linux 系统调用epoll_create epoll_ctl epoll_wait
epoll是Linux内核为处理大批量句柄而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著减少程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
epoll主要涉及epoll_create epoll_ctl epoll_wait三个基本系统调用,及增加功能的epoll_create1,epoll_pwait
epoll相对poll/select比较:
1.poll/select每次调用都要将文件描述符及事件由用户空间复制到内核空间;epoll只需要在epoll_ctl中一次复制并保存在内核中
2.poll/select调用被阻塞时都会添加waiter到文件描述符表中所有文件的等待队列中,poll/select退出时再从等待队列中删除;epoll只需在epoll_ctl中将waiter添加到文件的等待队列中,直到显示被删除(close,epoll_ctl)
3.poll/select每次调用都会轮询文件描述符表中所有文件是否有事件发生;而epoll_wait只是从readylist链表中的取文件描述符及发生事件(有事件发生时内核调用epoll_ctl注册的回调函数将文件描述符及事件添加到readylist中),没有时阻塞epoll_wait
由以上3点可以看出epoll在大量并发连接且只有少量活跃时相对poll/select有相当大的性能优势
下面讨论epoll的实现,内核版本2.6.32.60
I.数据结构
i.eventpoll
epoll接口的主要数据结构
/* fs/eventpoll.c */
165 /*
166 * This structure is stored inside the "private_data" member of the file
167 * structure and rapresent the main data sructure for the eventpoll
168 * interface.
169 */
170 struct eventpoll {
171 /* Protect the this structure access */
172 spinlock_t lock;
173
174 /*
175 * This mutex is used to ensure that files are not removed
176 * while epoll is using them. This is held during the event
177 * collection loop, the file cleanup path, the epoll file exit
178 * code and the ctl operations.
179 */
180 struct mutex mtx;
181
182 /* Wait queue used by sys_epoll_wait() */
183 wait_queue_head_t wq;
184
185 /* Wait queue used by file->poll() */
186 wait_queue_head_t poll_wait;
187
188 /* List of ready file descriptors */
189 struct list_head rdllist;
190
191 /* RB tree root used to store monitored fd structs */
192 struct rb_root rbr;
193
194 /*
195 * This is a single linked list that chains all the "struct epitem" that
196 * happened while transfering ready events to userspace w/out
197 * holding ->lock.
198 */
199 struct epitem *ovflist;
200
201 /* The user that created the eventpoll descriptor */
202 struct user_struct *user;
203
204 struct file *file;
205
206 /* used to optimize loop detection check */
207 int visited;
208 struct list_head visited_list_link;
209 };
wq:用于记录epoll_wait系统调用的waiter
poll_wait:用于记录文件poll操作的waiter(由epoll_create创建的文件)
rdllist:已经ready的文件描述符链表
rbr:红黑树树根,用于文件描述符及事件的存储及快速查找
ovflist:文件描述符及事件由内核空间复制到用户空间时,期间出现的ready文件描述符及事件记录在该链表
ii.epitem
每个添加到eventpoll接口的文件都有对应的epitem,记录相应的事件信息等
129 /*
130 * Each file descriptor added to the eventpoll interface will
131 * have an entry of this type linked to the "rbr" RB tree.
132 */
133 struct epitem {
134 /* RB tree node used to link this structure to the eventpoll RB tree */
135 struct rb_node rbn;
136
137 /* List header used to link this structure to the eventpoll ready list */
138 struct list_head rdllink;
139
140 /*
141 * Works together "struct eventpoll"->ovflist in keeping the
142 * single linked chain of items.
143 */
144 struct epitem *next;
145
146 /* The file descriptor information this item refers to */
147 struct epoll_filefd ffd;
148
149 /* Number of active wait queue attached to poll operations */
150 int nwait;
151
152 /* List containing poll wait queues */
153 struct list_head pwqlist;
154
155 /* The "container" of this item */
156 struct eventpoll *ep;
157
158 /* List header used to link this item to the "struct file" items list */
159 struct list_head fllink;
160
161 /* The structure that describe the interested events and the source fd */
162 struct epoll_event event;
163 };
rbn:将epitem添加到eventpoll红黑树中
rdllink:将epitem添加到eventpoll就绪链表中
next:将epitem添加到ovflist链表中
ffd:表示添加到eventpoll的文件
nwait:wait queue大小
pwqlist:wait queue链表
ep:epitem所属的eventpoll
iii.eppoll_entry
211 /* Wait structure used by the poll hooks */
212 struct eppoll_entry {
213 /* List header used to link this structure to the "struct epitem" */
214 struct list_head llink;
215
216 /* The "base" pointer is set to the container "struct epitem" */
217 struct epitem *base;
218
219 /*
220 * Wait queue item that will be linked to the target file wait
221 * queue head.
222 */
223 wait_queue_t wait;
224
225 /* The wait queue head that linked the "wait" wait queue item */
226 wait_queue_head_t *whead;
227 };
llink:链入epitem的pwqlist
base:指向epitem
wait:链入目标文件的等待队列
whead:目标文件的等待等待队列
iv.数据结构关系图
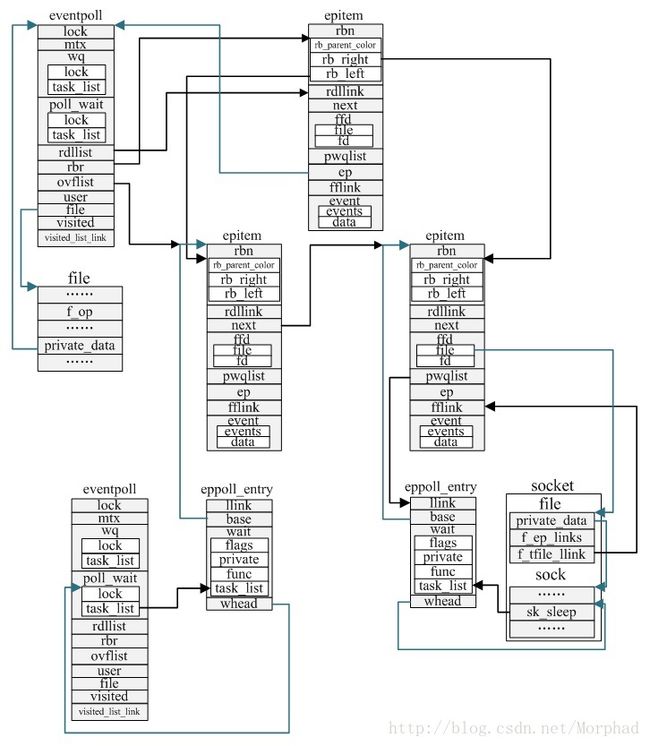
II.epoll_create
1456 /*
1457 * Open an eventpoll file descriptor.
1458 */
1459 SYSCALL_DEFINE1(epoll_create1, int, flags)
1460 {
1461 int error, fd;
1462 struct eventpoll *ep = NULL;
1463 struct file *file;
1464
1465 /* Check the EPOLL_* constant for consistency. */
1466 BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);
1467
1468 if (flags & ~EPOLL_CLOEXEC)
1469 return -EINVAL;
1470 /*
1471 * Create the internal data structure ("struct eventpoll").
1472 */
1473 error = ep_alloc(&ep);
1474 if (error < 0)
1475 return error;
1476 /*
1477 * Creates all the items needed to setup an eventpoll file. That is,
1478 * a file structure and a free file descriptor.
1479 */
1480 fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
1481 if (fd < 0) {
1482 error = fd;
1483 goto out_free_ep;
1484 }
1485 file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
1486 O_RDWR | (flags & O_CLOEXEC));
1487 if (IS_ERR(file)) {
1488 error = PTR_ERR(file);
1489 goto out_free_fd;
1490 }
1491 fd_install(fd, file);
1492 ep->file = file;
1493 return fd;
1494
1495 out_free_fd:
1496 put_unused_fd(fd);
1497 out_free_ep:
1498 ep_free(ep);
1499 return error;
1500 }
1501
1502 SYSCALL_DEFINE1(epoll_create, int, size)
1503 {
1504 if (size <= 0)
1505 return -EINVAL;
1506
1507 return sys_epoll_create1(0);
1508 }
1.参数检查,size/flags
2.分配eventpoll并初始化
3.分配eventpoll文件描述符
4.创建文件对象,操作是eventpoll_fops
5.文件对象与文件描述符关联
6.返回eventpoll文件描述符
由以上可以看出epoll_create中的size在该版本中没有用
i.ep_eventpoll_poll
ep_eventpoll_poll是eventpoll文件的poll操作,主要用于将wait添加到文件的等待队列中并返回POLL事件
686 static int ep_read_events_proc(struct eventpoll *ep, struct list_head *head,
687 void *priv)
688 {
689 struct epitem *epi, *tmp;
690
691 list_for_each_entry_safe(epi, tmp, head, rdllink) {
692 if (epi->ffd.file->f_op->poll(epi->ffd.file, NULL) &
693 epi->event.events)
694 return POLLIN | POLLRDNORM;
695 else {
696 /*
697 * Item has been dropped into the ready list by the poll
698 * callback, but it's not actually ready, as far as
699 * caller requested events goes. We can remove it here.
700 */
701 list_del_init(&epi->rdllink);
702 }
703 }
704
705 return 0;
706 }
707
708 static int ep_poll_readyevents_proc(void *priv, void *cookie, int call_nests)
709 {
710 return ep_scan_ready_list(priv, ep_read_events_proc, NULL, call_nests + 1);
711 }
712
713 static unsigned int ep_eventpoll_poll(struct file *file, poll_table *wait)
714 {
715 int pollflags;
716 struct eventpoll *ep = file->private_data;
717
718 /* Insert inside our poll wait queue */
719 poll_wait(file, &ep->poll_wait, wait);
720
721 /*
722 * Proceed to find out if wanted events are really available inside
723 * the ready list. This need to be done under ep_call_nested()
724 * supervision, since the call to f_op->poll() done on listed files
725 * could re-enter here.
726 */
727 pollflags = ep_call_nested(&poll_readywalk_ncalls, EP_MAX_NESTS,
728 ep_poll_readyevents_proc, ep, ep, current);
729
730 return pollflags != -1 ? pollflags : 0;
731 }
1.将wait添加到eventpoll结构poll_wait域表示的等待队列中;用于rdllist中有描述符时调用wait的回调者
2.根据eventpoll就绪链表中的文件是否满足POLL事件,返回eventpoll的自己的POLL事件;即如果注册到eventpoll接口中的文件满足POLL事件,则说明eventpoll自己是可以做POLLIN|POLLRDNORM相应的操作
ii.ep_eventpoll_release
631 static void ep_free(struct eventpoll *ep)
632 {
633 struct rb_node *rbp;
634 struct epitem *epi;
635
636 /* We need to release all tasks waiting for these file */
637 if (waitqueue_active(&ep->poll_wait))
638 ep_poll_safewake(&ep->poll_wait);
639
640 /*
641 * We need to lock this because we could be hit by
642 * eventpoll_release_file() while we're freeing the "struct eventpoll".
643 * We do not need to hold "ep->mtx" here because the epoll file
644 * is on the way to be removed and no one has references to it
645 * anymore. The only hit might come from eventpoll_release_file() but
646 * holding "epmutex" is sufficent here.
647 */
648 mutex_lock(&epmutex);
649
650 /*
651 * Walks through the whole tree by unregistering poll callbacks.
652 */
653 for (rbp = rb_first(&ep->rbr); rbp; rbp = rb_next(rbp)) {
654 epi = rb_entry(rbp, struct epitem, rbn);
655
656 ep_unregister_pollwait(ep, epi);
657 }
658
659 /*
660 * Walks through the whole tree by freeing each "struct epitem". At this
661 * point we are sure no poll callbacks will be lingering around, and also by
662 * holding "epmutex" we can be sure that no file cleanup code will hit
663 * us during this operation. So we can avoid the lock on "ep->lock".
664 */
665 while ((rbp = rb_first(&ep->rbr)) != NULL) {
666 epi = rb_entry(rbp, struct epitem, rbn);
667 ep_remove(ep, epi);
668 }
669
670 mutex_unlock(&epmutex);
671 mutex_destroy(&ep->mtx);
672 free_uid(ep->user);
673 kfree(ep);
674 }
675
676 static int ep_eventpoll_release(struct inode *inode, struct file *file)
677 {
678 struct eventpoll *ep = file->private_data;
679
680 if (ep)
681 ep_free(ep);
682
683 return 0;
684 }
关闭eventpoll文件描述符时VFS会触发ep_eventpoll_release,主要用于释放eventpoll相应的资源
1.唤醒poll_wait中的等待者
2.将注册到目标文件的poll回调函数,从目标文件的等待者队列删除
3.释放epitem
4.释放mutex锁
5.释放user
6.回收eventpoll结构所占用的内存
III.epoll_ctl
1510 /*
1511 * The following function implements the controller interface for
1512 * the eventpoll file that enables the insertion/removal/change of
1513 * file descriptors inside the interest set.
1514 */
1515 SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
1516 struct epoll_event __user *, event)
1517 {
1518 int error;
1519 int did_lock_epmutex = 0;
1520 struct file *file, *tfile;
1521 struct eventpoll *ep;
1522 struct epitem *epi;
1523 struct epoll_event epds;
1524
1525 error = -EFAULT;
1526 if (ep_op_has_event(op) &&
1527 copy_from_user(&epds, event, sizeof(struct epoll_event)))
1528 goto error_return;
1529
1530 /* Get the "struct file *" for the eventpoll file */
1531 error = -EBADF;
1532 file = fget(epfd);
1533 if (!file)
1534 goto error_return;
1535
1536 /* Get the "struct file *" for the target file */
1537 tfile = fget(fd);
1538 if (!tfile)
1539 goto error_fput;
1540
1541 /* The target file descriptor must support poll */
1542 error = -EPERM;
1543 if (!tfile->f_op || !tfile->f_op->poll)
1544 goto error_tgt_fput;
1545
1546 /*
1547 * We have to check that the file structure underneath the file descriptor
1548 * the user passed to us _is_ an eventpoll file. And also we do not permit
1549 * adding an epoll file descriptor inside itself.
1550 */
1551 error = -EINVAL;
1552 if (file == tfile || !is_file_epoll(file))
1553 goto error_tgt_fput;
1554
1555 /*
1556 * At this point it is safe to assume that the "private_data" contains
1557 * our own data structure.
1558 */
1559 ep = file->private_data;
1560
1561 /*
1562 * When we insert an epoll file descriptor, inside another epoll file
1563 * descriptor, there is the change of creating closed loops, which are
1564 * better be handled here, than in more critical paths. While we are
1565 * checking for loops we also determine the list of files reachable
1566 * and hang them on the tfile_check_list, so we can check that we
1567 * haven't created too many possible wakeup paths.
1568 *
1569 * We need to hold the epmutex across both ep_insert and ep_remove
1570 * b/c we want to make sure we are looking at a coherent view of
1571 * epoll network.
1572 */
1573 if (op == EPOLL_CTL_ADD || op == EPOLL_CTL_DEL) {
1574 mutex_lock(&epmutex);
1575 did_lock_epmutex = 1;
1576 }
1577 if (op == EPOLL_CTL_ADD) {
1578 if (is_file_epoll(tfile)) {
1579 error = -ELOOP;
1580 if (ep_loop_check(ep, tfile) != 0) {
1581 clear_tfile_check_list();
1582 goto error_tgt_fput;
1583 }
1584 } else
1585 list_add(&tfile->f_tfile_llink, &tfile_check_list);
1586 }
1587
1588 mutex_lock_nested(&ep->mtx, 0);
1589
1590 /*
1591 * Try to lookup the file inside our RB tree, Since we grabbed "mtx"
1592 * above, we can be sure to be able to use the item looked up by
1593 * ep_find() till we release the mutex.
1594 */
1595 epi = ep_find(ep, tfile, fd);
1596
1597 error = -EINVAL;
1598 switch (op) {
1599 case EPOLL_CTL_ADD:
1600 if (!epi) {
1601 epds.events |= POLLERR | POLLHUP;
1602 error = ep_insert(ep, &epds, tfile, fd);
1603 } else
1604 error = -EEXIST;
1605 clear_tfile_check_list();
1606 break;
1607 case EPOLL_CTL_DEL:
1608 if (epi)
1609 error = ep_remove(ep, epi);
1610 else
1611 error = -ENOENT;
1612 break;
1613 case EPOLL_CTL_MOD:
1614 if (epi) {
1615 epds.events |= POLLERR | POLLHUP;
1616 error = ep_modify(ep, epi, &epds);
1617 } else
1618 error = -ENOENT;
1619 break;
1620 }
1621 mutex_unlock(&ep->mtx);
1622
1623 error_tgt_fput:
1624 if (did_lock_epmutex)
1625 mutex_unlock(&epmutex);
1626
1627 fput(tfile);
1628 error_fput:
1629 fput(file);
1630 error_return:
1631
1632 return error;
1633 }
1.参数检查
2.根据目标文件对象及目标文件描述符查找epitem
3.根据op操作,添加epitem/删除epitem/修改eptime
i.ep_insert
1056 /*
1057 * Must be called with "mtx" held.
1058 */
1059 static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
1060 struct file *tfile, int fd)
1061 {
1062 int error, revents, pwake = 0;
1063 unsigned long flags;
1064 struct epitem *epi;
1065 struct ep_pqueue epq;
1066
1067 if (unlikely(atomic_read(&ep->user->epoll_watches) >=
1068 max_user_watches))
1069 return -ENOSPC;
1070 if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
1071 return -ENOMEM;
1072
1073 /* Item initialization follow here ... */
1074 INIT_LIST_HEAD(&epi->rdllink);
1075 INIT_LIST_HEAD(&epi->fllink);
1076 INIT_LIST_HEAD(&epi->pwqlist);
1077 epi->ep = ep;
1078 ep_set_ffd(&epi->ffd, tfile, fd);
1079 epi->event = *event;
1080 epi->nwait = 0;
1081 epi->next = EP_UNACTIVE_PTR;
1082
1083 /* Initialize the poll table using the queue callback */
1084 epq.epi = epi;
1085 init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
1086
1087 /*
1088 * Attach the item to the poll hooks and get current event bits.
1089 * We can safely use the file* here because its usage count has
1090 * been increased by the caller of this function. Note that after
1091 * this operation completes, the poll callback can start hitting
1092 * the new item.
1093 */
1094 revents = tfile->f_op->poll(tfile, &epq.pt);
1095
1096 /*
1097 * We have to check if something went wrong during the poll wait queue
1098 * install process. Namely an allocation for a wait queue failed due
1099 * high memory pressure.
1100 */
1101 error = -ENOMEM;
1102 if (epi->nwait < 0)
1103 goto error_unregister;
1104
1105 /* Add the current item to the list of active epoll hook for this file */
1106 spin_lock(&tfile->f_lock);
1107 list_add_tail(&epi->fllink, &tfile->f_ep_links);
1108 spin_unlock(&tfile->f_lock);
1109
1110 /*
1111 * Add the current item to the RB tree. All RB tree operations are
1112 * protected by "mtx", and ep_insert() is called with "mtx" held.
1113 */
1114 ep_rbtree_insert(ep, epi);
1115
1116 /* now check if we've created too many backpaths */
1117 error = -EINVAL;
1118 if (reverse_path_check())
1119 goto error_remove_epi;
1120
1121 /* We have to drop the new item inside our item list to keep track of it */
1122 spin_lock_irqsave(&ep->lock, flags);
1123
1124 /* If the file is already "ready" we drop it inside the ready list */
1125 if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
1126 list_add_tail(&epi->rdllink, &ep->rdllist);
1127
1128 /* Notify waiting tasks that events are available */
1129 if (waitqueue_active(&ep->wq))
1130 wake_up_locked(&ep->wq);
1131 if (waitqueue_active(&ep->poll_wait))
1132 pwake++;
1133 }
1134
1135 spin_unlock_irqrestore(&ep->lock, flags);
1136
1137 atomic_inc(&ep->user->epoll_watches);
1138
1139 /* We have to call this outside the lock */
1140 if (pwake)
1141 ep_poll_safewake(&ep->poll_wait);
1142
1143 return 0;
1144
1145 error_remove_epi:
1146 spin_lock(&tfile->f_lock);
1147 if (ep_is_linked(&epi->fllink))
1148 list_del_init(&epi->fllink);
1149 spin_unlock(&tfile->f_lock);
1150
1151 rb_erase(&epi->rbn, &ep->rbr);
1152
1153 error_unregister:
1154 ep_unregister_pollwait(ep, epi);
1155
1156 /*
1157 * We need to do this because an event could have been arrived on some
1158 * allocated wait queue. Note that we don't care about the ep->ovflist
1159 * list, since that is used/cleaned only inside a section bound by "mtx".
1160 * And ep_insert() is called with "mtx" held.
1161 */
1162 spin_lock_irqsave(&ep->lock, flags);
1163 if (ep_is_linked(&epi->rdllink))
1164 list_del_init(&epi->rdllink);
1165 spin_unlock_irqrestore(&ep->lock, flags);
1166
1167 kmem_cache_free(epi_cache, epi);
1168
1169 return error;
1170 }
1.分配epitem并根据目标文件初始化
2.初始化poll回调函数并添加到目标文件的等待队列中
3.将epitem链入目标文件的f_ep_links中
4.将epitem添加到eventpoll红黑树中
5.如果目标文件有相应的事件发生,则将epitem添加到eventpoll的就绪链表中,并唤醒等待进程epoll_wait/poll
917 /*
918 * This is the callback that is used to add our wait queue to the
919 * target file wakeup lists.
920 */
921 static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
922 poll_table *pt)
923 {
924 struct epitem *epi = ep_item_from_epqueue(pt);
925 struct eppoll_entry *pwq;
926
927 if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
928 init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
929 pwq->whead = whead;
930 pwq->base = epi;
931 add_wait_queue(whead, &pwq->wait);
932 list_add_tail(&pwq->llink, &epi->pwqlist);
933 epi->nwait++;
934 } else {
935 /* We have to signal that an error occurred */
936 epi->nwait = -1;
937 }
938 }
1.分配eppoll_entry
2.初始化等待者回调函数为ep_poll_callback,并添加到目标文件的等待队列中
2.建立eppoll_entry与epitem的关联
837 /*
838 * This is the callback that is passed to the wait queue wakeup
839 * machanism. It is called by the stored file descriptors when they
840 * have events to report.
841 */
842 static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
843 {
844 int pwake = 0;
845 unsigned long flags;
846 struct epitem *epi = ep_item_from_wait(wait);
847 struct eventpoll *ep = epi->ep;
848
849 if ((unsigned long)key & POLLFREE) {
850 ep_pwq_from_wait(wait)->whead = NULL;
851 /*
852 * whead = NULL above can race with ep_remove_wait_queue()
853 * which can do another remove_wait_queue() after us, so we
854 * can't use __remove_wait_queue(). whead->lock is held by
855 * the caller.
856 */
857 list_del_init(&wait->task_list);
858 }
859
860 spin_lock_irqsave(&ep->lock, flags);
861
862 /*
863 * If the event mask does not contain any poll(2) event, we consider the
864 * descriptor to be disabled. This condition is likely the effect of the
865 * EPOLLONESHOT bit that disables the descriptor when an event is received,
866 * until the next EPOLL_CTL_MOD will be issued.
867 */
868 if (!(epi->event.events & ~EP_PRIVATE_BITS))
869 goto out_unlock;
870
871 /*
872 * Check the events coming with the callback. At this stage, not
873 * every device reports the events in the "key" parameter of the
874 * callback. We need to be able to handle both cases here, hence the
875 * test for "key" != NULL before the event match test.
876 */
877 if (key && !((unsigned long) key & epi->event.events))
878 goto out_unlock;
879
880 /*
881 * If we are trasfering events to userspace, we can hold no locks
882 * (because we're accessing user memory, and because of linux f_op->poll()
883 * semantics). All the events that happens during that period of time are
884 * chained in ep->ovflist and requeued later on.
885 */
886 if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
887 if (epi->next == EP_UNACTIVE_PTR) {
888 epi->next = ep->ovflist;
889 ep->ovflist = epi;
890 }
891 goto out_unlock;
892 }
893
894 /* If this file is already in the ready list we exit soon */
895 if (!ep_is_linked(&epi->rdllink))
896 list_add_tail(&epi->rdllink, &ep->rdllist);
897
898 /*
899 * Wake up ( if active ) both the eventpoll wait list and the ->poll()
900 * wait list.
901 */
902 if (waitqueue_active(&ep->wq))
903 wake_up_locked(&ep->wq);
904 if (waitqueue_active(&ep->poll_wait))
905 pwake++;
906
907 out_unlock:
908 spin_unlock_irqrestore(&ep->lock, flags);
909
910 /* We have to call this outside the lock */
911 if (pwake)
912 ep_poll_safewake(&ep->poll_wait);
913
914 return 1;
915 }
1.如果事件有POLLFREE,则将等待者从目标文件的等待队列中删除
2.如果事件只有EPOLLONESHOT | EPOLLET,则直接退出;主要用于EPOLLONESHOT时清空事件中的其它位
3.如果正在复制就绪链表中的文件描述符及事件到用户空间,且epitem不在ovflist链表中,则将epitem添加到ovflist链表中,并退出
4.如果epitem不在就绪链表中,将epitem添加到就绪链表中
5.唤醒等待队列
注:
ep_ptable_queue_proc是文件poll操作的回调函数
ep_poll_callback是有事件发生时唤醒等待队列的回调函数
ii.ep_remove
591 /*
592 * Removes a "struct epitem" from the eventpoll RB tree and deallocates
593 * all the associated resources. Must be called with "mtx" held.
594 */
595 static int ep_remove(struct eventpoll *ep, struct epitem *epi)
596 {
597 unsigned long flags;
598 struct file *file = epi->ffd.file;
599
600 /*
601 * Removes poll wait queue hooks. We _have_ to do this without holding
602 * the "ep->lock" otherwise a deadlock might occur. This because of the
603 * sequence of the lock acquisition. Here we do "ep->lock" then the wait
604 * queue head lock when unregistering the wait queue. The wakeup callback
605 * will run by holding the wait queue head lock and will call our callback
606 * that will try to get "ep->lock".
607 */
608 ep_unregister_pollwait(ep, epi);
609
610 /* Remove the current item from the list of epoll hooks */
611 spin_lock(&file->f_lock);
612 if (ep_is_linked(&epi->fllink))
613 list_del_init(&epi->fllink);
614 spin_unlock(&file->f_lock);
615
616 rb_erase(&epi->rbn, &ep->rbr);
617
618 spin_lock_irqsave(&ep->lock, flags);
619 if (ep_is_linked(&epi->rdllink))
620 list_del_init(&epi->rdllink);
621 spin_unlock_irqrestore(&ep->lock, flags);
622
623 /* At this point it is safe to free the eventpoll item */
624 kmem_cache_free(epi_cache, epi);
625
626 atomic_dec(&ep->user->epoll_watches);
627
628 return 0;
629 }
1.删除epitem的等待者
2.将epitem从目标文件的fllink链表中移除
3.将epitem从红黑树中移除
4.将epitem从就绪链表中移除
5.回收epitem的内存
6.归还epoll计数
iii.ep_modify
1172 /*
1173 * Modify the interest event mask by dropping an event if the new mask
1174 * has a match in the current file status. Must be called with "mtx" held.
1175 */
1176 static int ep_modify(struct eventpoll *ep, struct epitem *epi, struct epoll_event *event)
1177 {
1178 int pwake = 0;
1179 unsigned int revents;
1180
1181 /*
1182 * Set the new event interest mask before calling f_op->poll();
1183 * otherwise we might miss an event that happens between the
1184 * f_op->poll() call and the new event set registering.
1185 */
1186 epi->event.events = event->events;
1187 epi->event.data = event->data; /* protected by mtx */
1188
1189 /*
1190 * Get current event bits. We can safely use the file* here because
1191 * its usage count has been increased by the caller of this function.
1192 */
1193 revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL);
1194
1195 /*
1196 * If the item is "hot" and it is not registered inside the ready
1197 * list, push it inside.
1198 */
1199 if (revents & event->events) {
1200 spin_lock_irq(&ep->lock);
1201 if (!ep_is_linked(&epi->rdllink)) {
1202 list_add_tail(&epi->rdllink, &ep->rdllist);
1203
1204 /* Notify waiting tasks that events are available */
1205 if (waitqueue_active(&ep->wq))
1206 wake_up_locked(&ep->wq);
1207 if (waitqueue_active(&ep->poll_wait))
1208 pwake++;
1209 }
1210 spin_unlock_irq(&ep->lock);
1211 }
1212
1213 /* We have to call this outside the lock */
1214 if (pwake)
1215 ep_poll_safewake(&ep->poll_wait);
1216
1217 return 0;
1218 }
1.修改epitem中的事件及数据
2.查询目标文件的POLL事件
3.如果目标文件的POLL事件有我们关心的事件,且不在就绪链表中,则将epitem添加到就绪链表并唤醒等待者
IV.epoll_wait
1635 /*
1636 * Implement the event wait interface for the eventpoll file. It is the kernel
1637 * part of the user space epoll_wait(2).
1638 */
1639 SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
1640 int, maxevents, int, timeout)
1641 {
1642 int error;
1643 struct file *file;
1644 struct eventpoll *ep;
1645
1646 /* The maximum number of event must be greater than zero */
1647 if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
1648 return -EINVAL;
1649
1650 /* Verify that the area passed by the user is writeable */
1651 if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event))) {
1652 error = -EFAULT;
1653 goto error_return;
1654 }
1655
1656 /* Get the "struct file *" for the eventpoll file */
1657 error = -EBADF;
1658 file = fget(epfd);
1659 if (!file)
1660 goto error_return;
1661
1662 /*
1663 * We have to check that the file structure underneath the fd
1664 * the user passed to us _is_ an eventpoll file.
1665 */
1666 error = -EINVAL;
1667 if (!is_file_epoll(file))
1668 goto error_fput;
1669
1670 /*
1671 * At this point it is safe to assume that the "private_data" contains
1672 * our own data structure.
1673 */
1674 ep = file->private_data;
1675
1676 /* Time to fish for events ... */
1677 error = ep_poll(ep, events, maxevents, timeout);
1678
1679 error_fput:
1680 fput(file);
1681 error_return:
1682
1683 return error;
1684 }
1.参数检查
2.获取eventpoll
3.调用ep_poll
1290 static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
1291 int maxevents, long timeout)
1292 {
1293 int res, eavail;
1294 unsigned long flags;
1295 long jtimeout;
1296 wait_queue_t wait;
1297
1298 /*
1299 * Calculate the timeout by checking for the "infinite" value (-1)
1300 * and the overflow condition. The passed timeout is in milliseconds,
1301 * that why (t * HZ) / 1000.
1302 */
1303 jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
1304 MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
1305
1306 retry:
1307 spin_lock_irqsave(&ep->lock, flags);
1308
1309 res = 0;
1310 if (list_empty(&ep->rdllist)) {
1311 /*
1312 * We don't have any available event to return to the caller.
1313 * We need to sleep here, and we will be wake up by
1314 * ep_poll_callback() when events will become available.
1315 */
1316 init_waitqueue_entry(&wait, current);
1317 wait.flags |= WQ_FLAG_EXCLUSIVE;
1318 __add_wait_queue(&ep->wq, &wait);
1319
1320 for (;;) {
1321 /*
1322 * We don't want to sleep if the ep_poll_callback() sends us
1323 * a wakeup in between. That's why we set the task state
1324 * to TASK_INTERRUPTIBLE before doing the checks.
1325 */
1326 set_current_state(TASK_INTERRUPTIBLE);
1327 if (!list_empty(&ep->rdllist) || !jtimeout)
1328 break;
1329 if (signal_pending(current)) {
1330 res = -EINTR;
1331 break;
1332 }
1333
1334 spin_unlock_irqrestore(&ep->lock, flags);
1335 jtimeout = schedule_timeout(jtimeout);
1336 spin_lock_irqsave(&ep->lock, flags);
1337 }
1338 __remove_wait_queue(&ep->wq, &wait);
1339
1340 set_current_state(TASK_RUNNING);
1341 }
1342 /* Is it worth to try to dig for events ? */
1343 eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
1344
1345 spin_unlock_irqrestore(&ep->lock, flags);
1346
1347 /*
1348 * Try to transfer events to user space. In case we get 0 events and
1349 * there's still timeout left over, we go trying again in search of
1350 * more luck.
1351 */
1352 if (!res && eavail &&
1353 !(res = ep_send_events(ep, events, maxevents)) && jtimeout)
1354 goto retry;
1355
1356 return res;
1357 }
1.计算超时时间
2.如果就绪链表为空
A.将进程添加到epoll_wait等待队列中
B.阻塞epoll_wait,直到就绪链表非空或有信号需要处理
C.将进程从epoll_wait等待队列中移除,恢复进程的执行
3.如果就绪链表或ovflist链表非空,则将文件描述符及事件复制到用户空间的epoll_wait事件参数中
1220 static int ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
1221 void *priv)
1222 {
1223 struct ep_send_events_data *esed = priv;
1224 int eventcnt;
1225 unsigned int revents;
1226 struct epitem *epi;
1227 struct epoll_event __user *uevent;
1228
1229 /*
1230 * We can loop without lock because we are passed a task private list.
1231 * Items cannot vanish during the loop because ep_scan_ready_list() is
1232 * holding "mtx" during this call.
1233 */
1234 for (eventcnt = 0, uevent = esed->events;
1235 !list_empty(head) && eventcnt < esed->maxevents;) {
1236 epi = list_first_entry(head, struct epitem, rdllink);
1237
1238 list_del_init(&epi->rdllink);
1239
1240 revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL) &
1241 epi->event.events;
1242
1243 /*
1244 * If the event mask intersect the caller-requested one,
1245 * deliver the event to userspace. Again, ep_scan_ready_list()
1246 * is holding "mtx", so no operations coming from userspace
1247 * can change the item.
1248 */
1249 if (revents) {
1250 if (__put_user(revents, &uevent->events) ||
1251 __put_user(epi->event.data, &uevent->data)) {
1252 list_add(&epi->rdllink, head);
1253 return eventcnt ? eventcnt : -EFAULT;
1254 }
1255 eventcnt++;
1256 uevent++;
1257 if (epi->event.events & EPOLLONESHOT)
1258 epi->event.events &= EP_PRIVATE_BITS;
1259 else if (!(epi->event.events & EPOLLET)) {
1260 /*
1261 * If this file has been added with Level
1262 * Trigger mode, we need to insert back inside
1263 * the ready list, so that the next call to
1264 * epoll_wait() will check again the events
1265 * availability. At this point, noone can insert
1266 * into ep->rdllist besides us. The epoll_ctl()
1267 * callers are locked out by
1268 * ep_scan_ready_list() holding "mtx" and the
1269 * poll callback will queue them in ep->ovflist.
1270 */
1271 list_add_tail(&epi->rdllink, &ep->rdllist);
1272 }
1273 }
1274 }
1275
1276 return eventcnt;
1277 }
1278
1279 static int ep_send_events(struct eventpoll *ep,
1280 struct epoll_event __user *events, int maxevents)
1281 {
1282 struct ep_send_events_data esed;
1283
1284 esed.maxevents = maxevents;
1285 esed.events = events;
1286
1287 return ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0);
1288 }
1289
1.遍历就绪链表,并取出epitem
A.调用目标文件的poll操作,取出POLL事件;
B.如果目标文件的POLL事件与关心的POLL事件有交集,则将文件描述符及事件复制到用户空间的epoll_wait事件参数中
C.如果事件是EPOLLONESHOT的,则清除关心POLL事件位;如果事件是非边沿触发,即水平触发,则将epitem重新放回到就绪链表中,不再就绪的epitem会在下次epoll_wait时移除
2.直到就绪链表为空或事件已经到达最大值
3.返回事件数
V.epoll_pwait
epoll_pwait是在epoll_wait之上添加了信号屏蔽功能
1688 /*
1689 * Implement the event wait interface for the eventpoll file. It is the kernel
1690 * part of the user space epoll_pwait(2).
1691 */
1692 SYSCALL_DEFINE6(epoll_pwait, int, epfd, struct epoll_event __user *, events,
1693 int, maxevents, int, timeout, const sigset_t __user *, sigmask,
1694 size_t, sigsetsize)
1695 {
1696 int error;
1697 sigset_t ksigmask, sigsaved;
1698
1699 /*
1700 * If the caller wants a certain signal mask to be set during the wait,
1701 * we apply it here.
1702 */
1703 if (sigmask) {
1704 if (sigsetsize != sizeof(sigset_t))
1705 return -EINVAL;
1706 if (copy_from_user(&ksigmask, sigmask, sizeof(ksigmask)))
1707 return -EFAULT;
1708 sigdelsetmask(&ksigmask, sigmask(SIGKILL) | sigmask(SIGSTOP));
1709 sigprocmask(SIG_SETMASK, &ksigmask, &sigsaved);
1710 }
1711
1712 error = sys_epoll_wait(epfd, events, maxevents, timeout);
1713
1714 /*
1715 * If we changed the signal mask, we need to restore the original one.
1716 * In case we've got a signal while waiting, we do not restore the
1717 * signal mask yet, and we allow do_signal() to deliver the signal on
1718 * the way back to userspace, before the signal mask is restored.
1719 */
1720 if (sigmask) {
1721 if (error == -EINTR) {
1722 memcpy(¤t->saved_sigmask, &sigsaved,
1723 sizeof(sigsaved));
1724 set_restore_sigmask();
1725 } else
1726 sigprocmask(SIG_SETMASK, &sigsaved, NULL);
1727 }
1728
1729 return error;
1730 }
1.如果有屏蔽信号,则将屏蔽信号掩码复制到内核空间;由于SIGKILL/SIGSTOP是不可屏蔽的,将它们从掩码中移除;设置信号阻塞掩码,并保存现有的信号阻塞掩码
2.调用epoll_wait
3.恢复信号阻塞掩码