Spark本地模式与Spark Standalone伪分布模式
红字部分来源于:董的博客
目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce,公用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
spark的本地模式类似于hadoop的单机模式,是为了方便我们调试或入门的。
1.先去官网下载下来http://spark.apache.org/downloads.html,不要下错了,下载pre-built(这是已经编译好了,产生了二进制文件的)for 你的hadoop版本。
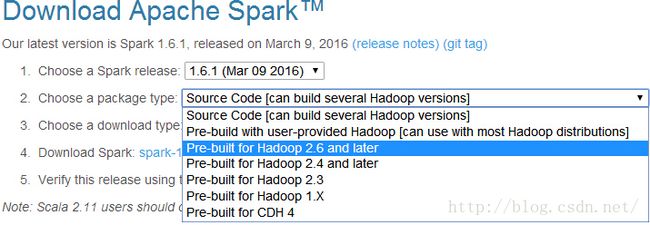
不过还要注意一点,打开http://spark.apache.org/documentation.html
选择你下载的版本,进去之后看一下它所相求的java等版本,最好按它要求来,要不然会出现很多问题。
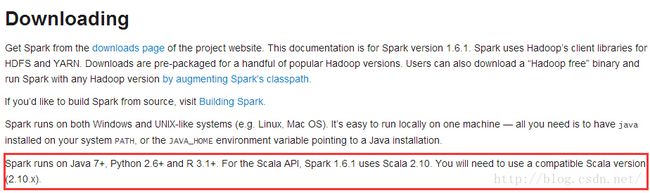
2.先用下local spark-shell,写个scala版的wordcount
快速开始:http://spark.apache.org/docs/latest/quick-start.html
什么都不用配,直接启动spark-shell就可以了。如果之后你搭好了集群,在spark-shell后加上master的url就是在集群上启动了。
guo@guo:~$ cd /opt/spark-1.6.1-bin-hadoop2.6/ guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ bin/spark-shell
启动spark-shell时自动生成了sparkcontext对象sc
scala> val testlog=sc.textFile("test.log")
testlog: org.apache.spark.rdd.RDD[String] = test.log MapPartitionsRDD[5] at textFile at <console>:27
#看一下第一行
scala> testlog.first
res2: String = hello world
统计下总行数,无参的方法可以不写()
scala> testlog.count res4: Long = 3 #看一下前三行,take()方法返回一个数组 scala> testlog.take(3) res5: Array[String] = Array(hello world, hello kitty, hello guo)主要代码就是下面这一行
scala> val wordcount=testlog.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey((a,b)=>a+b)
wordcount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[8] at reduceByKey at <console>:29
collect方法返回的是一个数组
scala> wordcount.collect res6: Array[(String, Int)] = Array((hello,3), (world,1), (guo,1), (kitty,1))遍历一下这个数组
scala> wordcount.collect.foreach(println) (hello,3) (world,1) (guo,1) (kitty,1)
Ctrl+D或:q退出spark shell
或者直接在idea里运行
/**
* Created by guo on 16-4-24.
*/
import org.apache.spark.{SparkContext,SparkConf}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile("/home/guo/test.log")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a+b)
wordCounts.collect().foreach(println)
sc.stop()
}
}
是不是要爱上scala了!
3.伪分布模式
启动master
guo@guo:~$ cd /opt/spark-1.6.1-bin-hadoop2.6/ guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.master.Master-1-guo.out guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ jps 2323 NameNode 3187 NodeManager 5204 Jps 2870 ResourceManager 2489 DataNode 2700 SecondaryNameNode 5116 Master启动master之后查看进程就会发现多了一个master,如果没有去看一下日志哪出错了。有的话你就可以打开浏览器看一下8080端口,网页上有这么一行 URL: spark://guo:7077,这代表master的地址,后面会用到。dfs和yarn的那些进程是没有的,那是我之前启动的。
启动slave
guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-slave.sh spark://guo:7077 starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.worker.Worker-1-guo.out guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ jps 2323 NameNode 3187 NodeManager 2870 ResourceManager 5241 Worker 2489 DataNode 5306 Jps 2700 SecondaryNameNode 5116 Master
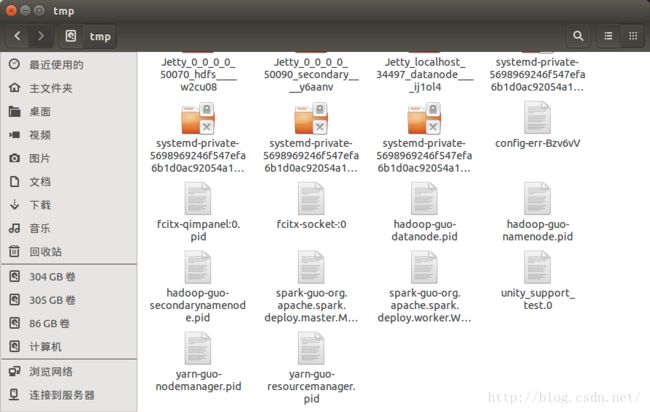
查看/tmp你会发现多了俩文件spark-guo-org.apache.spark.deploy.master.Master-1.pid和spark-guo-org.apache.spark.deploy.worker.Worker-1.pid,这里面存的就是进程ID。如果没有设置它会默认存在/tmp目录下,因为/tmp目录里的文件会自动清除,所以在生产环境中要设置一下SPARK_PID_DIR。
如果想启动多个worker怎么办?
可以这样,先关掉slave,然后export 。。。
guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/stop-slave.sh stopping org.apache.spark.deploy.worker.Worker guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ export SPARK_WORKER_INSTANCES=3 guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-slave.sh spark://guo:7077 starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.worker.Worker-1-guo.out starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.worker.Worker-2-guo.out starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.worker.Worker-3-guo.out guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ jps 5536 Worker 2323 NameNode 3187 NodeManager 5606 Worker 2870 ResourceManager 2489 DataNode 5675 Worker 5740 Jps 2700 SecondaryNameNode 5116 Master
想搞HA怎么办(两个master)?
修改这个脚本
guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ gedit ./sbin/start-master.sh
"${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS 1 \把其中的1改为2就可以了
然后再启动master
guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ sbin/start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark-1.6.1-bin-hadoop2.6/logs/spark-guo-org.apache.spark.deploy.master.Master-2-guo.out guo@guo:/opt/spark-1.6.1-bin-hadoop2.6$ jps 5536 Worker 2323 NameNode 3187 NodeManager 5827 Master 5606 Worker 2870 ResourceManager 2489 DataNode 5675 Worker 2700 SecondaryNameNode 5116 Master 5935 Jps
vi中 /XX 查找XX