使用iozone和blogbench测试硬盘的读写性能,附带详细条目说明、图解测试报告和说明
今天架了个raid0,结果就想测试一下io性能了,因为系统是freebsd,所以考虑使用的io测试工具就是iozone和blogbench。
先看iozone:
命令:
./iozone -i 0 -i 1 -Rab ~/test-iozone.xls -g 4g -n 1M -C #-R表示创建excel报告,-a表示自动模式 -b表示指定excel报告文件的名字 # -i指定测试的内容如下:(0=write/rewrite, 1=read/re-read, 2=random-read/write,3=Read-backwards, 4=Re-write-record, 5=stride-read, 6=fwrite/re-fwrite, 7=fread/Re-fread, 8=random_mix, 9=pwrite/Re-pwrite, 10=pread/Re-pread,11=pwritev/Re-pwritev, 12=preadv/Re-preadv) # -g指定测试用的最大文件的大小 # -n指定测试用的最小文件的大小 # -C指定显示每个节点的吞吐量
其他详细的说明到处都是,这里我翻译一些测试内容的解释,从官方文档那里弄出来的:
- write:指测试创建并写入一个新文件,因为创建一个新文件不仅包括文件的数据,还要包括在文件系统上追踪到文件所在的额外开销信息,这类信息被成为metadata,通常包括目录信息,空间分配,以及其他的一些内容,因此这一项的性能会比rewrite的性能弱
- rewrite:测试写入一个已存在的文件的性能,由于不需要动那个metadata,所以,这项的性能比write会高
- read:测试读取一个已存在文件的速度
- reread:测试读取一个最近读取过的文件,由于操作系统会缓存,所以数值会比read高
- Random read:测试随机从一个文件中的不同位置的访问的性能,这项会被系统的catch,磁盘数量,访问延迟等因素影响
- Random write:同上,读换成写而已
- Random Mix:测试随机的从一个文件的不同位置进行读写操作,影响因素同上,这个测试只能在throughput模式下跑。每个线程/进程只会进行读取或者写入,而非同时读写。读写分布于进程间的轮转调度之中,所以这个操作需要多个线程/进程
- Backwards Read:测试逆序读取文件,这种方式常被程序使用,MSC Nastran是一个这种方式的范例,通常它的文件也是gb和tb级别的,虽然很多现有的操作系统优化了顺序读取文件的性能,但是很少有系统优化逆序读取文件的性能
- Record Rewrite:测试对文件的一个特定的“热点”进行写入和rewrite操作,热点是一个比较有趣的现象,当热点小到和cpu的数据缓存差不多的时候会异常的快。但是当大于cpu的数据缓存同时小于TLB的时候速度会在另一个数量级,这个现象在热点在操作系统缓存左右的时候也会有同样的现象出现。
- Strided Read:测试按照某种步进的方式读取文件的性能,比如读4k然后跳过200k再读4k再一直重复这种。这样的行为在文件保存了某些数据结构的时候是常见的。这个表现通常没有被操作系统优化,而且也常常是程序的性能瓶颈所在。
- fwrite:测试使用库函数fwrite()的写入性能,这个库函数是操作系统中常用的,而且使用在用户地址空间内的buffer。
- frewrit:类似上一个,区别同write和rewrite
- fread:
- freread:类似fwrite,区别同read和reread
除了上面的几项之外,还有一些特别的测试指标:
- mmap:许多操作系统支持使用mmap()把文件映射到用户的地址空间,这个映射让对该内存地址空间的操作直接反映在磁盘上。还有一些详细的区别,现在没空,改天翻译:
This is handy if an application wishes to treat files as chunks of memory. An example
would be to have an array in memory that is also being maintained as a file in the files system.
The semantics of mmap files is somewhat different than normal files. If a store to the memory location is
done then no actual file I/O may occur immediately. The use of the msyc() with the flags MS_SYNC, and
MS_ASYNC control the coherency of the memory and the file. A call to msync() with MS_SYNC will
force the contents of memory to the file and wait for it to be on storage before returning to the application.
A call to msync() with the flag MS_ASYNC tells the operating system to flush the memory out to storage
using an asynchronous mechanism so that the application may return into execution without waiting for the
data to be written to storage. - Async IO:大多数操作系统支持的另外一项读写机制就是POSIX的Async IO,使用POSIX的这个标准接口的函数就会进行这项操作。这项测试就是测试这个操作的性能的。
以下,是我在自己的一台Xeon3.2G(单核超线程,16K L1 Cache,2M L2 Cache)2G内存 2块140G的RAID0 FreeBSD 64bits的Dell 1850上的测试结果:
这台机器上,我从1M的文件测试到4G,超过了内存两倍,实际上,你可以很容易的看出这之间的差别。
这里我先说明一下这个图形的读法,我是用Matlab把iozone生成的excel报告处理成3维图形的结果,每幅图是一种测试,看标题就知道,由于很久没用matlab了,生成的时候有点小疏漏,横坐标代表两个参数,一个是record size,单位是KBytes,下图中凡是最大值是16K的就是record size的坐标轴了,16K也就是16M字节。而另外一个就是file size,即为测试用的文件大小,单位一律是MBytes,最大值是4K的就是filesize的坐标轴了,4K也就是4G大的文件。z轴坐标表示的就是对应的速度,这里是以KBytes/s为单位的。

由于这部分的测试没有什么特别重大的问题,所以我就把它放在了一起,我们大概的分析下。
写入测试的时候,当文件大于就32M的时候写入速度就开始急剧下降,而record的大小对速度也没有什么大的影响。这种下降可以认为,系统的缓存大概在32M到64M之间。这种直接写入的速度即时加上缓存也不过480M/s作用,而实际的写入速度在后面超出缓存甚至直到超出内存2倍的时候可以明显看出只有120M/s作用。
而在重写测试的时候,由于有了缓存的影响在1M的文件大小下,写入速度有了奇迹般的飞跃,大约是1.3G作用,这个具体的原因下面会分析。
同样的原理,缓存的作用在读取的时候更加的明显,最后甚至达到了4G/s的速度。
不过,这个测试中有一项让我目前还不明白的是,为何在文件超过2G的时候,读取速度令人诧异的跌到了40M/s的程度,要知道这个可是RAID0高速阵列啊。这个时候也会发现在文件在256M到1G的时候,record的大小对速度有了重大影响,当record大于512k的时候速度开始急跌,两者差别是100/60的程度。而写入速度倒没有出现这种程度的变化。所以,最终我们可以大致的判定这个RAID 0阵列的实际写入速度约为120MB/s,实际读取速度约为40M/s(待商榷)
然后下面是我在同一台机器上,换了freebsd 32bit 和RAID1的测试结果,为了展现出cpu cache的牛逼之处,所以我把文件的测试大小改为从4K到4G:

这幅图是直接写入的结果,数据上看,趋势是,当文件大小为64K,record大小为16K的时候速度从200MB/s急速的上升至400MB/s, 和上次测试一样,当文件大于32M的时候速度急速降至60M/s作用,由于是raid1,所以速度也就一半了。
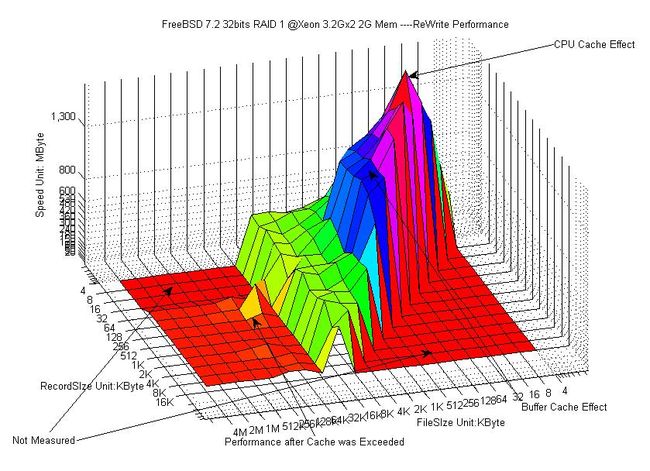
这个备受期待的ReWrite测试一定会让你开心的,注意我们CPU的L2 Cache大小,这里,同样的,当record大小和文件大小在16K到1M之间的时候,速度已神迹般的飙升,大约在1.2G/s到1.8G/s之间,而当文件大于2M之后,速度就急速回落到500MB/s左右了,同样的,超过32M的文件后速度就回落到60MB/s 左右了。

接下来又是令人兴奋的读取测试,直接读取的时候,速度峰值主要分布于256K到64M的文件之间,record大小在16K到512K之间,此时速度多在2.3GB/s以上,峰值最高的数值是3G/s。当文件大小和record大小超过这两个值的时候,速度就下跌了近50%。同样的,当文件大于128M后速度降至600MB/s,同样的,这里record大小对读取速度的影响也在1024这个位置显示出来,比值也是1000/600,最终读取速度约为25MB/s左右

最后的结果就是这个令人恐惧的ReRead测试了,速度峰值主要出现在64K到1M的文件和16K到512K的record大小之间,其中最恐怖的是128K到512K的文件和64K到512K的record大小,此时速度几乎都在4.3GB/s以上,峰值高达4.8GB/s,之后的表现和read类似。
最后我们可以估计,这个RAID1阵列的写入性能约为60M/s,读取性能约为20M/s左右(同样值得商榷)
结论:
从上面的测试,我们可以看出,实际上,每台服务器的io性能还是和它的CPU缓存以及内存和系统缓存大小有着密切的关联的。因对不同的服务用途,适当的修改系统的缓存还是可以把服务器优化到最佳的状态的。
另外一方面,也许我们也可以推翻一些人对于直接读取文件的偏爱,事实上,在这个系统上,频繁读写小于32K的文件反而速度慢得要死,且record的大小也对其有着强烈的影响,从测试上看,这个系统无论如何都不应该让record小于16K的文件频繁读写。事实上,从测试结果看,这套系统最优的频繁读写文件的区间应该为对64K到1M的文件以64K到512K的record大小进行读写。
当然,由于这里的测试仅仅只是对普通的读写性能进行的,而且又没有多次测量降低误差,所以对于日常应用来说,测试结果未必100%可取,但也在另一方面反应了一些情况:即,对于非存储服务器来说,增加高速整列对io性能的影响反而不如升级内存或者cpu的影响大。用数据来说的话,上面同一台机器,在RAID0和RAID1之间除了文件大于2G之后的IO性能的区别外,测试得到的结果几乎相近。当然,考虑到系统的稳定性的话,如此悬殊的IO速度差距,在断电的情况下也许真的可能造成文件系统的损失。
最后还是希望本文能起到抛砖引玉的效果,让你能够使用iozone来优化你的服务器。
延伸的思考:
这里有几个问题没有解决,第一,文件大小的测试数据是自动的从1G到2G到4G的,这之间是否有可能有其他的差别?第二,这个测试可能并没有达到读取它最合适的文件大小持续相当长的时间的程度。第三,这个阵列奇怪的实际读取性能究竟是什么原因导致的?
-------------------------------------------------------------------更新---------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------------------
使用iozone的测试就暂时到此为止了,实际上iozone还能够做到对nfs的详细测试以及对集群服务器的测试。
blogbench 给自己的定义是尝试重现真实的繁忙的文件服务器的负载来进行基准测试的工具,这个东西只打分数。
它会使用多线程对文件系统进行随机读写和重写操作来模仿真实的服务器运行情况,这个工具最初的设计是模仿skyblog.com的情况来搞的。所以有着这个怪名字
它的四种主要操作的说明如下:
- The writers. They create new blogs (directories) with a random amount of fake articles and fake pictures.
- The rewriters. They add or they modify articles and pictures of existing blogs.
- The “commenters”. They add fake comments to existing blogs in random order.
- The readers. They read articles, pictures and comments of random blogs. They sometimes even try to access non-existent files.
它使用PHP默认的8Kb大的写入缓存块大小和64Kb的读取缓存块大小来进行io操作,而并发写入和重新在没有优化过的机器上将会产生大量的破碎文件片段。这里我还是直接使用它来对上面来台机器进行测试,得出的结果也相当有意思。
64bit freebsd on raid 0 $ ./blogbench -d /home/me/testio -c 10 -i 10 -r 10 -w 10 -W 10 -s 10 Frequency = 10 secs Scratch dir = [/home/me/testio] Spawning 10 writers... Spawning 10 rewriters... Spawning 10 commenters... Spawning 10 readers... Benchmarking for 10 iterations. The test will run during 1 minutes. Nb blogs R articles W articles R pictures W pictures R comments W comments 54 8509 4423 6009 3673 4690 8432 92 9141 3839 6366 2728 4789 5150 121 6520 3331 4796 2415 4089 4941 153 5053 3163 3826 2367 4358 4458 180 6703 2868 4610 1979 2105 4520 208 5308 2803 3785 1885 2888 3820 230 5189 2849 3775 2103 2788 4323 251 6500 2374 4906 1780 3562 4168 276 6617 2807 4901 1791 4359 4055 297 5246 2641 3745 1832 3093 3695 Final score for writes: 297 Final score for reads : 1500 32bit freebsd on raid 1 [root@ /home/me/iotest/blogbench/bin]# ./blogbench -d /var/iotest -c 10 -i 10 -r 10 -w 10 -W 10 -s 10 Frequency = 10 secs Scratch dir = [/var/iotest] Spawning 10 writers... Spawning 10 rewriters... Spawning 10 commenters... Spawning 10 readers... Benchmarking for 10 iterations. The test will run during 1 minutes. Nb blogs R articles W articles R pictures W pictures R comments W comments 28 7292 2453 4186 1844 2684 4020 46 6837 2037 4269 1348 3263 2912 64 3034 1761 1868 1286 1833 2368 76 2712 1743 1822 1058 1271 2111 89 4967 1495 3409 1227 2155 2336 98 4642 1501 3627 897 2708 1922 115 3269 1725 2261 1277 1088 2130 125 2758 1453 1767 942 1337 2001 135 3791 1598 2701 951 1134 1844 144 3676 1163 2458 703 1711 1543 Final score for writes: 144 Final score for reads : 1062 FreeBSD 7.2 64bits RAID 0 @Xeon 3.2Gx2 2G Mem ----ReWrite Performance FileSIze Unit:MByte RecordSIze Unit:KByte Speed Unit: MByte
blogbench的测试结果又表明了0与1的阵列之间的性能差距。那么,以上两者看似的表面矛盾差别在哪里呢?也许在使用iozone进行全面的性能测试之后就会发现问题吧。
--------------------------------------------------------------12/1日更新---------------------------------------------------------------------
实际上,在此之后,我又使用iozone对包括这台服务器内的服务器进行了所有项目的测试,另外两台都是RAID5的阵列,
通过这些测试,我们发现的结果还是类似的:
- 对文件的读写最佳性能区始终集中在文件大小从64K到1M,而块大小从16K到cpu的L2 Cache的一半之间,不论是持续的还是随机读写都有此特点
- 使用fread的操作,当块超过cpu的L2 Cache的一半的时候,速度开始急速降低,fwrite也有类似的情况只是降低的速度较慢
- 对于超过内存一半以上的文件,使用record rewrite来处理能够始终保持高性能
- 另外,在本机的一个有10多块硬盘组的RAID5的整列上,整列以及4颗CPU带来的好处明显的体现在结果上了。在使用到了os cache部分的io性能比其他两台服务器有了将近2倍的。
---------------------------------------------------------------------------------------------------------------------------------------------