LibSVM在x64windows下的安装与初次使用
最近在工作时遇到需要利用LibSVM解决分类的问题,于是就从头学起,下面介绍一下安装与初次使用的基本内容。
1、下载libsvm-3.20 (http://www.csie.ntu.edu.tw/~cjlin/libsvm/)解压在任意位置
2、下载gnuplot ,安装在默认路径下:C:\ProgramFiles (x86)\gnuplot
3、1)从python官网上下载windows下的安装包python-2.7.3.msi并安装
2)打开IDLE(python GUI),输入
import sys sys.version
如果你的python是32位,将出现如下字符:
‘2.7.3 (default, Apr 10 2012, 23:31:26)[MSC v.1500 32 bit (Intel)]’
这个时候LIBSVM的python接口设置将非常简单。在libsvm-3.16文件夹下的windows文件夹中找到动态链接库libsvm.dll,将其添加到系统目录,如`C:\WINDOWS\system32\’,即可在python中使用libsvm
3)如果你的python是64位的,也就是说打开IDLE(pythonGUI),输入
import sys sys.version
出现如下字符:
'2.7.3 (default, Apr 10 2012, 23:24:47)[MSC v.1500 64 bit (AMD64)]'
这时你需要首先自己编译64位的动态链接库libsvm.dll。方法如下:
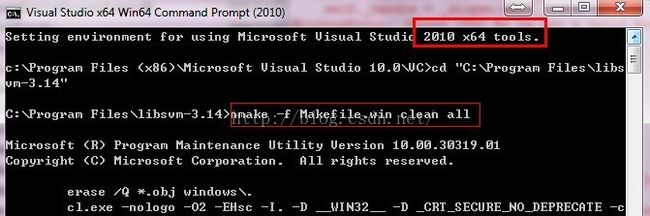
在程序列表中的Microsoft Visual Studio 2010/Visual Studio Tools下找到VisualStudio x64 Win64 Command Prompt(2010),注意一定要是64位的commandprompt
cd到LIBSVM所在文件夹libsvm-3.16
输入nmake -f Makefile.win clean all
这时libsvm-3.16的windows目录下将生成64位的动态链接库。将新生成的libsvm.dll复制到系统目录(例如`C:\WINDOWS\system32\')即可。
4)一个小例子
打开IDLE
import os os.chdir(‘C:\ProgramFiles\libsvm-3.16\python’) from svmutil import * y, x =svm_read_problem(‘../heart_scale’) m = svm_train(y[:200],x[:200], ‘-c 4’) p_label, p_acc, p_val =svm_predict(y[200:], x[200:], m)
自己观察结果。
4、修改..\libsvm-3.20\tools位置里的easy.py 和grid.py脚本文件
4.1修改easy.py文件如下位置代码:
尤其修改gnuplot_exe: 为gnuplot的安装路径
5、这时将heart_scale文件拷进tools文件夹下,现在执行grid.py文件(对C-SVC的参数c和y做优选的,原理就是网格遍历)
cmd命令行下执行:
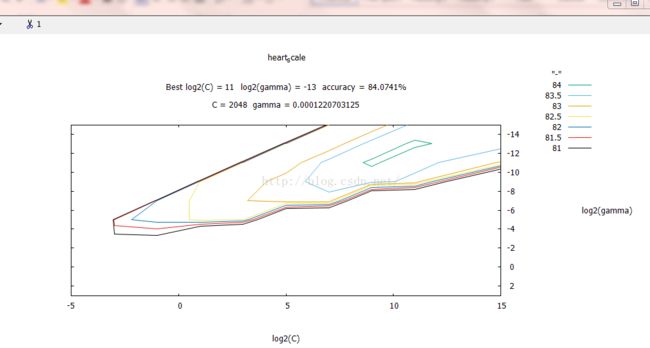
会出现下图,等待:
结束执行,命令行呈现下图:
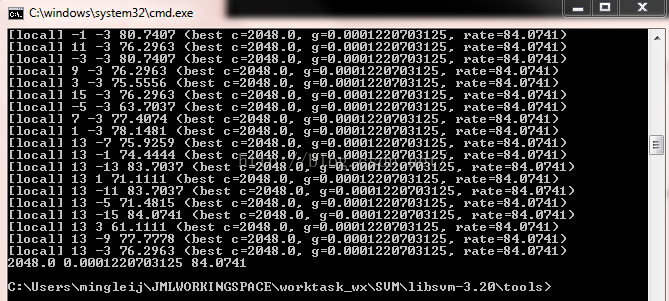
其意义表示:C=2048.0;y=0.0001220703125;交叉验证精度CV Rate=84.0741
打开tools文件夹,可以看到生成了两个文件:heart_scale.out和heart_scale_png,第一个就是搜索过程中的【local】和最优数据,第二个文件是gnuplot图像。
6、现在执行easy.py文件
Cmd命令行执行:
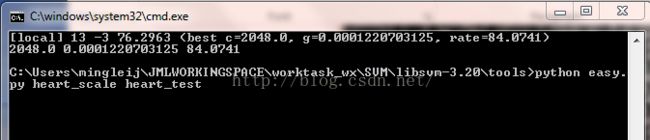
同样出现画图的界面,执行完毕,命令行出现下列结果:
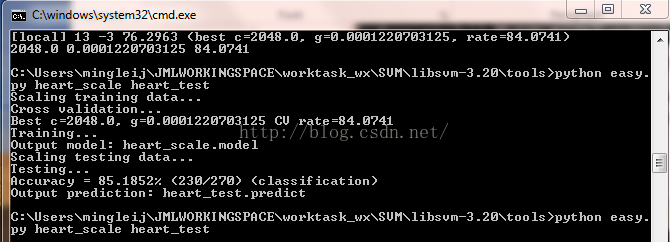
至此,libSVM就全部初始化完毕,可以在本机上尽情使用啦。
7、常见问题:
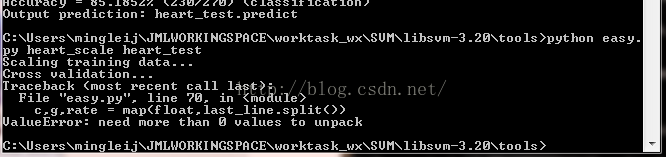
这是由于easy.py文件有误,把grid.py当做可编辑的文件执行了,应该按照前文那样修改。再附上一图:

现在执行就没问题了。
附录:几个简单的小问题:
import os
os.chdir('C:\libsvm-3.18\windows')#设定windows文件夹所在路径
from svmutilimport *
y, x =svm_read_problem('train.1.txt')#读入训练数据
yt, xt =svm_read_problem('test.1.txt')#训练测试数据
m = svm_train(y, x)#训练
svm_predict(yt,xt,m)#测试
得出结果精度为:Accuracy= 66.925% (2677/4000) (classification)
常用接口:
svm_train() : train an SVM model#训练
svm_predict() : predict testing data#预测
svm_read_problem() : read the data from aLIBSVM-format file.#读取libsvm格式的数据
svm_load_model() : load a LIBSVM model.
svm_save_model() : save model to a file.
evaluations() : evaluate prediction results.
- Function:svm_train#三种训练写法
There are three ways to call svm_train()
>>> model = svm_train(y, x [,'training_options'])
>>> model = svm_train(prob [,'training_options'])
>>> model = svm_train(prob, param)
通过一定的过程,可以提高预测的准确率(在文献2中有详细介绍):
a.转换数据为libsvm可用形式.(可以通过下载的数据了解格式)
b.进行一个简单的尺度变换
c.利用RBF kernel,利用cross-validation来查找最佳的参数 C 和 r
d.利用最佳参数C 和 r ,来训练整个数据集
e.测试
进入cmd模式下,输入如下代码,将现有数据进行适度变换,生成变换后的数据文件train.1.scale.txt
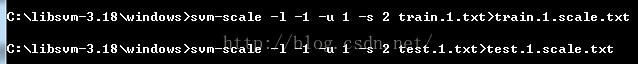
-l 变换后的下限
-u 变换后的上限
-s 参考上文
继续执行上述代码,则精确度有大幅度提升:精确度为Accuracy = 95.6% (3824/4000) (classification)。
执行上面的程序,find_parmaters函数,可以找到对应训练数据较好的参数。后面的log2c,log2g分别设置C和r的搜索范围。搜索机制是以2为底指数搜索,如 –log2c –3 , 3,1 就是参数C,从2^-3,2^-2,2^-1…搜索到2^3.
通过选择最优参数,再次提高预测的准确率:(需要把tools文件下的grid.py拷贝到'C:\libsvm-3.18\windows'下)
import os
os.chdir('C:\libsvm-3.18\windows')#设定路径
from svmutil import *
from grid import *
rate, param = find_parameters('train.1.scale.txt','-log2c -3,3,1 -log2g -3,3,1')
y, x = svm_read_problem('train.1.scale.txt')#读入训练数据
yt, xt = svm_read_problem('test.1.scale.txt')#训练测试数据
m = svm_train(y, x ,'-c 2 -g 4')#训练
p_label,p_acc,p_vals=svm_predict(yt,xt,m)#测试
小福利:打包下载的文件位置:http://pan.baidu.com/s/1mwJ18(参考)
参考链接:
http://baike.baidu.com/link?url=6qdvzLWnPo2Gx0P6UBYXR4iZSPFXThuciGZb413fCtauTBR-1G4GsNxdiJHqE54Mw4tV7RcZC6o_8T0tKgGWrK
http://www.cnblogs.com/zhangchaoyang/articles/2189606.html
http://blog.csdn.net/flydreamgg/article/details/4466023