mysql 数据和索引的存储关系
关系型数据库都有索引的概念,那么索引和数据库真实数据在磁盘中都是一种什么样的存储结构呢。这篇文章让我们一起来探讨下。
mysql是目前市面上比较成熟的关系型数据库,阿里集团目前都是mysql作为db存储(支付宝目前在推oceanbase),就拿它来做例子介绍吧。
先介绍几个基础概念:
1). 什么是索引?
高性能mysql一书上对索引的解释是,"索引是存储引擎用于快速找到记录的一种数据结构".
理解索引最简单的办法就是去看一看一本书的"索引"(目录)部分. 通过找到目录中对应的特定主题的页码,可快速定位到你要找的主题.
mysql中也一样,数据查找时,先看看查询条件是否命中某条索引,符合则通过索引找到相关数据返回,不符合则需要全表扫描,找到与条件符合的行返回.
2). 存储引擎
mysql的存储引擎主要有如下几种. innodb, MyISAM,Archive,Blackhole,CSV,Federated,Memory,Merge,NDB.
另外mysql还支持一些第三方存储引擎: OLTP , 列存储引擎Infobright , 社区存储引擎Aria等
上面的每一种存储引擎在不同的场景下有不同的作用, mysql老版本的默认存储引擎是MyIsam.但l在5.5以后默认的存储引擎已经从MyISAM改为Innodb了.
MyISAM 和 Innodb的主要区别有2个:
MyISAM 不支持事务, Innodb支持.
MyISAM是表锁, Innodb是行锁.
当然存储引擎不一样,那么索引的实现方式也就不一致.
如果没做特殊说明,我们提到的mysql存储引擎指的都是Innodb 引擎, 索引都指的是B+Tree索引.
本文要讨论什么?
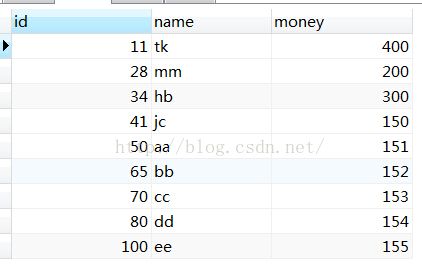
假设有一张表test, 它的字段和数据如上图. id 是主键, money字段上建了b-tree索引, 那么上图中的数据和索引在磁盘中是如何存储的是本文的讨论重点.
因为id是主键.存储引擎会默认为主键建主键索引, 非主键的索引money称为二级索引.
innodb的主键索引都是聚簇索引,聚簇索引把数据行放在索引数据结构的叶子节点上,一个表只能有一个聚簇索引. 如果没有主键, Innodb会选择一个唯一的非空索引代替,如果没有这样的索引,Innodb会隐含的定义一个主键来作为聚簇索引.
首先我们看看聚簇索引在磁盘中的存储方式,如下图:
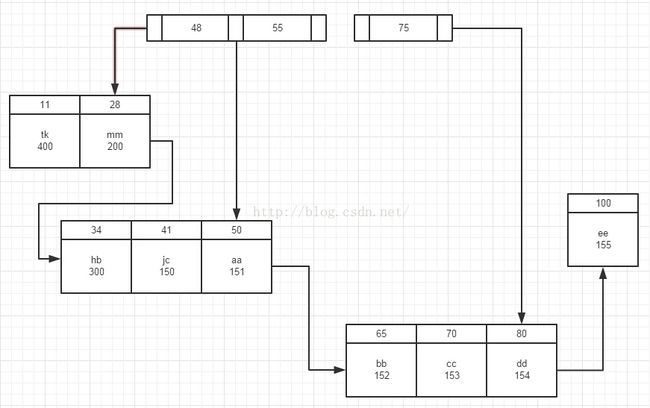
注意: 上图中非叶子节点只保存了索引列,叶子节点保存了索引列和数据行.
聚簇索引的优点如下:
1, 数据访问更快, 聚簇索引把数据和索引保存在同一个B-tree中,索引命中即意味中数据全部命中.
2, 使用覆盖索引的扫描的查询可以直接使用页节点中的主键值.
缺点如下:
1, 聚簇索引最大限度的提高了I/O密集型应用的性能.
2, 插入速度严重依赖插入顺序.
3, 更新聚簇索引列的代价很高,因为需要移位.
4, 插入新数据时,或者主键裂需要移动的时候,可能面临“页分裂”.
5, 非聚簇索引(二级索引)包含了聚簇索引,如果聚簇索引较大,二级索引也会很大(二级索引的叶子节点包含了主键列的值).
那么二级索引列 money的存储结构又是怎么样的呢?
截图来自《高性能mysql第三版》
可以看出,innodb的二级索引是直接在叶子节点存储了聚簇索引的值.
二级索引的叶子节点保存的不是指向行的物理位置指针,而是行的主键值.这样行的在面临页分裂时,不需要单独维护二级索引.
而MyISAM存储引擎则是主键索引和其它二级索引一样都指向了行数据.
经过上面的讨论,我们应该大致清楚了,mysql表里的数据是如何在磁盘中存储的。