Kafka is a messaging system. That’s it. So why all the hype? In realitymessaging is a hugely important piece of infrastructure for moving data betweensystems. To see why, let’s look at a data pipeline without a messaging system.
This system starts with Hadoop for storage and data processing. Hadoop isn’tvery useful without data so the first stage in using Hadoop is getting data in.
So far, not a big deal. Unfortunately, in the real world data exists on manysystems in parallel, all of which need to interact with Hadoop and with eachother. The situation quickly becomes more complex, ending with a system wheremultiple data systems are talking to one another over many channels. Each ofthese channels requires their own custom protocols and communication methods andmoving data between these systems becomes a full-time job for a team ofdevelopers.

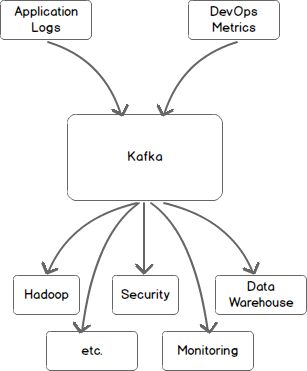
Let’s look at this picture again, using Kafka as a central messaging bus. Allincoming data is first placed in Kafka and all outgoing data is read from Kafka.Kafka centralizes communication between producers of data and consumers of thatdata.
What is Kafka?
Kafka is publish-subscribe messaging rethought as a distributed commit log.
Kafka Documentation http://kafka.apache.org/
Kafka is a distributed messaging system providing fast, highly scalable andredundant messaging through a pub-sub model. Kafka’s distributed design gives itseveral advantages. First, Kafka allows a large number of permanent or ad-hocconsumers. Second, Kafka is highly available and resilient to node failures andsupports automatic recovery. In real world data systems, these characteristicsmake Kafka an ideal fit for communication and integration between components oflarge scale data systems.
Kafka Terminology
The basic architecture of Kafka is organized around a few key terms: topics,producers, consumers, and brokers.
All Kafka messages are organized into topics. If you wish to send a messageyou send it to a specific topic and if you wish to read a message you read itfrom a specific topic. A consumer of topics pulls messages off of a Kafkatopic while producers push messages into a Kafka topic. Lastly, Kafka, as adistributed system, runs in a cluster. Each node in the cluster is called aKafka broker.
Anatomy of a Kafka Topic
Kafka topics are divided into a number of partitions. Partitions allow you toparallelize a topic by splitting the data in a particular topic across multiplebrokers — each partition can be placed on a separate machine to allow formultiple consumers to read from a topic in parallel. Consumers can also beparallelized so that multiple consumers can read from multiple partitions in atopic allowing for very high message processing throughput.
Each message within a partition has an identifier called its offset. Theoffset the ordering of messages as an immutable sequence. Kafka maintains thismessage ordering for you. Consumers can read messages starting from a specificoffset and are allowed to read from any offset point they choose, allowingconsumers to join the cluster at any point in time they see fit. Given theseconstraints, each specific message in a Kafka cluster can be uniquely identifiedby a tuple consisting of the message’s topic, partition, and offset within thepartition.
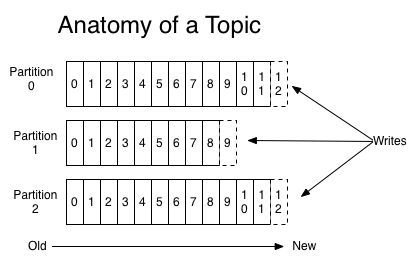
Another way to view a partition is as a log. A data source writes messages tothe log and one or more consumers reads from the log at the point in time theychoose. In the diagram below a data source is writing to the log and consumers Aand B are reading from the log at different offsets.

Kafka retains messages for a configurable period of time and it is up to theconsumers to adjust their behaviour accordingly. For instance, if Kafka isconfigured to keep messages for a day and a consumer is down for a period oflonger than a day, the consumer will lose messages. However, if the consumer isdown for an hour it can begin to read messages again starting from its lastknown offset. From the point of view of Kafka, it keeps no state on what theconsumers are reading from a topic.
Partitions and Brokers
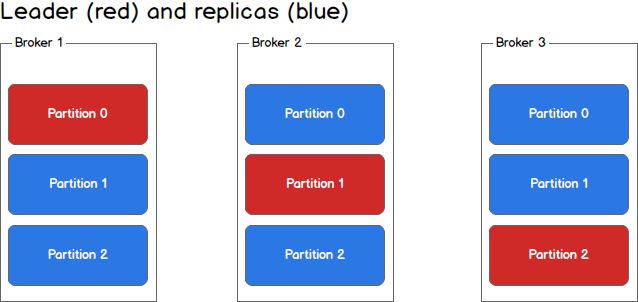
Each broker holds a number of partitions and each of these partitions can beeither a leader or a replica for a topic. All writes and reads to a topic gothrough the leader and the leader coordinates updating replicas with new data.If a leader fails, a replica takes over as the new leader.
Producers
Producers write to a single leader, this provides a means of load balancingproduction so that each write can be serviced by a separate broker and machine.In the first image, the producer is writing to partition 0 of the topic andpartition 0 replicates that write to the available replicas.
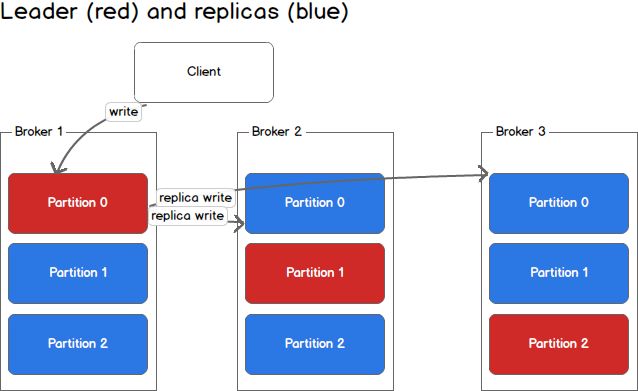
In the second image, the producer is writing to partition 1 of the topic andpartition 1 replicates that write to the available replicas.

Since each machine is responsible for each write, throughput of the system as awhole is increased.
Consumers and Consumer Groups
Consumers read from any single partition, allowing you to scale throughput ofmessage consumption in a similar fashion to message production. Consumers canalso be organized into consumer groups for a given topic — each consumer withinthe group reads from a unique partition and the group as a whole consumes allmessages from the entire topic. Typically, you structure your Kafka cluster tohave the same number of consumers as the number of partitions in your topics.If you have more consumers than partitions then some consumers will be idlebecause they have no partitions to read from. If you have more partitions thanconsumers then consumers will receive messages from multiple partitions. If youhave equal numbers of consumers and partitions you maximize efficiency.
The following picture from the Kafkadocumentation describes thesituation with multiple partitions of a single topic. Server 1 holds partitions 0and 3 and server 3 holds partitions 1 and 2. We have two consumer groups, A andB. A is made up of two consumers and B is made up of four consumers. ConsumerGroup A has two consumers of four partitions — each consumer reads from twopartitions. Consumer Group B, on the other hand, has the same number ofconsumers as partitions and each consumer reads from exactly one partition.
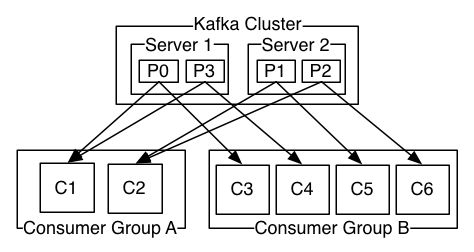
Consistency and Availability
Before beginning the discussion on consistency and availability, keep in mindthat these guarantees hold as long as you are producing to one partition andconsuming from one partition. All guarantees are off if you are reading fromthe same partition using two consumers or writing to the same partition usingtwo producers.
Kafka makes the following guarantees about data consistency and availability:(1) Messages sent to a topic partition will be appended to the commit log inthe order they are sent, (2) a single consumer instance will see messages in theorder they appear in the log, (3) a message is ‘committed’ when all in syncreplicas have applied it to their log, and (4) any committed message will not belost, as long as at least one in sync replica is alive.
The first and second guarantee ensure that message ordering is preserved foreach partition. Note that message ordering for the entire topic is notguaranteed. The third and fourth guarantee ensure that committed messages can beretrieved. In Kafka, the partition that is elected the leader is responsible forsyncing any messages received to replicas. Once a replica has acknowledged themessage, that replica is considered to be in sync. To understand this further,lets take a closer look at what happens during a write.
Handling Writes
When communicating with a Kafka cluster, all messages are sent to thepartition’s leader. The leader is responsible for writing the message to its ownin sync replica and, once that message has been committed, is responsible forpropagating the message to additional replicas on different brokers. Each replicaacknowledges that they have received the message and can now be called in sync.

When every broker in the cluster is available, consumers and producers canhappily read and write from the leading partition of a topic without issue.Unfortunately, either leaders or replicas may fail and we need to handle each ofthese situations.
Handling Failure
What happens when a replica fails? Writes will no longer reach the failedreplica and it will no longer receive messages, falling further and further outof sync with the leader. In the image below, Replica 3 is no longer receivingmessages from the leader.
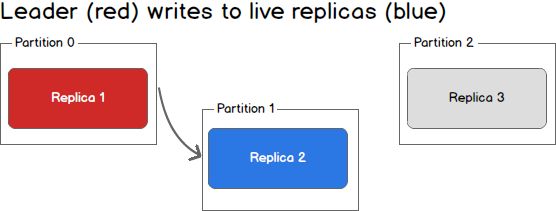
What happens when a second replica fails? The second replica will also nolonger receive messages and it too becomes out of sync with the leader.

At this point in time, only the leader is in sync. In Kafka terminology we stillhave one in sync replica even though that replica happens to be the leader forthis partition.
What happens if the leader dies? We are left with three dead replicas.
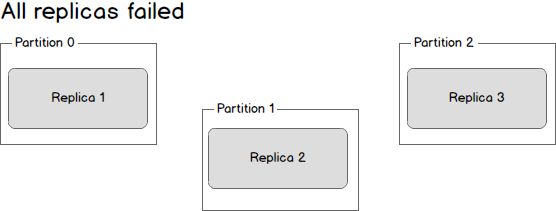
Replica one is actually still in sync — it cannot receive any new data but it isin sync with everything that was possible to receive. Replica two is missingsome data, and replica three (the first to go down) is missing even more data.Given this state, there are two possible solutions. The first, and simplest,scenario is to wait until the leader is back up before continuing. Oncethe leader is back up it will begin receiving and writing messages and asthe replicas are brought back online they will be made in sync with theleader. The second scenario is to elect the first broker to come back up asthe new leader. This broker will be out of sync with the existing leader andall data written between the time where this broker went down and when itwas elected the new leader will be lost. As additional brokers come back up,they will see that they have committed messages that do not exist on thenew leader and drop those messages. By electing a new leader as soon aspossible messages may be dropped but we will minimized downtime as any newmachine can be leader.
Taking a step back, we can view a scenario where the leader goes down while insync replicas still exist.
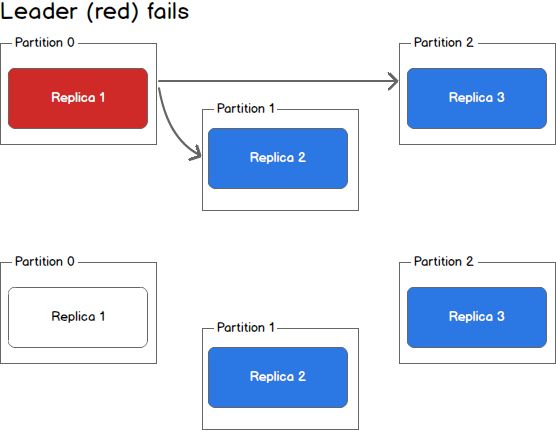
In this case, the Kafka controller will detect the loss of the leader andelect a new leader from the pool of in sync replicas. This may take a fewseconds and result in LeaderNotAvailable errors from the client. However, nodata loss will occur as long as producers and consumers handle this possibilityand retry appropriately.
Consistency as a Kafka Client
Kafka clients come in two flavours: producer and consumer. Each of these can beconfigured to different levels of consistency.
For a producer we have three choices. On each message we can (1) wait for all insync replicas to acknowledge the message, (2) wait for only the leader toacknowledge the message, or (3) do not wait for acknowledgement. Each of thesemethods have their merits and drawbacks and it is up to the system implementerto decide on the appropriate strategy for their system based on factors likeconsistency and throughput.
On the consumer side, we can only ever read committed messages (i.e., those that havebeen written to all in sync replicas). Given that, we have three methods ofproviding consistency as a consumer: (1) receive each message at most once, (2)receive each message at least once, or (3) receive each message exactlyonce. Each of these scenarios deserves a discussion of its own.
For at most once message delivery, the consumer reads data from a partition,commits the offset that it has read, and then processes the message. If theconsumer crashes between committing the offset and processing the message itwill restart from the next offset without ever having processed the message.This would lead to potentially undesirable message loss.
A better alternative is at least once message delivery. For at least oncedelivery, the consumer reads data from a partition, processes the message, andthen commits the offset of the message it has processed. In this case, theconsumer could crash between processing the message and committing the offsetand when the consumer restarts it will process the message again. This leads toduplicate messages in downstream systems but no data loss.
Exactly once delivery is guaranteed by having the consumer process a message andcommit the output of the message along with the offset to a transactional system.If the consumer crashes it can re-read the last transaction committed and resumeprocessing from there. This leads to no data loss and no data duplication. Inpractice however, exactly once delivery implies significantly decreasing thethroughput of the system as each message and offset is committed as atransaction.
In practice most Kafka consumer applications choose at least once deliverybecause it offers the best trade-off between throughput and correctness. Itwould be up to downstream systems to handle duplicate messages in their own way.
Conclusion
Kafka is quickly becoming the backbone of many organization’s data pipelines —and with good reason. By using Kafka as a message bus we achieve a high level ofparallelism and decoupling between data producers and data consumers, making ourarchitecture more flexible and adaptable to change. This article provides abirds eye view of Kafka architecture. From here, consult the Kafkadocumentation. Enjoy learning Kafkaand putting this tool to more use!