SparkML之预测(一)线性回归分析源码阅读
package org.apache.spark.mllib.regression包含了两个部分:LinearRegressionModel和LinearRegressionWithSGD
1、回归的模型(class和object),class 的参数是继承GeneralizedLinearModel广义回归模型,之后形成一个完整的
线性回归模型,object上面的方法用于导出已经保存的模型进行回归
2、LinearRegressionWithSGD:随机梯度下降法,cost function:f(weights) = 1/n ||A weights-y||^2也就是前面
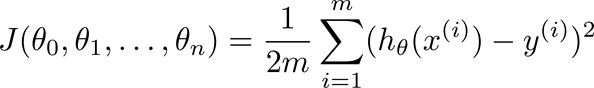
记住这个还是加上m更能体现问题,(除以m表示均方误差)
LinearRegressionWithSGD是继承GeneralizedLinearAlgorithm[LinearRegressionModel]广义回归类
1、回归模型源码如下
/** * Regression model trained using LinearRegression. * * @param weights Weights computed for every feature.(每个特征的权重向量) * @param intercept Intercept computed for this model.(此模型的偏置或残差) * */ @Since("0.8.0") class LinearRegressionModel @Since("1.1.0") ( @Since("1.0.0") override val weights: Vector, @Since("0.8.0") override val intercept: Double) extends GeneralizedLinearModel(weights, intercept) with RegressionModel with Serializable with Saveable with PMMLExportable { //进行预测:Y = W*X+intercept override protected def predictPoint( dataMatrix: Vector, weightMatrix: Vector, intercept: Double): Double = { weightMatrix.toBreeze.dot(dataMatrix.toBreeze) + intercept } //模型保存包含:保存的位置,名字,权重和偏置 @Since("1.3.0") override def save(sc: SparkContext, path: String): Unit = { GLMRegressionModel.SaveLoadV1_0.save(sc, path, this.getClass.getName, weights, intercept) } override protected def formatVersion: String = "1.0" } //加载上面保存和的模型,用load(sc,存储路径) @Since("1.3.0") object LinearRegressionModel extends Loader[LinearRegressionModel] { @Since("1.3.0") override def load(sc: SparkContext, path: String): LinearRegressionModel = { val (loadedClassName, version, metadata) = Loader.loadMetadata(sc, path) // Hard-code class name string in case it changes in the future val classNameV1_0 = "org.apache.spark.mllib.regression.LinearRegressionModel" (loadedClassName, version) match { case (className, "1.0") if className == classNameV1_0 => val numFeatures = RegressionModel.getNumFeatures(metadata) val data = GLMRegressionModel.SaveLoadV1_0.loadData(sc, path, classNameV1_0, numFeatures) new LinearRegressionModel(data.weights, data.intercept) case _ => throw new Exception( s"LinearRegressionModel.load did not recognize model with (className, format version):" + s"($loadedClassName, $version). Supported:\n" + s" ($classNameV1_0, 1.0)") } } }
2、LinearRegressionWithSGD类,该类是基于无正规化的随机梯度下降,而且是继承GeneralizedLinearAlgorithm[LinearRegressionModel]广义回归类
/** * Train a linear regression model with no regularization using Stochastic Gradient Descent. * This solves the least squares regression formulation * f(weights) = 1/n ||A weights-y||^2^ * (which is the mean squared error). * Here the data matrix has n rows, and the input RDD holds the set of rows of A, each with * its corresponding right hand side label y. * See also the documentation for the precise formulation. */ @Since("0.8.0") class LinearRegressionWithSGD private[mllib] ( private var stepSize: Double,//步长 private var numIterations: Int,//迭代次数 private var miniBatchFraction: Double)//参与迭代样本的比列 extends GeneralizedLinearAlgorithm[LinearRegressionModel] with Serializable { private val gradient = new LeastSquaresGradient() //阅读:3 private val updater = new SimpleUpdater() //阅读:4 @Since("0.8.0") override val optimizer = new GradientDescent(gradient, updater) //阅读:5 .setStepSize(stepSize) .setNumIterations(numIterations) .setMiniBatchFraction(miniBatchFraction) /** * Construct a LinearRegression object with default parameters: {stepSize: 1.0, * numIterations: 100, miniBatchFraction: 1.0}. */ @Since("0.8.0") def this() = this(1.0, 100, 1.0) override protected[mllib] def createModel(weights: Vector, intercept: Double) = { new LinearRegressionModel(weights, intercept) } } /** * Top-level methods for calling LinearRegression. * */ @Since("0.8.0") object LinearRegressionWithSGD { /** * Train a Linear Regression model given an RDD of (label, features) pairs. We run a fixed number * of iterations of gradient descent using the specified step size. Each iteration uses * `miniBatchFraction` fraction of the data to calculate a stochastic gradient. The weights used * in gradient descent are initialized using the initial weights provided. * * @param input RDD of (label, array of features) pairs. Each pair describes a row of the data * matrix A as well as the corresponding right hand side label y * @param numIterations Number of iterations of gradient descent to run. * @param stepSize Step size to be used for each iteration of gradient descent. * @param miniBatchFraction Fraction of data to be used per iteration. * @param initialWeights Initial set of weights to be used. Array should be equal in size to * the number of features in the data. * */ @Since("1.0.0") def train( input: RDD[LabeledPoint], numIterations: Int, stepSize: Double, miniBatchFraction: Double, initialWeights: Vector): LinearRegressionModel = { new LinearRegressionWithSGD(stepSize, numIterations, miniBatchFraction) .run(input, initialWeights) } /** * Train a LinearRegression model given an RDD of (label, features) pairs. We run a fixed number * of iterations of gradient descent using the specified step size. Each iteration uses * `miniBatchFraction` fraction of the data to calculate a stochastic gradient. * * @param input RDD of (label, array of features) pairs. Each pair describes a row of the data * matrix A as well as the corresponding right hand side label y * @param numIterations Number of iterations of gradient descent to run. * @param stepSize Step size to be used for each iteration of gradient descent. * @param miniBatchFraction Fraction of data to be used per iteration. * */ @Since("0.8.0") def train( input: RDD[LabeledPoint], numIterations: Int, stepSize: Double, miniBatchFraction: Double): LinearRegressionModel = { new LinearRegressionWithSGD(stepSize, numIterations, miniBatchFraction).run(input) } /** * Train a LinearRegression model given an RDD of (label, features) pairs. We run a fixed number * of iterations of gradient descent using the specified step size. We use the entire data set to * compute the true gradient in each iteration. * * @param input RDD of (label, array of features) pairs. Each pair describes a row of the data * matrix A as well as the corresponding right hand side label y * @param stepSize Step size to be used for each iteration of Gradient Descent. * @param numIterations Number of iterations of gradient descent to run. * @return a LinearRegressionModel which has the weights and offset from training. * */ @Since("0.8.0") def train( input: RDD[LabeledPoint], numIterations: Int, stepSize: Double): LinearRegressionModel = { train(input, numIterations, stepSize, 1.0) } /** * Train a LinearRegression model given an RDD of (label, features) pairs. We run a fixed number * of iterations of gradient descent using a step size of 1.0. We use the entire data set to * compute the true gradient in each iteration. * * @param input RDD of (label, array of features) pairs. Each pair describes a row of the data * matrix A as well as the corresponding right hand side label y * @param numIterations Number of iterations of gradient descent to run. * @return a LinearRegressionModel which has the weights and offset from training. * */ @Since("0.8.0") def train( input: RDD[LabeledPoint], numIterations: Int): LinearRegressionModel = { train(input, numIterations, 1.0, 1.0) } }
3、最小平方梯度,首先联系我们的代价(损失)函数,如下:
损失函数源码标记为:L = 1/2n ||A weights-y||^2
每个样本的梯度值:![]()
每个样本的误差值:![]()
第一个compute返回的是 ![]() ,第二个compute返回的是
,第二个compute返回的是![]()
class LeastSquaresGradient extends Gradient { override def compute(data: Vector, label: Double, weights: Vector): (Vector, Double) = { val diff = dot(data, weights) - label val loss = diff * diff / 2.0//误差 val gradient = data.copy scal(diff, gradient)////梯度值x*(y-h(x)) (gradient, loss) } override def compute( data: Vector, label: Double, weights: Vector, cumGradient: Vector): Double = { val diff = dot(data, weights) - label//h(x)-y axpy(diff, data, cumGradient)//y = x*(h(x)-y)+cumGradient /**axpy用法: * Computes y += x * a, possibly doing less work than actually doing that operation * def axpy[A, X, Y](a: A, x: X, y: Y)(implicit axpy: CanAxpy[A, X, Y]) { axpy(a,x,y) } */ diff * diff / 2.0 } }
4、权重更新(SimpleUpdater),更新公式如下:
![]()
返回的时候偏置项设置为0了
class SimpleUpdater extends Updater { override def compute( weightsOld: Vector,//上一次计算后的权重向量 gradient: Vector,//本次迭代的权重向量 stepSize: Double,//步长 iter: Int,//当前迭代次数 regParam: Double): (Vector, Double) = { val thisIterStepSize = stepSize / math.sqrt(iter)//学习速率 a val brzWeights: BV[Double] = weightsOld.toBreeze.toDenseVector brzAxpy(-thisIterStepSize, gradient.toBreeze, brzWeights) //brzWeights + = gradient.toBreeze-thisIterStepSize (Vectors.fromBreeze(brzWeights), 0) } }
5权重优化
权重优化采用的是随机梯度降,但是默认的是miniBatchFraction= 1.0。
/** * Class used to solve an optimization problem using Gradient Descent. * @param gradient Gradient function to be used. * @param updater Updater to be used to update weights after every iteration. */ class GradientDescent private[spark] (private var gradient: Gradient, private var updater: Updater) extends Optimizer with Logging { private var stepSize: Double = 1.0 private var numIterations: Int = 100 private var regParam: Double = 0.0 private var miniBatchFraction: Double = 1.0 private var convergenceTol: Double = 0.001//收敛公差 /** * Set the initial step size of SGD for the first step. Default 1.0. * In subsequent steps, the step size will decrease with stepSize/sqrt(t) */ def setStepSize(step: Double): this.type = { this.stepSize = step this } /** * :: Experimental :: * Set fraction of data to be used for each SGD iteration. * Default 1.0 (corresponding to deterministic/classical gradient descent) */ @Experimental def setMiniBatchFraction(fraction: Double): this.type = { this.miniBatchFraction = fraction this } /** * Set the number of iterations for SGD. Default 100. */ def setNumIterations(iters: Int): this.type = { this.numIterations = iters this } /** * Set the regularization parameter. Default 0.0. */ def setRegParam(regParam: Double): this.type = { this.regParam = regParam this } /** * Set the convergence tolerance. Default 0.001 * convergenceTol is a condition which decides iteration termination. * The end of iteration is decided based on below logic. * * - If the norm of the new solution vector is >1, the diff of solution vectors * is compared to relative tolerance which means normalizing by the norm of * the new solution vector. * - If the norm of the new solution vector is <=1, the diff of solution vectors * is compared to absolute tolerance which is not normalizing. * * Must be between 0.0 and 1.0 inclusively. */ def setConvergenceTol(tolerance: Double): this.type = { require(0.0 <= tolerance && tolerance <= 1.0) this.convergenceTol = tolerance this } /** * Set the gradient function (of the loss function of one single data example) * to be used for SGD. */ def setGradient(gradient: Gradient): this.type = { this.gradient = gradient this } /** * Set the updater function to actually perform a gradient step in a given direction. * The updater is responsible to perform the update from the regularization term as well, * and therefore determines what kind or regularization is used, if any. */ def setUpdater(updater: Updater): this.type = { this.updater = updater this } /** * :: DeveloperApi :: * Runs gradient descent on the given training data. * @param data training data * @param initialWeights initial weights * @return solution vector */ @DeveloperApi def optimize(data: RDD[(Double, Vector)], initialWeights: Vector): Vector = { val (weights, _) = GradientDescent.runMiniBatchSGD( data, gradient, updater, stepSize, numIterations, regParam, miniBatchFraction, initialWeights, convergenceTol) weights } } /** * :: DeveloperApi :: * Top-level method to run gradient descent. */ @DeveloperApi object GradientDescent extends Logging { /** * Run stochastic gradient descent (SGD) in parallel using mini batches. * In each iteration, we sample a subset (fraction miniBatchFraction) of the total data * in order to compute a gradient estimate. * Sampling, and averaging the subgradients over this subset is performed using one standard * spark map-reduce in each iteration. * * @param data Input data for SGD. RDD of the set of data examples, each of * the form (label, [feature values]). * @param gradient Gradient object (used to compute the gradient of the loss function of * one single data example) * @param updater Updater function to actually perform a gradient step in a given direction. * @param stepSize initial step size for the first step * @param numIterations number of iterations that SGD should be run. * @param regParam regularization parameter * @param miniBatchFraction fraction of the input data set that should be used for * one iteration of SGD. Default value 1.0. * @param convergenceTol Minibatch iteration will end before numIterations if the relative * difference between the current weight and the previous weight is less * than this value. In measuring convergence, L2 norm is calculated. * Default value 0.001. Must be between 0.0 and 1.0 inclusively. * @return A tuple containing two elements. The first element is a column matrix containing * weights for every feature, and the second element is an array containing the * stochastic loss computed for every iteration. */ def runMiniBatchSGD( data: RDD[(Double, Vector)], gradient: Gradient, updater: Updater, stepSize: Double, numIterations: Int, regParam: Double, miniBatchFraction: Double, initialWeights: Vector, convergenceTol: Double): (Vector, Array[Double]) = { // convergenceTol should be set with non minibatch settings if (miniBatchFraction < 1.0 && convergenceTol > 0.0) { logWarning("Testing against a convergenceTol when using miniBatchFraction " + "< 1.0 can be unstable because of the stochasticity in sampling.") } //把历史的权重放在一个数组中 val stochasticLossHistory = new ArrayBuffer[Double](numIterations) // Record previous weight and current one to calculate solution vector difference //初始化权重 var previousWeights: Option[Vector] = None var currentWeights: Option[Vector] = None //训练的样本数 val numExamples = data.count() // if no data, return initial weights to avoid NaNs if (numExamples == 0) { logWarning("GradientDescent.runMiniBatchSGD returning initial weights, no data found") return (initialWeights, stochasticLossHistory.toArray) } if (numExamples * miniBatchFraction < 1) { logWarning("The miniBatchFraction is too small") } // Initialize weights as a column vector var weights = Vectors.dense(initialWeights.toArray) val n = weights.size /** * For the first iteration, the regVal will be initialized as sum of weight squares * if it's L2 updater; for L1 updater, the same logic is followed. */ var regVal = updater.compute( weights, Vectors.zeros(weights.size), 0, 1, regParam)._2 var converged = false // indicates whether converged based on convergenceTol判断是否收敛 var i = 1 while (!converged && i <= numIterations) { //广播weights val bcWeights = data.context.broadcast(weights) // Sample a subset (fraction miniBatchFraction) of the total data // compute and sum up the subgradients on this subset (this is one map-reduce) val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i) .treeAggregate((BDV.zeros[Double](n), 0.0, 0L))( seqOp = (c, v) => { // c: (grad, loss, count), v: (label, features) val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1)) (c._1, c._2 + l, c._3 + 1) }, combOp = (c1, c2) => { // c: (grad, loss, count) (c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3) }) if (miniBatchSize > 0) { /** * lossSum is computed using the weights from the previous iteration * and regVal is the regularization value computed in the previous iteration as well. */ //保存误差,更新权重 stochasticLossHistory.append(lossSum / miniBatchSize + regVal) val update = updater.compute( weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble), stepSize, i, regParam) weights = update._1 regVal = update._2 previousWeights = currentWeights currentWeights = Some(weights) if (previousWeights != None && currentWeights != None) { converged = isConverged(previousWeights.get, currentWeights.get, convergenceTol) } } else { logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero") } i += 1 } logInfo("GradientDescent.runMiniBatchSGD finished. Last 10 stochastic losses %s".format( stochasticLossHistory.takeRight(10).mkString(", "))) //返回权重和历史误差数组 (weights, stochasticLossHistory.toArray) }