Fiddler服务器数据抓包
1.为什么是Fiddler?
抓包工具有很多,小到最常用的web调试工具firebug,达到通用的强大的抓包工具wireshark.为什么使用fiddler?原因如下:
a.Firebug虽然可以抓包,但是对于分析http请求的详细信息,不够强大。模拟http请求的功能也不够,且firebug常常是需要“无刷新修改”,如果刷新了页面,所有的修改都不会保存。
b.Wireshark是通用的抓包工具,但是比较庞大,对于只需要抓取http请求的应用来说,似乎有些大材小用。
c.Httpwatch也是比较常用的http抓包工具,但是只支持IE和firefox浏览器(其他浏览器可能会有相应的插件),对于想要调试chrome浏览器的http请求,似乎稍显无力,而Fiddler2 是一个使用本地 127.0.0.1:8888 的 HTTP 代理,任何能够设置 HTTP 代理为 127.0.0.1:8888 的浏览器和应用程序都可以使用 Fiddler。
2.什么是Fiddler?
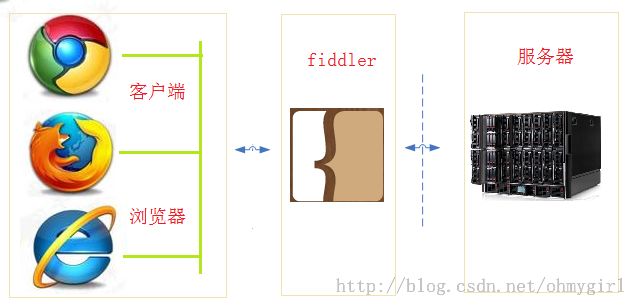
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
既然是代理,也就是说:客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。使用了Fiddler之后,web客户端和服务器的请求如下所示:
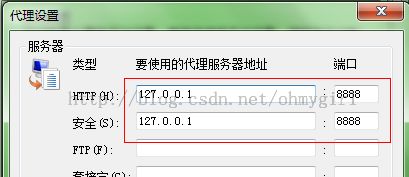
Fiddler 作为系统代理,当启用 Fiddler 时,IE 的PROXY 设定会变成 127.0.0.1:8888,因此如果你的浏览器在开启fiddler之后没有设置相应的代理,则fiddler是无法捕获到HTTP请求的。如下是启动Fiddler之后,IE浏览器的代理设置:
以Firefox为例,默认情况下,firefox是没有启用代理的(如果你安装了proxy等代理工具或插件,是另外一种情况),在firefox中配置http代理的步骤如下:
工具->选项->高级->网络->设置 。并配置相应的代理如下:

就可以使用Fiddler抓取Firefox的HTTP请求了。
3.Fiddler使用界面简介
Fiddler主界面的布局如下:
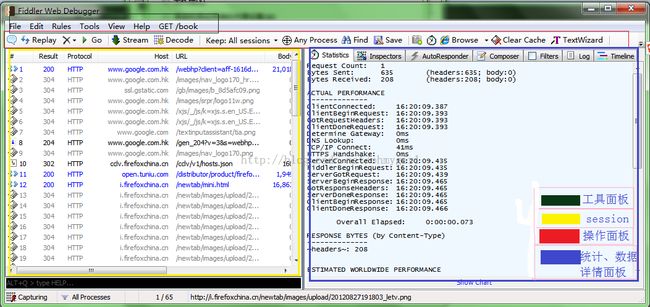
主界面中主要包括四个常用的块:
1.Fiddler的菜单栏,上图绿色部分。包括捕获http请求,停止捕获请求,保存http请求,载入本地session、设置捕获规则等功能。
2.Fiddler的工具栏,上图红色部分。包括Fiddler针对当前view的操作(暂停,清除session,decode模式、清除缓存等)。
3.web Session面板,上图黄色区域,主要是Fiddler抓取到的每条http请求(每一条称为一个session),主要包含了请求的url,协议,状态码,body等信息,详细的字段含义如下图所示:

4.详情和数据统计面板。针对每条http请求的具体统计(例如发送/接受字节数,发送/接收时间,还有粗略统计世界各地访问该服务器所花费的时间)和数据包分析。如inspector面板下,提供headers、textview、hexview,Raw等多种方式查看单条http请求的请求报文的信息:

而composer面板下,则可以模拟向相应的服务器发送数据的过程(不错,这就是灌水机器人的基本原理,也可以是部分http flood的一种方式)。
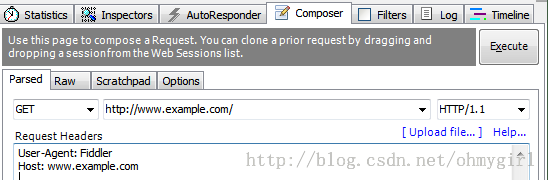
也可以粘贴一次请求的raw http headers,达到模拟请求的目的:

Filter标签则可以设置Fiddler的过滤规则,来达到过滤http请求的目的。最简单如:过滤内网http请求而只抓取internet的http请求,或则过滤相应域名的http请求。Fiddler的过滤器非常强大,可以过滤特定http状态码的请求,可以过滤特定请求类型的http请求(如css请求,image请求,js请求等),可以过滤请求报文大于或则小于指定大小(byte)的请求:
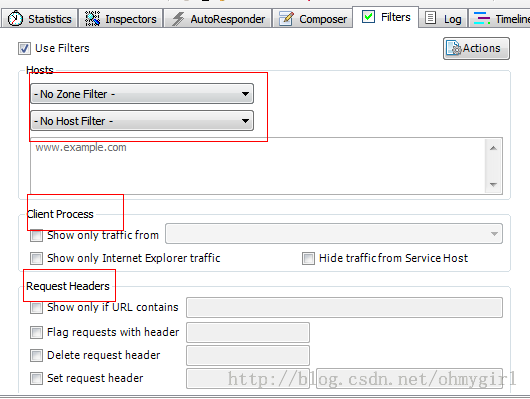
请多的过滤器规则需要一步一步去挖掘。
Fiddler抓取HTTP请求。
抓包是Fiddler的最基本的应用,以本博客为例,启动Fiddler之后,在浏览器中输入http://blog.csdn.net/ohmygirl 键入回车之后,在Fiddler的web session界面捕获到的HTTP请求如下图所示:
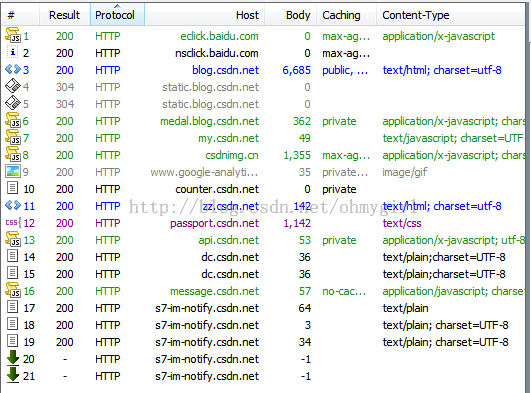
各字段的详细说明已经解释过,这里不再说明。需要注意的是#号列中的图标,每种图标代表不同的相应类型,具体的类型包括:

另外,注意请求的host字段。可以看到有来自多个www.csdn.net的子域名的响应,说明在大型网站的架构中,大多需要多个子域名,这些子域名可能是单独用于缓存静态资源的,也可能是专门负责媒体资源的,或者是专门负责数据统计的(如pingback)。
右键单击其中的一条请求。可以选择的操作有:save(保存请求的报文信息,可以是请求报文,可以是响应报文)。例如,我们保存的一条请求头信息如下:

不仅是单条session,Fiddler还支持保存所有抓取到的session(并支持导入),这对于抓取可疑请求然后保存,并在之后随时分析这些请求是很有帮助的。
如果想要重新发送某些请求,可以选中这些请求,然后点击工具栏中的reply.就可以重新发送选中的这些请求。
左键点击单条HTTP请求,可以在右侧的tab面板中看到如下信息:
1. Statistic。
关于HTTP请求的性能和其他数据分析:
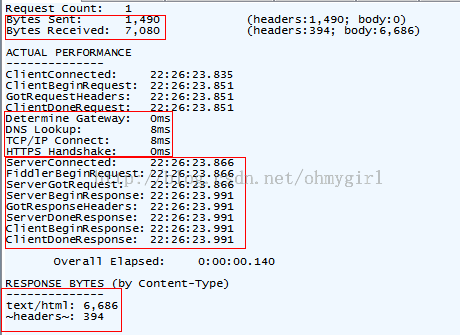
我们可以从中看出一些基本性能数据:如DNS解析的时间消耗是8ms,建立TCP/IP连接的时间消耗是8ms等等信息。
2. Inspectors。
分为上下两个部分,上半部分是请求头部分,下半部分是响应头部分。对于每一部分,提供了多种不同格式查看每个请求和响应的内容。JPG 格式使用 ImageView 就可以看到图片,HTML/JS/CSS 使用 TextView 可以看到响应的内容。Raw标签可以查看原始的符合HTTP标准的请求和响应头。Auth则可以查看授权Proxy-Authorization 和 Authorization的相关信息。Cookies标签可以看到请求的cookie和响应的set-cookie头信息。

3. AutoResponder
Fiddler比较重要且比较强大的功能之一。可用于拦截某一请求,并重定向到本地的资源,或者使用Fiddler的内置响应。可用于调试服务器端代码而无需修改服务器端的代码和配置,因为拦截和重定向后,实际上访问的是本地的文件或者得到的是Fiddler的内置响应。当勾选allow autoresponser 并设置相应的规则后(本例中的规则是将http://blog.csdn.net/ohmygirl的请求拦截到本地的文件layout.html),如下图所示
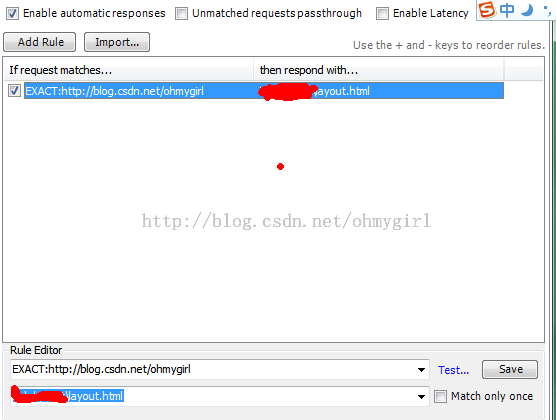
然后在浏览器中访问http://blog.csdn.net/ohmygirl,得到的结果实际为:
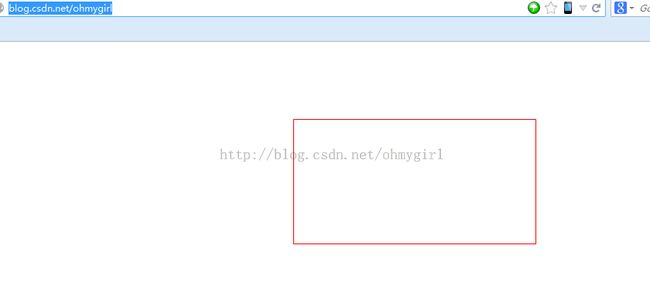
这刚好是本地layout.html的内容,说明请求已经成功被拦截到本地.当然也可以使用Fiddler的内置响应。下图是Fiddler支持的拦截重定向的方式:
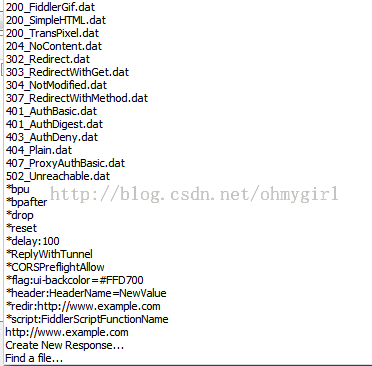
因此,如果要调试服务器的某个脚本文件,可以将该脚本拦截到本地,在本地修改完脚本之后,再修改服务器端的内容,这可以保证,尽量在真实的环境下去调试,从而最大限度的减少bug发生的可能性。
不仅是单个url,Fiddler支持多种url匹配的方式:
I. 字符匹配
如 example可以匹配 http://www.example.com和http://example.com.cn
II. 完全匹配
以EXACT开头表示完全匹配,如上边的例子
EXACT:http://blog.csdn.net/ohmygirl
III. 正则表达式匹配
以regex: 开头,使用正则表达式来匹配URL
如:regex:(?insx).*\.(css|js|php)$ 表示匹配所有以css,js,php结尾的请求url
4. Composer。
老版本的fiddler中叫request-builder.顾名思义,可以构建相应的请求,有两种常用的方式构建请求:
(1)Parsed 输入请求的url之后executed即可,也可以修改相应的头信息(如添加常用的accept, host, referrer, cookie,cache-control等头部)后execute.
这个功能的常见应用是:“刷票”(不是火车票!!),如刷新页面的访问量(基于道德和安全原因,如果你真去刷票,刷访问量,本博客概不负责)
(2)Raw。使用HTTP头部信息构建http请求。与上类似。不多叙述
5. Filter
Fiddler另一个比较强大的功能。Fiddler提供了多维度的过滤规则,足以满足日常开发调试的需求。如下图示:
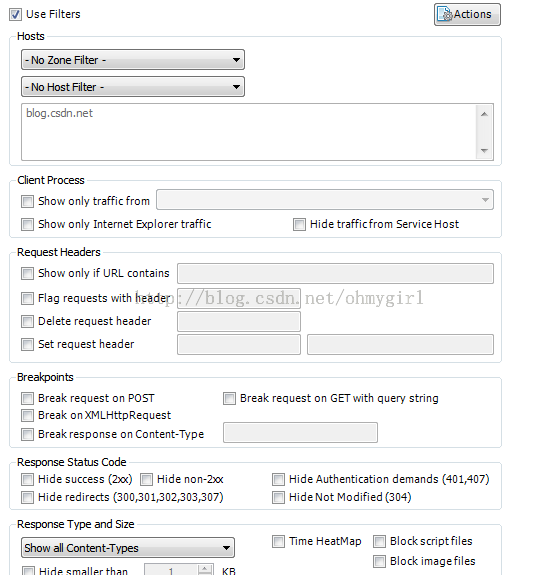
过滤规则有:
a. host和zone过滤。可以过滤只显示intranet或则internet的HTTP请求
也可以选择特定域名的HTTP请求
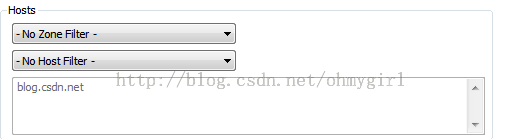
b. client process:可以捕获指定进程的请求。
这对于调试单个应用的请求很有帮助。
其他更多的设置可以参考fiddler的官方文档。
一. Fiddler内置命令。
上一节(使用Fiddler进行抓包分析)中,介绍到,在web session(与我们通常所说的session不是同一个概念,这里的每条HTTP请求都成为一个session)界面中可以看到Fiddler抓取的所有HTTP请求.而为了更加方便的管理所有的session, Fiddler提供了一系列内置的函数用于筛选和操作这些session(习惯命令行操作linux的童鞋应该可以感受到这会有多么方便).输入命令的位置在web session管理面板的下方(通过快捷键alt+q可以focus到命令行).
Fiddler内置的命令有如下几种:
1. select命令。
选择所有相应类型(指content-type)为指定类型的HTTP请求,如选择图片,使用命令select image.而select css则可以选择所有相应类型为css的请求,select html则选择所有响应为HTML的请求(怎么样,是不是跟SQL语句很像?)。如图是执行select image之后的结果:
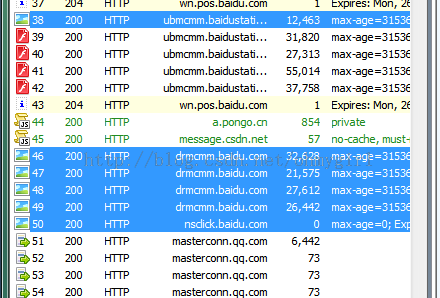
2. allbut命令。
allbut命令用于选择所有响应类型不是给定类型的HTTP请求。如allbut image用于选择所有相应类型不是图片的session(HTTP请求),该命令还有一个别名keeponly.需要注意的是,keeponly和allbut命令是将不是该类型的session删除,留下的都是该类型的响应。因此,如果你执行allbut xxxx(不存在的类型),实际上类似与执行cls命令(删除所有的session, ctrl+x快捷键也是这个作用)
3. ?text命令
选择所有 URL 匹配问号后的字符的全部 session
4. >size 和 <size命令
选择响应大小大于某个大小(单位是b)或者小于某个大小的所有HTTP请求
5. =status命令
选择响应状态等于给定状态的所有HTTP请求。
例如,选择所有状态为200的HTTP请求:=200
6. @host命令
选择包含指定 HOST 的全部 HTTP请求。例如:@csdn.net
选择所有host包含csdn.net的请求
7. Bpafter, Bps, bpv, bpm, bpu
这几个命令主要用于批量设置断点
Bpafter xxx: 中断 URL 包含指定字符的全部 session 响应
Bps xxx: 中断 HTTP 响应状态为指定字符的全部 session 响应。
Bpv xxx: 中断指定请求方式的全部 session 响应
Bpm xxx: 中断指定请求方式的全部 session 响应。等同于bpv xxx
Bpu xxx:与bpafter类似。
当这些命令没有加参数时,会清空所有设置了断点的HTTP请求。
更多的其他命令可以参考Fiddler官网手册。
二. 使用Fiddler进行HTTP断点调试。
这是Fiddler又一强大和实用的工具之一。通过设置断点,Fiddler可以做到:
1. 修改HTTP请求头信息。例如修改请求头的UA, Cookie, Referer 信息,通过“伪造”相应信息达到达到相应的目的(调试,模拟用户真实请求等)。
2. 构造请求数据,突破表单的限制,随意提交数据。避免页面js和表单限制影响相关调试。
3. 拦截响应数据,修改响应实体。
为什么以上方法是重要的?假设js前端程序员和服务器程序员是分工合作的,js程序员想要调试Ajax请求的功能,这样便不必等待服务器端程序员开发好所有接口之后再开始开发js端的ajax请求功能,因为通过“模拟”真实的服务器端的响应,便可以保证功能的正确性,而服务器端开发程序员,只要保证最终的响应是符合规定的即可。这大大简化了程序开发的效率,当然也降低了不同业务线程序员联调的难度。
有两种方法设置断点:
1.fiddler菜单栏->rules->automatic Breakpoints->选择断点方式,这种方式下设定的断点会对之后的所有HTTP请求有效。
有两个断点位置:
a. before response。也就是发送请求之后,但是Fiddler代理中转之前,这时可以修改请求的数据。
b.after response。也就是服务器响应之后,但是在Fiddler将响应中转给客户端之前。这时可以修改响应的结果。
2.命令行下输入。Bpafter xxx或者bpv,bpu,bpm等设置断点。这种断点只针对特定类型的请求。
我们以本地的web项目为例,演示如何简单的设置HTTP断点:
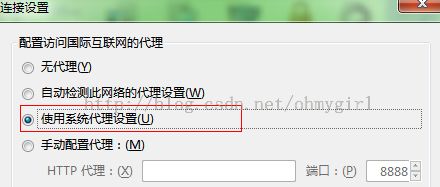
1.首先设置Firefox的代理,使之可以抓取所有的HTTP请求(localhost的请求,也可以在filter中设置只抓取intranet请求),设置如下图所示:
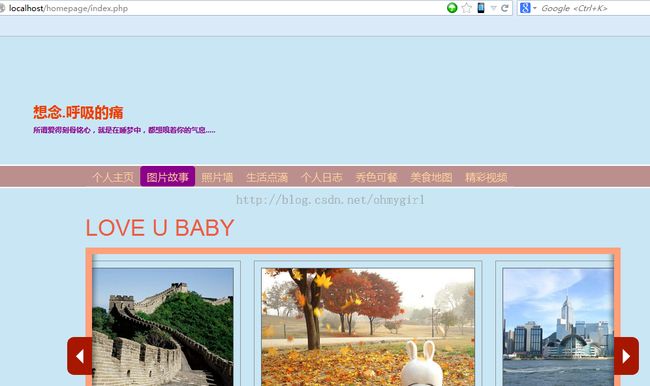
2. 这时用web打开本地的项目。页面的内容为:
4. 设置响应后断点(after response breakpoint),可以通过命令行设置:bpafter localhost。键入回车之后,web再次访问文件,通过Fiddler的web session界面可以看到,请求已经被挂起来了,而web浏览器也一直处于加载的状态。观察右侧的inspector面板下,也出现了新的东西:
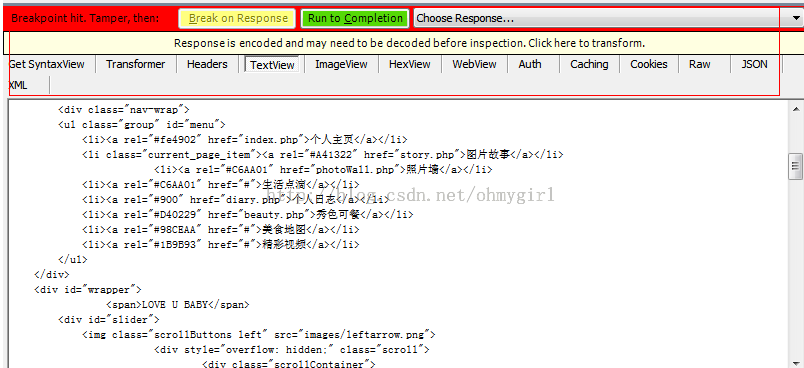
这时我们就可以修改响应的信息了。修改过程为:
切换到textView子面板,选择需要修改的部分,然后点击 “run to complete“,便可回送修改后的响应。假设我们修改后的内容如下:

点击执行后,打开刚刚的web界面。可以看到的页面的变化。

可见,页面的响应已经有了相应的变化。这就是响应后断点。当然实际应用中,断点的设置和响应的修改会比这复杂的多,这里只是基本的示例。
终止断点的方式有:
1. 在inspector界面点击“run complete“即会终止本次HTTP请求的断点。
2. 输入go命令,也会使得当前的请求跳过断点。
3. 在rules->auto breakpoint中disabled断点即可。
总之,Fiddler的断点功能非常强大,关于它的进一步学习和应用,需要一个不断积累和摸索的过程。
转自:http://blog.csdn.net/ohmygirl/article/details/17846199