从百万关键字中提取前K个关键字
转载请注明出处:http://blog.csdn.net/mxway/article/details/21776727
在搜索引擎中经常需要对最近一段时间关键字的搜索次数进行统计,并找出搜索次数最多的前K个关键字。在上一篇文章中我们分析了用stl map及使用字典树进行统计的优缺点。对随机生成的100万个关键字进行统计后,还剩大概70万个关键字;也就是有大约30万的关键字与其它重复。下面就讨论几种方法来实现从70万个单词中找出“搜索次数”最高的K个单词。无论使用上篇文章中的哪种方法进行统计,其最后的结果都是以字母表(a-z)的顺序输出到文件中;但是出现的次数却不是有序排列的。
方法一、用数组开辟N个空间,将关键字存储到这N个空间中用选择排序的方法,进行N*K次比较就可以将出现次数最多的K个关键字存储到数组的将K个单元中;时间复杂度为O(K*N)。也可以使用快速排序对N个关键字进行全排序;其时间复杂度为O(NlgN)。
方法二、使用最小堆实现,最小堆的思想是,一边从外部文件中读取,一边将读取到的关键字个数与最小堆的堆顶关键字个数进行比较;如果堆的元素大于读取到的那个单词,那么刚从文件中读到的那个关键字就不需要加入到堆中;如果刚读到的那个关键字次数大于堆顶元素,将堆顶元素直接用刚读到的那个关键字替换,并进行堆的下移操作。在这我们并没有使用最大堆来实现;因为使用最大堆不好控制关键字什么时候加入到堆中。
首先定义一个结构体用于存放关键字及其出现次数
struct Node{
string word;//存储关键字
int cnt;//存储关键字出现次数
};
使用最小堆可以实现边读取边比较,不需要额外的空间。而在K个元素的最小堆中进行下移操作其时间复杂度为O(lgK),要在N个关键字中找出前K个关键字其时间复杂度为O(NlgK)。空间复杂度为O(K)。
当文件中的所有关键字读取完后,最小堆中的K个元素就是搜索次数最多的K个关键字。如果需要对关键字按出现次数从高到低进行输出,只需要另外申请K个空间就可以将关键字按出现次数从高到低进行输出。下面给出最小堆实现的C++源码。
#include<iostream>
#include<fstream>
#include<ctime>
#include<string>
using namespace std;
//找出单词出现次数最多的前K个单词
const int K = 10;
struct Node{
string word;//存储关键字
int cnt;//存储关键字出现次数
bool operator <(const struct Node &b)
{
return cnt < b.cnt;
}
void operator=(const struct Node &b)
{
word = b.word;
cnt = b.cnt;
}
};
struct Node data[K];
/*
*
*初始化堆中的数据
*
*/
void Init()
{
int i;
for(i=0; i<K; i++)
{
data[i].cnt = 0;
}
}
/*
*
* 将数据插入到最小堆中。
*
*/
void InsertData(Node &elem, const int MAXNum)
{
int pos = 0;
int cur = 2*pos+1;
while(cur < MAXNum)
{
if(cur < MAXNum-1 && (data[cur+1] < data[cur]) )//找到两个子树中较小的那个节点。
{
//右子树较小
cur++ ;
}
if(elem < data[cur])break;//不需要再移动数据了。
else
{
data[pos] = data[cur];
pos = cur;
cur = 2*pos+1;//先指向左子树
}
}
data[pos] = elem;
}
/*
*
* 按单词出现次数的从小到大输出单词.
*
*/
void outPutWord()
{
int i;
for(i=0; i<K; i++)
{
cout<<data[0].word<<" "<<data[0].cnt<<endl;//堆顶的元素一定是最小的元素。
//将堆顶元素用最后一个元素覆盖。然后将堆顶元素向下调整。
Node temp = data[K-i-1];
//将最后一个元素删除,然后将最后一个元素重新加入到堆中。
InsertData(temp, K-i-1);//元素减少了1个
}
}
int main()
{
struct Node tempNode;
clock_t start,end;
ifstream in("result.dat");
Init();
start = clock();
while(in>>tempNode.word>>tempNode.cnt)
{
if(data[0] < tempNode)//堆顶的单词出现次数小于现在单词出现的次数
{//单词出现次数小于堆顶的不需要考虑了。
InsertData(tempNode,K);
}
}
end = clock();
cout<<"找前K个关键字的时间:"<<end-start<<"毫秒"<<endl;
//输出前K个关键字
outPutWord();
return 0;
}
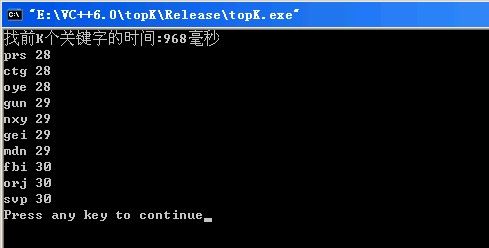
运行结果: