hadoop+zookeeper+hbase安装、配置及应用实例
出于种种原因,想要搭建一个小集群,来搞搞数据处理。
1、安装ubuntu10.04
为了操作的简便,在所有机器上创建相同用户名和相同密码的用户。本例创建了相同的用户ibm。
修改机器名:$ hostname 机器名。(注:重启ubuntu后,hostname会变为原来的默认值,所以重启电脑后记得把hostname改回来,免得与下面设置的/etc/hosts文件不一致!)
在/etc/hosts 中添加机器名和相应的IP:
127.0.0.1 localhost
125.216.227.182 ibm
125.216.227.53 ibm00
2、开启ssh 服务
注意:自动安装openssh-server 时,先要进行sudo apt-get update 操作。
安装openssh-server:$ sudo apt-get install openssh-server
3、建立ssh 无密码登录
(1)在NameNode 上实现无密码登录本机:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa ,
直接回车,完成后会在~/.ssh/生成两个文件:id_dsa 和id_dsa.pub。这两个是成对出现,类似钥匙和锁。
再把id_dsa.pub 追加到授权key 里面(当前并没有authorized_keys文件):
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys。
完成后可以实现无密码登录本机:$ ssh localhost。
(2)实现NameNode 无密码登录其他DataNode(不用设置DataNode无密码登录NameNode!):
把NameNode 上的id_dsa.pub 文件追加到dataNode 的authorized_keys 内( 以125.216.227.182节点为例):
a. 拷贝NameNode 的id_dsa.pub 文件:
$ scp id_dsa.pub [email protected]:/home/ibm/
b. 登录125.216.227.53,执行$ cat id_dsa.pub >> .ssh/authorized_keys
其他的dataNode 执行同样的操作。
4、关闭防火墙
$ sudo ufw disable
注意:这步非常重要。如果不关闭,会出现找不到datanode 问题。
5、安装jdk1.6
在ubuntu默认的源中,可以找到的jdk为openjdk,其正好是1.6的,可以使用
$sudo apt-cache search jdk可选列表,然后安装
安装配置JAVA 1.6.20
$sudo apt-get install openjdk-6-jre openjdk-6-jdk
然后配置环境变量:
vi /etc/profile
在其中添加如下:
export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
保存退出。
重启ubuntu!
使用命令测试:
$java -version
注意:每台机器的java 环境最好一致。
6、安装hadoop
下载hadoop-0.20.2.tar.gz:
解压:$ tar –zvxf hadoop-0.20.2.tar.gz
把Hadoop 的安装路径添加到环/etc/profile 中:
export HADOOP_HOME=/home/ibm/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
7、配置hadoop
hadoop 的主要配置都在hadoop-0.20.2/conf 下。
(1)在conf/hadoop-env.sh 中配置Java 环境(namenode 与datanode 的配置相同):
$ vim hadoop-env.sh
$ export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk
(2)配置conf/masters 和conf/slaves 文件:(只在namenode 上配置)
masters: 125.216.227.182
slaves:125.216.227.53
(3)配置conf/core-site.xml, conf/hdfs-site.xml 及conf/mapred-site.xml(简单配置,namenode 与datanode 的配置相同)
core-site.xml:
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/ibm/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://125.216.227.182:9000</value>
</property>
</configuration>
hdfs-site.xml:( replication 默认为3,如果不修改,datanode 少于三台就会报错)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>125.216.227.182:9001</value>
</property>
</configuration>
{
namenode 与datanode的配置一样,只是datanode不用配master与slave,其中core.xml与mapred-site.xml的value值均要配成namenode的ip地址。
}
8、运行hadoop
进入hadoop-0.20.2/bin,首先格式化文件系统:$ hadoop namenode –format
{
如果在这里输入命令 hadoop namenode –format,返回bash: hadoop:找不到命令;则进入hadoop文件,输入命令bin/hadoop namenode -format 就可以格式化了。
}
启动Hadoop:$ start-all.sh
通过jps命令查看当前信息。
二. zookeeper的安装配置
zookeeper的安装配置比较简单,下载、解压到/home/ibm/zookeeperinstall,在zookeeperinstall目录下创建data目录来存放zookeeper的数据,这里需要配置的就是/zookeeper/conf下的zoo.cfg配置文件,zookeeper最初只有zoo.sample.cfg,将其改名为zoo.cfg,然后配置:
起步阶段只需考虑dataDir和clientPort属性,
参考别人的教程配置为:
# the directory where the snapshot is stored.
dataDir=/home/ibm/zookeeperinstall/data
# the port at which the clients will connect
clientPort=2222
最后因为我们要配置的是集群,所以需要在zoo.cfg中添加
server.1=125.216.227.182:2888:3888
server.2=125.216.227.53:2888:3888
其中等号左边1,2是代表这是第几个zookeeper,也即机器的id,我们还需要在每台机器上的data目录下创建一个文件myid,其内容即为其ip对应的id。等号右边依次为机器ip,通信端口,选举leader端口(注:详细的暂没研究)。
三. HBase安装配置
下载hbase-0.90.6.tar.gz,解压到/home/ibm,并用mv修改其目录名为hbase,
开始集群配置:
1、修改conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk
export HBASE_CLASSPATH=/home/ibm/hadoop/conf
export HBASE_MANAGES_ZK=false
2、修改hbase-site.xml,增加以下内容
<property>
<name>hbase.rootdir</name>
<value>hdfs://ibm:9000/hbase</value>(注:这里须hadoop-config/core-site.xml中的fs.default.name保持一致,但是貌似必须要用ibm,而不能用ip地址,开始我用ip地址,后面看logs才发现是这里出错)
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2222</value>(注:这里的端口需要和zookeeper的端口配置值一样)
<description>Property from ZooKeeper's config zoo.cfg.</description>
</property>
3、把/home/frank/HadoopInstall/hadoop-config/hdfs-site.xml文件拷贝至hbase的conf文件夹下
4、把${ZOOKEEPER_HOME}/conf/zoo.cfg拷贝至hbase的conf文件夹下
5、在conf/regionservers中添加hadoop-config/conf/slaves中所有的datanode节点。
6、删除/hbase-0.90.2/lib/hadoop-core-0.20-append-r1056497.jar
拷贝/hadoop-0.20.2/hadoop-0.20.0-core.jar到/hbase-0.90.2/lib/
7、最后,把配置好的hbase-0.20.2,拷贝到其它节点scp
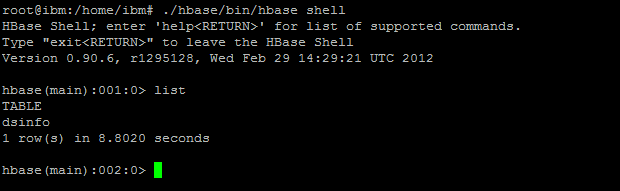
到了这里整个配置就完成了,在namenode上启动hadoop集群,接着在每台机器上启动zookeeper,最后启动hbase,以./hbase/conf/hbase shell进入hbase的shell命令行,运行status查看当前的状态,如果命令可正常运行说明集群配置成功。
四. 一个HBase的Java客户端实例
(操作环境:window7,myeclipse)
(1)下载hbase-0.90.6-tar.gz
(2)创建一个java project——“HBaseClient”,将解压得到的hbase-0.90.6.jar,hbase-0.90.6-tests.jar添加到build path。
(3)新建hbase-site.xml(拷贝你的同名hbase配置文件过来也行),要将其添加到工程的classpath中,也即跟src平行,这是因为下面的代码中初始化配置使用的是HBaseConfiguration.create(),关于这个在hbase的api使用说明中有这么一段注释:“You need a configuration object to tell the client where to connect.When you create a HBaseConfiguration, it reads in whatever you've set into your hbase-site.xml and in hbase-default.xml, as long as these can be found on the CLASSPATH”。
完整的配置文件为:
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://125.216.227.182:9000/hbase</value>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.clientPort</name>
- <value>2222</value>
- <description>property from zookeeper zoo.cfg.</description>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>125.216.227.182,125.216.227.53</value>
- </property>
- <property skipInDoc="true">
- <name>hbase.defaults.for.version</name>
- <value>0.90.6</value>
- </property>
- </configuration>
(4)新建类MyHBaseClient,在hbase中创建一个简单的表dsinfo,完整代码为:
- public class MyHBaseClient {
- private static Configuration conf = null;
- static {
- conf = HBaseConfiguration.create();
- }
- /**
- * create table
- * @param args
- */
- public static void createTable(String tablename,String []cfs)throws IOException{
- HBaseAdmin admin = new HBaseAdmin(conf);
- if(admin.tableExists(tablename)){
- System.out.println("table has existed.");
- }
- else{
- HTableDescriptor tableDesc = new HTableDescriptor(tablename);
- for(int i=0;i<cfs.length;i++){
- tableDesc.addFamily(new HColumnDescriptor(cfs[i]));
- }
- admin.createTable(tableDesc);
- System.out.println("create table successfully.");
- }
- }
- public static void main(String []args){
- try{
- createTable("dsinfo", new String[]{"publish","mark"});
- }catch(IOException e){
- e.printStackTrace();
- }
- }
- }