深入图解字符集与字符集编码(二)——编号 vs 编码(出处:http://my.oschina.net/goldenshaw/blog/305805)
摘要
编号是字符到最终编码的一个过渡层与抽象层,起着承上启下的作用,它与最终编码在形式上也常常很相似,在Unicode中,码点(code point)扮演的正是编号的角色。广义而言,编号其实也是一种编码。
字符集 编码 编号 码点 Unicode
目录[-]
目录[-]
在深入研究字符集编码,简称编码之前,我们先引入一个概念:编号(code),引入它是为了更好地与编码(encode)相区分。
如果你对Unicode有深入了解,你也许已经意识到了Unicode中码点(code point)扮演的正是编号的角色。类似的还有GB系列中所谓的区位码。
其实叫什么并不重要,爱咋咋地,我并不关心。但乱叫容易叫混了,比如把码点也叫成Unicode编码,这里先把这些归入到编号概念。为区别起见,用黑色加粗的编码特指字符集编码。
到了后面你甚至会为字符集编码的边界在哪而困惑,为它的准确定义而纠结,不过到那时你已经属于”难得糊涂“了,编号这一概念你也可以把它丢到爪哇国去了。
这是系列中的第二篇。前一篇见
深入图解字符集与字符集编码(一)——charset vs encoding
编号可以看作是字符与编码中间的一个抽象层,过渡层:
广义上说,编号也可看成是某种编码;
狭义上说,编码也可视作为某种编号。
图:字符<-->编号<-->编码
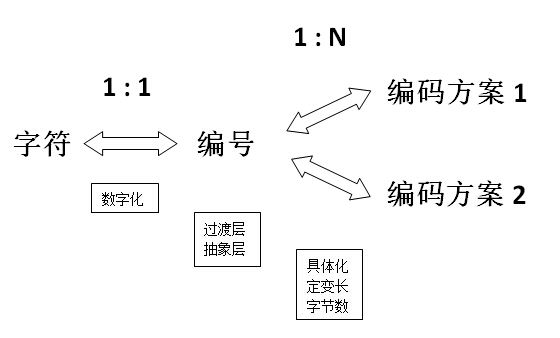
编号与编码的主要区别在于编号不涉及具体使用多少字节来表示、是用定长还是变长方案等细节问题。编号仅仅是一个抽象的概念。
在进一步比较编号与编码之前,我们先看看编号是如何来的。
数学意义上的集合(Set):一组不重复的,无序的的元素。
一般意义上的字符集:不重复的,带编号的有序的的字符集合。
图:数学意义上的字符集对比实际的字符集

字符被整理出来之后往往数量众多,通常是置于表格之中。出于统计方面的原因,人们通常用一个数字来编号。表格本身就是一种有序的暗含了编号的形式,哪怕你没有明确地为其编号,人们拿到这个表格也会说:”嘿,第一个字符是XXX!“这里的一不就是编号吗?
可以把整理的工作视作是由一群完全不懂计算机的语言文字学家来完成的,他们甚至连字节是什么都没听说过。所谓编号是抽象的就是说它仅仅是一个数字而已。
这里不打算去讨论哲学意义上的等同,你可能会碰到有些字符彼此间长得非常像,在有了编号后,我们可以简单地说,只要是编号不同的两个字符就是不重复的。
图:一些很相似的字符,图片来自http://wiki.secondlife.com/wiki/Unicode_In_5_Minutes
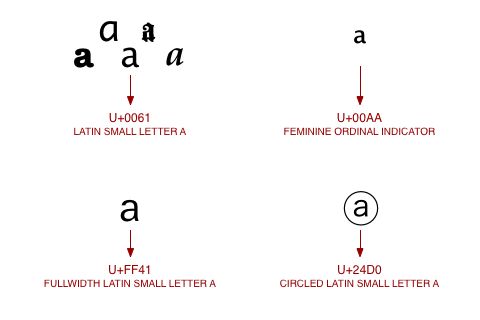
我们可以看到至少有三个码点上的a是非常像的。其中的U+FF41中所谓的FULLWIDTH(全宽)其实就是全角,也即两个半角宽度,我想我们对此都很熟悉。
当初GB2312出来时,仗着自己编码空间大,把ASCII里那些字母符号之类的又重复弄出一套所谓的全角版本来,后来Unicode又把这些又再收罗了过去。
不一定!它可以是数字对,或者你叫它复数,二元数啥的,随便你。但只要它是离散可数量子化的,它自然也可以转换成唯一的一个数字。参见前面图中的二维区位编号,我们用数字对(1, 1)编号“h”这个字符。(1, 1)可以简单转换成11,然后可以进一步映射到从0或者1开始的编号。
有序不意味着连续。这里需要说明的一点是,从前面的叙述来看,编号早于编码,但实际情况是人们通常是一起考虑这两者的,编号反过来会受到编码考虑的影响,这样做只是为了让从编号到编码的映射或者叫转换更加方便。这些影响包括:
如果按日常习惯,编号通常应该从1开始,受编码影响,编号也从0开始。
编号写成十进制是更自然的方式,受编码影响,编号通常也以十六进制形式来书写,并写成固定的位数,不够时就在前面填充0,比如把48写成0048。Unicode的码点位数是4-6位,不够4位的补足4位,超过的是多少位就多少位,比如:U+1D11E就是一个一个五位的编号。
为了以后的扩展方便,编码常常会跳过某些码位,甚至会保留大片的区域未定义或作保留用途。比如Unicode有所谓的代理区(surrogate area),后续我们会进一步了解。编号因此也跳过这些。(其实到了后面你会发现,究竟谁影响谁还真不好说!不过等你明白之时这些已经不重要了。。。)
总之一句话就是让映射规则尽可能简单。
图:编号最终与编码几乎一样的一种可能情形,为简单起见,使用十进制。

你可能会说,那这样它们还有什么区别?你的确可以把编号也说成是编码。
但事情并不总是这样,这种相似性确实迷惑了很多人,特别是Unicode,很多人把码点说成是Unicode编码,这种说法本身并没有错,这取决于你如何定义编码,但他们是否意识码点仅仅一种抽象的编码呢?为了区别,Unicode把最终的具体编码称为UTF(Unicode Transformation Format),即所谓的Unicode转换格式。
所谓转换,其实就是把抽象的数字映射到具体的,最终的编码上来。
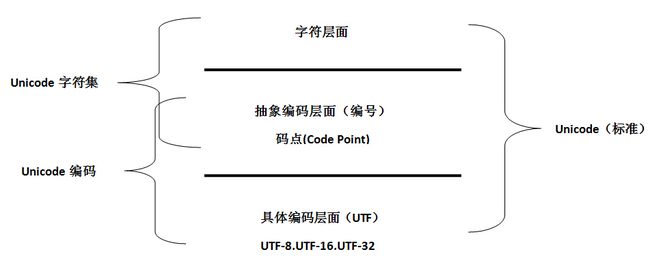
把一个字符编码到一个数字(不涉及每个数字用几个字节表示,是用定长还是变长表示等具体细节)
即UTF,把抽象编码层面的数字编码成最终的存储形式,需要明确是用定长还是变长;定长的话定几个字节;用变长的话有哪几种字节长度,具体如何去实现等等。(注:在上一层面,字符与数字已经实现一一对应,对数字编码实质就是对字符编码)
编码是一个非常宽泛的概念!虽然我们前面一直用编码特指字符集编码,但这只是一种狭义的理解,广义的理解则有很多:
文字是对声音的编码
照相机,摄像机把光信号编码成图像及视频
我们还经常能看到条形码,二维码,这些都是编码
在《编码:隐匿在计算机软硬件背后的语言》(Code: The Hidden Language of Computer Hardware and Software)一书中,参见豆瓣读书http://book.douban.com/subject/4822685/,作者提到了莫尔斯电码(Morse Code)

以及布莱叶盲文(Braille Code),这些都是编码的例子。

在《信息简史》( The Information: A History, A Theory, A Flood)一书中,参见豆瓣读书http://book.douban.com/subject/25752043/,作者提到了一个有趣的“会说话的鼓”的故事,非洲的一些部落成员之间可以用鼓声来交流非常复杂的讯息,在这里就是用鼓声来编码信息。
回到我们的字符集的例子,虽然我们倾向于认为编码就是指最终存储的形式,比如写入文件时或者放在内存时,又或者是在网络传输的过程中。
但如果我们要说,字符集编码这一概念也可以包含抽象层面的编码,那么这样一种说法也并无不妥,只要你能准确区分这两个层面,你怎么去看待它们都是可以的,还是前面那句话,这取决于你如何定义编码,比如我们可以说GBK中的区位码难道不是字符集编码吗?这就取决于你如何看待GBK编码这一概念了,是狭义的去看待还是广义的去看待。
我不想为字符集编码的准确定义去争论,在我看来,当你说编码时,只要你自己清楚说的是哪个层面就ok了,我们在前面引入了编号,目的是为在尚未澄清之前作更好的区分,如果你现在已经清楚了,就可以把编号丢掉了。
事实上,当人们说到Unicode编码时,更常是指它的抽象编码层,即码点这一层面,实际上这才是Unicode的核心所在。
Unicode的核心就是为每个字符提供唯一一个数字编号。Unicode provides a unique number for every character.
让我们来看一个更加具体的示意图:
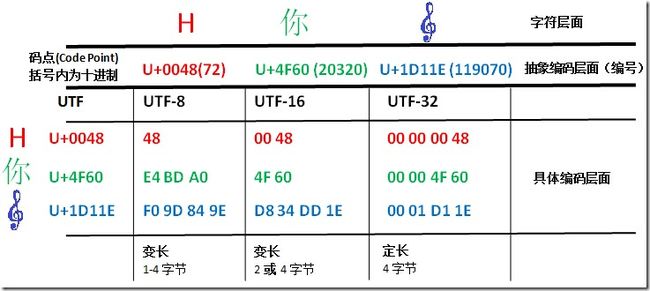
关于码点如何具体转换成各种编码,这个在后面再作讨论。从图上我们可以初步得出一些结论。比如
UTF-8与UTF-16都是变长编码,UTF-32则是定长编码。
码点到UTF-32的转换最简单,就是在前面垫0垫够4字节就行了。
码点到UTF-8的转换,除了最小那个在数值上一样外,其它两个完全看不出两者的关系。
码点到UTF-16的转换则是最微妙的,可以看出前两个字符UTF-16与码点是完全一致的,但那个大码点(准确地说是超过了U+FFFF的码点)则有了很大的变化,长度变成了四字节,值也变得很不一样了。
关于UTF-16的误解是很多的,部分可能由于它的名字上带了个16,让人误以为它是16位定长的两字节编码。但正像UTF-8并不是仅仅是8位一样,UTF-16也不仅仅是16位。
事实上,UTF-16的前身UCS-2确实是16位定长的编码,它跟码点在形式上就是完全一样了,实际我很怀疑那时候压根就没码点这一说法,那时人们甚至也不说UCS-2,直接就叫Unicode!
时至今天,你依然可以在不少地方看到把UTF-16写成Unicode的,然后与UTF-8并排在一起,显得不伦不类的,当然了,这是有历史原因的。
简单地说,字符扩充了,目前码点的范围是U+0000~U+10FFFF(按Unicode官方的说法,就这样了,以后也不扩充了),U+10FFFF是多大呢?大概是111万,而16位定长的话,撑死了也就6万多,所以不变就不行了。
在后面的篇章中,将进一步分析定长,变长的问题,见
深入图解字符集与字符集编码(三)——定长与变长