatch {
case"sigm" =>
valfz =nn_a(bc_config.value.layer -1)
(error * (-1.0)) :* (fz :* (1.0 - fz))
case"linear" =>
error * (-1.0)
}
dn += nndn
(f._1, f._2,dn)
}
// 第n-1至第2层导数:d(n)=-(w(n)*d(n+1))*f'(z)
valtrain_data6 =train_data5.map { f =>
// 假设 f(z)是sigmoid函数 f(z)=1/[1+e^(-z)],f'(z)表达式,f'(z)=f(z)*[1-f(z)]
// 假设 f(z) tanh f(z)=1.7159*tanh(2/3.*A),f'(z)表达式,f'(z)=1.7159 * 2/3 * (1 - 1/(1.7159)^2 * f(z).^2)
valnn_a = f._1.nna
valdi = f._3
valdropout = f._2
for (i <-bc_config.value.layer -2 to 1) {
// f'(z)表达式
valnnd_act = bc_config.value.activation_functionmatch {
case"sigm" =>
vald_act =nn_a(i) :* (1.0 - nn_a(i))
d_act
case"tanh_opt" =>
valfz2 = (1.0 - ((nn_a(i) :* nn_a(i)) * (1.0 / (1.7159 *1.7159))))
vald_act =fz2 * (1.7159 * (2.0 /3.0))
d_act
}
// 稀疏度惩罚误差计算:-(t/p)+(1-t)/(1-p)
// sparsityError = [zeros(size(nn.a{i},1),1) nn.nonSparsityPenalty * (-nn.sparsityTarget ./ pi + (1 - nn.sparsityTarget) ./ (1 - pi))];
valsparsityError =if (bc_config.value.nonSparsityPenalty >0) {
valnn_pi1 = bc_nn_p.value(i)
valnn_pi2 = (bc_config.value.sparsityTarget /nn_pi1) * (-1.0) + (1.0 - bc_config.value.sparsityTarget) / (1.0 -nn_pi1)
valBm1 =new BDM(nn_pi2.rows,1, Array.fill(nn_pi2.rows *1)(1.0))
valsparsity = BDM.horzcat(Bm1,nn_pi2 * bc_config.value.nonSparsityPenalty)
sparsity
} else {
valnn_pi1 = bc_nn_p.value(i)
valsparsity = BDM.zeros[Double](nn_pi1.rows,nn_pi1.cols +1)
sparsity
}
// 导数:d(n)=-( w(n)*d(n+1)+ sparsityError )*f'(z)
// d{i} = (d{i + 1} * nn.W{i} + sparsityError) .* d_act;
valW1 = bc_nn_W.value(i)
valnndi1 =if (i +1 == bc_config.value.layer -1) {
//in this case in d{n} there is not the bias term to be removed
valdi1 =di(i -1)
valdi2 = (di1 *W1 + sparsityError) :*nnd_act
di2
} else {
// in this case in d{i} the bias term has to be removed
valdi1 =di(i -1)(::,1 to -1)
valdi2 = (di1 *W1 + sparsityError) :*nnd_act
di2
}
// dropoutFraction
valnndi2 =if (bc_config.value.dropoutFraction >0) {
valdropouti1 =dropout(i)
valBm1 =new BDM(nndi1.rows: Int,1: Int, Array.fill(nndi1.rows *1)(1.0))
valdropouti2 = BDM.horzcat(Bm1,dropouti1)
nndi1 :* dropouti2
} elsenndi1
di += nndi2
}
di += BDM.zeros(1,1)
// 计算最终需要的偏导数值:dw(n)=(1/m)∑d(n+1)*a(n)
// nn.dW{i} = (d{i + 1}' * nn.a{i}) / size(d{i + 1}, 1);
valdw = ArrayBuffer[BDM[Double]]()
for (i <-0 to bc_config.value.layer -2) {
valnndW =if (i +1 == bc_config.value.layer -1) {
(di(bc_config.value.layer -2 -i).t) *nn_a(i)
} else {
(di(bc_config.value.layer -2 -i)(::,1 to -1)).t *nn_a(i)
}
dw += nndW
}
(f._1, di,dw)
}
valtrain_data7 =train_data6.map(f => f._3)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
valinitgrad = ArrayBuffer[BDM[Double]]()
for (i <-0 to bc_config.value.layer -2) {
valinit1 =if (i +1 == bc_config.value.layer -1) {
BDM.zeros[Double](bc_config.value.size(i +1), bc_config.value.size(i) +1)
} else {
BDM.zeros[Double](bc_config.value.size(i +1), bc_config.value.size(i) +1)
}
initgrad += init1
}
val (gradientSum,miniBatchSize) =train_data7.treeAggregate((initgrad,0L))(
seqOp = (c, v) => {
// c: (grad, count), v: (grad)
valgrad1 = c._1
valgrad2 = v
valsumgrad = ArrayBuffer[BDM[Double]]()
for (i <-0 to bc_config.value.layer -2) {
valBm1 =grad1(i)
valBm2 =grad2(i)
valBmsum =Bm1 +Bm2
sumgrad += Bmsum
}
(sumgrad, c._2 +1)
},
combOp = (c1, c2) => {
// c: (grad, count)
valgrad1 = c1._1
valgrad2 = c2._1
valsumgrad = ArrayBuffer[BDM[Double]]()
for (i <-0 to bc_config.value.layer -2) {
valBm1 =grad1(i)
valBm2 =grad2(i)
valBmsum =Bm1 +Bm2
sumgrad += Bmsum
}
(sumgrad, c1._2 + c2._2)
})
// 求平均值
valgradientAvg = ArrayBuffer[BDM[Double]]()
for (i <-0 to bc_config.value.layer -2) {
valBm1 =gradientSum(i)
valBmavg =Bm1 :/miniBatchSize.toDouble
gradientAvg += Bmavg
}
gradientAvg.toArray
}
(11) NNapplygrads
根据神经网络进行后向传播,计算得出的偏导数,进行权重的更新。输入参数:
train_nnbp:NNbp输出值
bc_config:神经网络配置参数
bc_nn_W:神经网络当前权重参数
bc_nn_vW:神经网络当前vW权重参数
输出参数:
Array[Array[BDM[Double]]],更新后权重。
/**
* NNapplygrads是权重更新
* 权重更新
*/
def NNapplygrads(
train_nnbp: Array[BDM[Double]],
bc_config: org.apache.spark.broadcast.Broadcast[NNConfig],
bc_nn_W: org.apache.spark.broadcast.Broadcast[Array[BDM[Double]]],
bc_nn_vW: org.apache.spark.broadcast.Broadcast[Array[BDM[Double]]]): Array[Array[BDM[Double]]] = {
// nn = nnapplygrads(nn) returns an neural network structure with updated
// weights and biases
// 更新权重参数:w=w-α*[dw + λw]
valW_a = ArrayBuffer[BDM[Double]]()
valvW_a = ArrayBuffer[BDM[Double]]()
for (i <-0 to bc_config.value.layer -2) {
valnndwi =if (bc_config.value.weightPenaltyL2 >0) {
valdwi = train_nnbp(i)
valzeros = BDM.zeros[Double](dwi.rows,1)
vall2 = BDM.horzcat(zeros,dwi(::,1 to -1))
valdwi2 =dwi + (l2 * bc_config.value.weightPenaltyL2)
dwi2
} else {
valdwi = train_nnbp(i)
dwi
}
valnndwi2 =nndwi :* bc_config.value.learningRate
valnndwi3 =if (bc_config.value.momentum >0) {
valvwi = bc_nn_vW.value(i)
valdw3 =nndwi2 + (vwi * bc_config.value.momentum)
dw3
} else {
nndwi2
}
// nn.W{i} = nn.W{i} - dW;
W_a += (bc_nn_W.value(i) -nndwi3)
// nn.vW{i} = nn.momentum*nn.vW{i} + dW;
valnnvwi1 =if (bc_config.value.momentum >0) {
valvwi = bc_nn_vW.value(i)
valvw3 =nndwi2 + (vwi * bc_config.value.momentum)
vw3
} else {
bc_nn_vW.value(i)
}
vW_a += nnvwi1
}
Array(W_a.toArray, vW_a.toArray)
}
(12) NNeval
对样本进行前向传播计算输出层,并计算误差。
/**
* nneval是进行前向传播并计算输出误差
* 计算神经网络中的每个节点的输出值,并计算平均误差;
*/
def NNeval(
batch_xy: RDD[(BDM[Double], BDM[Double])],
bc_config: org.apache.spark.broadcast.Broadcast[NNConfig],
bc_nn_W: org.apache.spark.broadcast.Broadcast[Array[BDM[Double]]]): Double = {
// NNff是进行前向传播
// nn = nnff(nn, batch_x, batch_y);
valtrain_nnff = NeuralNet.NNff(batch_xy, bc_config, bc_nn_W)
// error and loss
// 输出误差计算
valloss1 =train_nnff.map(f => f._1.error)
val (loss2,counte) =loss1.treeAggregate((0.0,0L))(
seqOp = (c, v) => {
// c: (e, count), v: (m)
vale1 = c._1
vale2 = (v :* v).sum
valesum =e1 +e2
(esum, c._2 +1)
},
combOp = (c1, c2) => {
// c: (e, count)
vale1 = c1._1
vale2 = c2._1
valesum =e1 +e2
(esum, c1._2 + c2._2)
})
valLoss =loss2 /counte.toDouble
Loss * 0.5
}
(13) Nntrain
神经网络运行,训练参数。
/**
* 运行神经网络算法.
*/
def NNtrain(train_d: RDD[(BDM[Double], BDM[Double])], opts: Array[Double]): NeuralNetModel = {
valsc = train_d.sparkContext
varinitStartTime = System.currentTimeMillis()
varinitEndTime = System.currentTimeMillis()
// 参数配置广播配置
varnnconfig = NNConfig(size,layer,activation_function,learningRate,momentum,scaling_learningRate,
weightPenaltyL2, nonSparsityPenalty, sparsityTarget, inputZeroMaskedFraction,dropoutFraction,testing,
output_function)
// 初始化权重
varnn_W = NeuralNet.InitialWeight(size)
varnn_vW = NeuralNet.InitialWeightV(size)
// 初始化每层的平均激活度nn.p
// average activations (for use with sparsity)
varnn_p = NeuralNet.InitialActiveP(size)
// 样本数据划分:训练数据、交叉检验数据
valvalidation = opts(2)
valsplitW1 = Array(1.0 -validation,validation)
valtrain_split1 = train_d.randomSplit(splitW1, System.nanoTime())
valtrain_t =train_split1(0)
valtrain_v =train_split1(1)
// m:训练样本的数量
valm =train_t.count
// batchsize是做batch gradient时候的大小
// 计算batch的数量
valbatchsize = opts(0).toInt
valnumepochs = opts(1).toInt
valnumbatches = (m /batchsize).toInt
varL = Array.fill(numepochs *numbatches.toInt)(0.0)
varn =0
varloss_train_e = Array.fill(numepochs)(0.0)
varloss_val_e = Array.fill(numepochs)(0.0)
// numepochs是循环的次数
for (i <-1 tonumepochs) {
initStartTime = System.currentTimeMillis()
valsplitW2 = Array.fill(numbatches)(1.0 / numbatches)
// 根据分组权重,随机划分每组样本数据
valbc_config =sc.broadcast(nnconfig)
for (l <-1 tonumbatches) {
// 权重
valbc_nn_W =sc.broadcast(nn_W)
valbc_nn_vW =sc.broadcast(nn_vW)
// 样本划分
valtrain_split2 =train_t.randomSplit(splitW2, System.nanoTime())
valbatch_xy1 =train_split2(l -1)
// val train_split3 = train_t.filter { f => (f._1 >=batchsize * (l - 1) + 1) && (f._1 <=batchsize * (l)) }
// val batch_xy1 = train_split3.map(f => (f._2, f._3))
// Add noise to input (for use in denoising autoencoder)
// 加入noise,这是denoisingautoencoder需要使用到的部分
// 这部分请参见《Extracting and Composing Robust Features withDenoising Autoencoders》这篇论文
// 具体加入的方法就是把训练样例中的一些数据调整变为0,inputZeroMaskedFraction表示了调整的比例
//val randNoise = NeuralNet.RandMatrix(batch_x.numRows.toInt, batch_x.numCols.toInt, inputZeroMaskedFraction)
valbatch_xy2 =if (bc_config.value.inputZeroMaskedFraction != 0) {
NeuralNet.AddNoise(batch_xy1,bc_config.value.inputZeroMaskedFraction)
} elsebatch_xy1
// NNff是进行前向传播
// nn = nnff(nn, batch_x, batch_y);
valtrain_nnff = NeuralNet.NNff(batch_xy2,bc_config,bc_nn_W)
// sparsity计算,计算每层节点的平均稀疏度
nn_p = NeuralNet.ActiveP(train_nnff,bc_config,nn_p)
valbc_nn_p =sc.broadcast(nn_p)
// NNbp是后向传播
// nn = nnbp(nn);
valtrain_nnbp = NeuralNet.NNbp(train_nnff,bc_config,bc_nn_W,bc_nn_p)
// nn = NNapplygrads(nn) returns an neural network structure with updated
// weights and biases
// 更新权重参数:w=w-α*[dw + λw]
valtrain_nnapplygrads = NeuralNet.NNapplygrads(train_nnbp,bc_config,bc_nn_W,bc_nn_vW)
nn_W = train_nnapplygrads(0)
nn_vW = train_nnapplygrads(1)
// error and loss
// 输出误差计算
valloss1 =train_nnff.map(f => f._1.error)
val (loss2,counte) =loss1.treeAggregate((0.0,0L))(
seqOp = (c, v) => {
// c: (e, count), v: (m)
vale1 = c._1
vale2 = (v :* v).sum
valesum =e1 + e2
(esum, c._2 +1)
},
combOp = (c1, c2) => {
// c: (e, count)
vale1 = c1._1
vale2 = c2._1
valesum =e1 + e2
(esum, c1._2 + c2._2)
})
valLoss =loss2 /counte.toDouble
L(n) =Loss *0.5
n = n +1
}
// 计算本次迭代的训练误差及交叉检验误差
// Full-batch train mse
valevalconfig = NNConfig(size,layer,activation_function,learningRate,momentum,scaling_learningRate,
weightPenaltyL2, nonSparsityPenalty, sparsityTarget, inputZeroMaskedFraction,dropoutFraction,1.0,
output_function)
loss_train_e(i -1) = NeuralNet.NNeval(train_t,sc.broadcast(evalconfig),sc.broadcast(nn_W))
if (validation >0)loss_val_e(i -1) = NeuralNet.NNeval(train_v,sc.broadcast(evalconfig),sc.broadcast(nn_W))
// 更新学习因子
// nn.learningRate = nn.learningRate * nn.scaling_learningRate;
nnconfig = NNConfig(size,layer,activation_function,nnconfig.learningRate *nnconfig.scaling_learningRate,momentum,scaling_learningRate,
weightPenaltyL2, nonSparsityPenalty, sparsityTarget, inputZeroMaskedFraction,dropoutFraction,testing,
output_function)
initEndTime = System.currentTimeMillis()
// 打印输出结果
printf("epoch: numepochs = %d , Took = %d seconds; Full-batch train mse = %f, val mse = %f.\n",i, scala.math.ceil((initEndTime -initStartTime).toDouble /1000).toLong,loss_train_e(i -1), loss_val_e(i -1))
}
valconfigok = NNConfig(size,layer,activation_function,learningRate,momentum,scaling_learningRate,
weightPenaltyL2, nonSparsityPenalty, sparsityTarget, inputZeroMaskedFraction,dropoutFraction,1.0,
output_function)
new NeuralNetModel(configok,nn_W)
}
2.2.4 NeuralNetModel解析
(1) PredictNNLabel
PredictNNLabel:自定义数据类型,存储样本预测数据,格式:实际值,预测值,误差。
/**
* label:目标矩阵
* features:特征矩阵
* predict_label:预测矩阵
* error:误差
*/
caseclass PredictNNLabel(label: BDM[Double], features: BDM[Double],predict_label: BDM[Double],error: BDM[Double])extends Serializable
(2) predict
对样本数据进行预测。
/**
* 返回预测结果
* 返回格式:(label, feature, predict_label, error)
*/
def predict(dataMatrix: RDD[(BDM[Double], BDM[Double])]): RDD[PredictNNLabel] = {
valsc = dataMatrix.sparkContext
valbc_nn_W =sc.broadcast(weights)
valbc_config =sc.broadcast(config)
// NNff是进行前向传播
// nn = nnff(nn, batch_x, batch_y);
valtrain_nnff = NeuralNet.NNff(dataMatrix,bc_config,bc_nn_W)
valpredict =train_nnff.map { f =>
vallabel = f._1.label
valerror = f._1.error
valnnan = f._1.nna(bc_config.value.layer - 1)
valnna1 = f._1.nna(0)(::,1 to -1)
PredictNNLabel(label,nna1,nnan,error)
}
predict
}
(2) Loss
对预测数据计算误差。
/**
* 计算输出误差
* 平均误差;
*/
def Loss(predict: RDD[PredictNNLabel]): Double = {
valpredict1 = predict.map(f => f.error)
// error and loss
// 输出误差计算
valloss1 =predict1
val (loss2,counte) =loss1.treeAggregate((0.0,0L))(
seqOp = (c, v) => {
// c: (e, count), v: (m)
vale1 = c._1
vale2 = (v :* v).sum
valesum =e1 +e2
(esum, c._2 +1)
},
combOp = (c1, c2) => {
// c: (e, count)
vale1 = c1._1
vale2 = c2._1
valesum =e1 +e2
(esum, c1._2 + c2._2)
})
valLoss =loss2 /counte.toDouble
Loss * 0.5
}
转载请注明出处:
http://blog.csdn.net/sunbow0