视频编解码器
视频信号由一系列单独的帧组成。每一帧可以单独地用上面描述的图像编解码器压缩,这被称为帧内编码(Intra-frame Coding),每一帧在“内部”进行编码而没有参考其他的帧。
但是,消除视频序列中的时间冗余(连续视频帧中的相似性),可以达到更好的压缩效果。具体通过给图像编解码器增加一个“前后的帧”来实现,主要有以下两个功能:
1.预测:基于一个或多个先前传输的帧来建立对当前帧的预测。
2.补偿:从当前帧中减去预测帧来产生一个“残差帧”。
接着,用“图像编解码器”来处理残差帧。这个方法的关键是预测功能:如果预测是准确的,残差帧将包含很少的数据,因而可以用图像编解码器有效地压缩。为了解码帧,解码器必须“逆反”补偿过程,把预测加到解码的残差帧中去(重建),这就是帧间编码(Inter-frame Coding)。基于同其他帧的关系进行帧编码,也即利用视频帧内的相互关系编码。
下图是带预测的视频编解码器
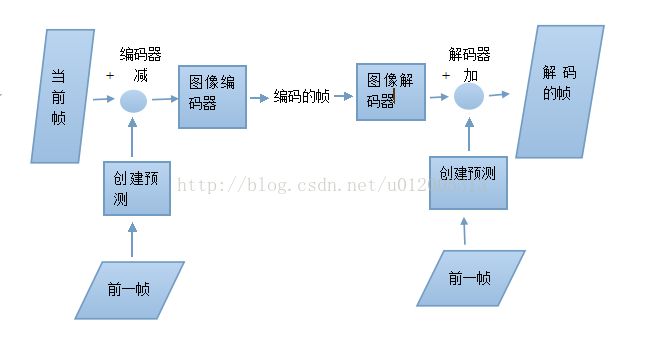
###########################################################################
帧间残差
最简单的预测器就是采用前一个传输的帧作参考。很明显,大部分的残差数据都是零,因而,不压缩当前帧而压缩残差帧可以提高压缩效率。
| 编码器输入 |
编码器预测 |
编码器输出/解码器输入 |
解码器预测 |
解码器输出 |
| 源帧1 |
零 |
压缩帧1 |
零 |
解码帧1 |
| 源帧2 |
源帧1 |
压缩残留帧2 |
解码帧1 |
解码帧2 |
| 源帧3 |
源帧2 |
压缩残留帧3 |
解码帧2 |
解码帧3 |
下面,举例说明解码器处理帧间预测可能存在的问题。上表表示了采用帧间残差编码和解码序列视频帧采用所需要的一系列操作。对第一帧,编码器和解码器没有用到预测。从第二帧开始出现困难:编码器用原始帧1作为一个预测并且编码残差结果,但是解码器只拥有解码出的帧1来形成预测。因为编码过程是有损的,解码出的帧1和原始帧1之间存在区别,这导致在解码器端对帧2的预测有一个小的误差。这个误差会随着每一个连续帧逐渐增加,然后编码器和解码器的预测会很快的“漂移”开来,导致解码质量的严重下降。
这个问题的解决方法是编码器采用解码的帧来形成预测。因而上面例子中的编码器解码(或重建)帧1来形成对帧2的预测。编码器和解码器采用相同的预测,漂移就可以减少或消除。
下图显示了一个完整的编码器,为了重建它的预测参考帧,它包含了一个解码的“环”。重建帧(或参考帧)在编码器和解码器中被存储,用于形成下一编码帧的预测。
带解码环的编码器
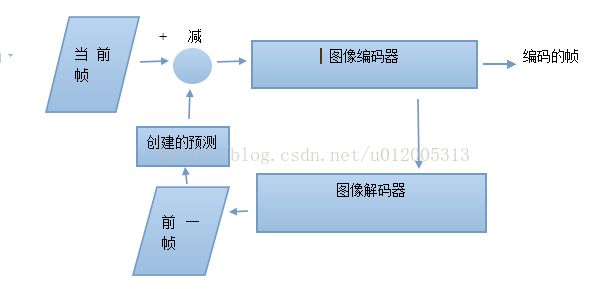
#####################################################################
运动补偿预测
当连续的帧很相近时,帧差比帧内编码具有更好的压缩效果,但是当先前帧与当前帧差别很大时,效果并不好。这样的差别通常取决于视频场景中的运动,通过运动估计和运动补偿,可以实现更好的预测。
下图显示了一个采用运动补偿预测的视频编解码器。在编码器中必须增加两个新的步骤:
带运动估计和补偿的视频编解码器

1.运动估计。把当前帧中的区域(通常是一个亮度样本的方块)和前一个重建帧中的相邻区域进行比较。运动估计器试图发现“最佳匹配”(best match),也就是说参考帧中相邻的具有最小的块。
2.运动补偿。从当前的区域或块中减去参考帧中的“匹配“区域或块(由运动估计器定义)。
解码器执行相同的运动补偿来重建当前帧,这意味着编码器必须给解码器传输”最佳“匹配块的位置(典型地采用一组运动矢量(motion vector)的形式)。
################################################################3
变换、量化和熵编码
对残差帧用分块或图像变换,并且量化和重新排序系数。和先前一样,编码run-level对(由于统计分布不同,因而编码表一般和帧内编码数据也不同)。如果采用运动补偿预测,运动向量信息必须附加在run-level数据中传送。运动向量一般采用和run-level数据类似的编码方法,也就是说,经常出现的运动向量用较短的码字编码,而不经常出现的向量用较长的码字编码。
################################################################3
解码
运动补偿解码器通常比相应的编码器更简单。解码器不需要运动估计功能(因为运动信息已经在编码的比特流传输了),并且它只包含一个解码过程(相比而言,编码器有编码和解码过程)。
####################################################################
小结
图像和视频序列的有效编码包括一个信源数据模型的建立,这个模型把信源数据转化为可以压缩的形式。
对运动视频压缩而言,第一步就是基于一个或更多的先前的帧建立一个被压缩帧的运动补偿预测。然后,这个模型和实际输入帧的差使用图像编解码器进行编码。数据被变换到另一个域(例如DCT或小波域),量化、重新排序并用熵编码器进行压缩。重建帧的过程是编码器上述步骤的逆过程。但是,量化不可逆,因此解码帧不是对原始帧的完全拷贝。
为了成功的交换压缩的图像和视频数据,解码器和编码器必须很清晰地采用一组兼容的算法,最重要的是压缩数据的语法和结构。
几十年来发展的标准一般都表述了一种语法(和一个解码过程)来支持视频和图像通信的广泛应用。