《Kafka 0.9.0 Documentation》----Design
支持高吞吐量,支持大容量数据积压,支持低延迟率,分区消费模型,良好的容错性。
二、持久化
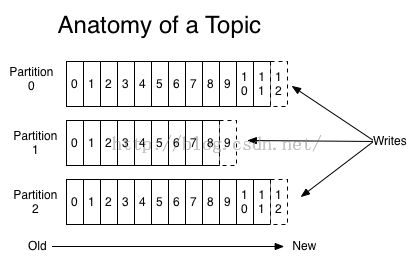
Kafka用硬盘来持久化消息,所有消息被直接保存到硬盘上。主题中的分区即是一个硬盘持久化单元。
在Kafka中,分区文件被认为是一个队列,写消息时被写到该队列的尾端,读消息时从队列的前端向尾端遍历(Kafka也允许随机读消息)。
以上模型的优势在于每个读或者写操作的时间复杂度为O(1),读和读之间不互斥,读和写之间不互斥。如图1所示。
图1
三、效率
1、群聚小的IO操作从而减少IO操作次数,减少传输数据过程中读取复制数据的次数。
2、压缩,Kafka支持群聚消息然后进行压缩,支持的压缩算法有GZIP和Snappy。通过群聚压缩,可以提升传输效率。
1、生产者自己决定“将单个消息发送给绑定主题的哪个分区”的策略,可以是随机策略,也可以是根据消息的某个key值来进行映射的策略等等。
2、Kafka中的每个"broker"都支持对“某个主题内每个分区的'leader'是哪个'broker'”询问的回答。
3、生产者询问Kafka中的某个"broker"关于“某个主题内每个分区的'leader'是哪个'broker'”,同时自己决定将单个消息发送给该主题的哪个分区。结合以上信息,生产者直接跟所选分区的"leader broker"通信,传输消息数据。
4、生产者可以群聚消息进行传输,提升传输效率。这里可以配置两个参数:群聚消息数量阈值N和群聚消息时间延迟阈值T。当群聚N条消息时,完成群聚,传输消息;当为了群聚延时T时间时,完成群聚,传输消息。
1、生产者“推”消息到Kafka Cluster,消费者从Kafka Cluster“拉”消息
消费者与Kafka Cluster之间采用“拉”的消息传输模式的好处有:
1)采用“推”模式的坏处有:生产者已经“推”消息到“Kafka Cluster”,如果“Kafka Cluster”再“推”消息到消费者,那么消费者消费的速度得跟生产者生产的速度相匹配才行;如果采用“拉”模式,两个速度不匹配也没有关系,可以将积压的数据存储在Kafka Cluster中
2)采用“推”模式的坏处有:导致消息群聚机制失败,在Kafka Cluster上群聚一定数量的消息后,有可能超出消费者的消费能力,此时,该消息群聚机制是失败的;如果采用“拉”模式,消息群聚机制由消费者进行控制,可以更加灵活自由
1)当“Kafka Cluster”上没有消息时,采用“拉”模式,可能出现空等待。以上坏处的解决方案有:设计消费者的“拉”请求会被阻塞,直到有消息(或者一定数量的消息,即采用群聚机制)到达“Kafka Cluster”。
2、由“《Kafka 0.8.2 Documentation》----Getting Started”可知,某个主题内的一个分区只能跟进程组内的一个消费者进行绑定,由消费者维护该分区内下次待读取消息的位置指针而不由分区所在"broker"维护。由于该位置指针由消费者维护,因而消费者可以自由修改该值达到可以随机访问该分区内消息的效果。
六、消息传输一致性语义
Kafka提供3种消息传输一致性语义:最多1次,最少1次,恰好1次。最少1次:可能会重传数据,有可能出现数据被重复处理的情况;
最多1次:可能会出现数据丢失情况;
恰好1次:并不是指真正只传输1次,只不过有一个机制。确保不会出现“数据被重复处理”和“数据丢失”的情况。
默认采用的消息传输一致性语义是:最少1次。
生产者到"Kafka Cluster"的场景中可以采取以下方案来得到“恰好1次”的一致性语义:
最少1次+给每个消息赋予一个唯一的键值:由于该唯一键值的存在,不会再出现消息被重复处理的情况。
"Kafka Cluster"到消费者的场景中可以采取以下方案来得到“恰好1次”的一致性语义:
最少1次+消费者的输出中额外增加已处理消息最大编号:由于已处理消息最大编号的存在,不会出现重复处理消息的情况。
七、分区备份
在Kafka中,每个主题分为好几个分区,为了保证容错性,每个分区又有一些备份分区。为了进行区分,原有分区被称为“正分区”,用来备份的分区被称为“备份分区”。对于某个分区来说,保存正分区的"broker"为该分区的"leader",保存备份分区的"broker"为该分区的"follower"。备份分区会完全复制正分区的消息,包括消息的编号等附加属性值。为了保持正分区和备份分区的内容一致,Kafka采取的方案是在保存备份分区的"broker"上开启一个消费者进程进行消费,从而使得正分区的内容与备份分区的内容保持一致。一般情况下,一个分区有一个“正分区”和零到多个“备份分区”。可以配置“正分区+备份分区”的总数量,关于这个配置,不同主题可以有不同的配置值。注意,生产者,消费者只与保存正分区的"leader"进行通信。
对于某个分区,Kafka维护一个ISR集合,集合中是与该分区内容完全保持一致的备份分区(指针)的集合(并不是所有备份分区都要在ISR集合中)。当生产者向“正分区”写入消息时,只有当ISR中所有备份分区完成写入消息的同步之后,生产者才能得到“成功”的反馈信息。只有这种反馈“成功”的消息,消费者才可以进行消费。
ISR集合大小越大,容错性越好,但是生产者提交消息得到“成功”反馈的时延越大;越小,容错性越差,但是生产者提交消息得到“成功”反馈的时延越小。
为了均衡,尽量均匀选择"broker"成为某个分区的"leader"。
设置[1]request.required.acks=0,表示生产者不需要收到正分区和ISR中所有备份分区同步消息成功的信号就可以认为发布消息成功。
request.required.acks=1,表示生产者只有在收到正分区同步消息成功的信号之后才认为发布消息成功。
依此类推
request.required.acks=-1,表示生产者只有在收到正分区和ISR中所有备份分区同步消息成功的信号之后才认为发布消息成功。
八、消息保留策略
关于消息保留有3种策略:按照时间策略,按照空间策略和消息紧缩策略。按照时间策略是指:消息被保留一段时间;
按照空间策略是指:当分区的容量大小超过一定阈值时,将分区中旧的消息清空;
消息紧缩策略是指:关于同一个主键的多条消息,只保留最后一条消息即可。该策略非常适合于“消息表示修改操作记录”的场景,在该场景中,要得到某条数据的最后状态值,的确只需要相关联的最后一条消息即可。
每个主题可以有不同的消息保留策略,即消息保留策略的配置是以主题为单位的。
消息紧缩策略不能跟消息压缩技术合用。
一个应用可以包含多个消费者进程,也可以包含多个生产者进程。以应用为单位进行速度限制,有两个速度限制:produce(生产速度限制)和consume(消费速度限制)。应用下所包含的所有消费者被“消费速度限制值”限制,所包含的所有生产者被“生产速度限制值”限制。
生产速度限制值和消费速度限制值都以"broker"为单位进行配置,即应用与不同"broker"之间的生产速度限制值和消费速度限制值不一样。
除非在"/config/clients"中进行自定义配置,否则应用与所有"broker"之间的速度限制值采取默认值。
参考文献:
[1]https://kafka.apache.org/08/configuration.html