DirectX 9.0c游戏开发手记之RPG编程自学日志之3: Preparing for the Book (准备工作)(中)
本文由哈利_蜘蛛侠原创,转载请注明出处!有问题请联系[email protected]
上一期我们只讲了第一章的第3节。这次争取讲到第6节。为了方便,我把本书的各小节标题再次列在下面:
1、 DirectX
2、 SettingUp the Compiler (设置编译器)
3、 GeneralWindows Programming (一般的Windows编程)
4、 Understandingthe Program Flow (理解程序流)
5、 ModularProgramming
6、 Statesand Processes
7、 HandlingApplication Data (处理应用程序的数据)
8、 Buildingan Application Framework (构建一个应用程序框架)
9、Structuring a Project (结构化一个项目)
10、Wrapping UpPreparations (总结准备工作)
第4部分:Understanding the Program Flow (理解程序流)
下面仍旧是原文翻译部分:
---------------------------------------------------------------------------------------------------------------------------------
当沉浸在一个巨大的项目中时,我们要想不被各种各样的“家务活”累垮实在是太难了,这些家务活包括在增加、修改或者删除某项东西后进行的相应的代码修正。这些琐事占去了太多本可以用于我们的游戏开发的时间(一个字——不值当!)。
如果你一开始就对你所需要的东西了解得非常透彻的话,那么你就有能力组织你的程序的操作流(称为程序流,program flow)并且保证你可以轻松地进行修改。因为你已经谢了一个设计文档(你当然写了,难道不是吗?)(PS:此书的前一版在这之前花了很多的篇幅来介绍如何写一个RPG的设计文档。推荐去看一下。看来作者很懒,更新到第二版的时候原封不动地照抄……),因此剩下的没什么要做的了,只需要建立程序流的结构。
一个典型的(游戏)程序首先要初始化所有的系统和数据,然后进入主循环(main loop)。主循环是大多数事情发生的地方。依赖于正在发生的游戏状态(标题界面(title screen)、菜单界面(menu screen)、游戏内操作(in-game-play)等到),你需要用不同的方式来处理输入和输出。
下面列出的是你在一个标准的游戏应用程序中你需要遵循的步骤:
1、 初始化各个系统(Windows,图形,输入,声音等等)。
2、 准备数据(载入设置文件(configurationfiles))。
3、 安置默认的状态(configurethe default state)(一般来说是标题界面)。
4、 开始主循环。
5、 确定状态,然后通过获取输入、处理输入然后输出来进行处理。
6、 回到步骤5直到应用程序结束;那个时候转到步骤7。
7、 清理数据(释放内存资源等等)。
8、 释放系统(Windows,图形,输入等等)。
步骤1-3对于所有的游戏来说都是典型的:建立整个系统,载入必需的支持文件(图形,声音等等),并且准备好进行实际的游戏操作。你的应用程序会花费大多数时间来做游戏内处理(步骤5),而这一步骤可以分解为三部分:帧前处理(pre-frame processing)、每帧处理(per-frame processing)和帧后处理(post-frame processing)。
帧前处理处理的是小任务,例如取得当前的时间(对于基于时间的事件,例如同步(synching))以及其他的细节(例如更新游戏的元素)。每帧处理处理的是更新物体(如果没有在帧前阶段中搞定的话)以及渲染图形。而帧后处理处理的是剩下的功能,例如根据时间差进行同步,或者甚至显示已经渲染好的图形。
Here’s a kicker for you. (Sorry,不知道怎么翻译……。)在你的游戏中,你也许有多个每帧状态:一个用于操控主菜单,一个操控游戏内操作,等等。维护像那样的多个状态可能会导致一些混乱的代码,但是利用一种称为状态处理(state-processing)的机制可以在一定程度上减轻负担。你会在本章稍后的一节“应用程序状态”中学到更多关于状态处理的知识。
清除数据和关闭系统(步骤7和8)释放了系统以及你开始游戏时分配的资源。图形需要从内存中获得释放,应用程序窗口需要销毁,如此等等。跳过这些步骤是绝对地当然不行的,因为这回让你的系统处于一种奇怪的状态,并且可能会导致系统崩溃!
程序流中的每一个步骤都由一个相关的代码块来代表,所以那些代码块的结构越好,你的应用程序就越容易建立。为了帮助构建你的程序代码,你可以使用一种常用的编程技术,叫做modular programming.
---------------------------------------------------------------------------------------------------------------------------------
好啦,第4节翻译完成了。应该还不错吧?这一节的内容不多,也很容易理解,应该没什么问题了吧?那么好的,我们下面进入第5节的内容!
第5部分:Modular Programming
这个标题我不知道怎么翻译,暂时翻译成“模块化编程”。下面仍旧是原文翻译部分:
---------------------------------------------------------------------------------------------------------------------------------
Modular programming是现今的编程中使用的很多技术——包括C++和COM——的基础。Modular programming创建独立的代码组件,这些代码组件是完全自给自足的;它们不需要外部的帮助,并且在很多情况下,可以用在大多数操作平台上。
想象一个真正的modular programming系统,你用它编写的一个程序可以在所有的现存的电脑上运行!你也许不需要等很长时间——这样的事情已经快要来临了(或者已经来临了)。你可以将一个modular program看成一个C++类。它包含它自己的变量和函数。如果代码写得很合适,那么这个类不需要外部的帮助。
给定你的类,那么任何应用程序都可以利用这个类的特征,而这只需要知道如何调用这些函数(通过利用函数原型)。调用一个类的函数很简单,只需要实例化一个类,并且调用它的函数:
cClass MyClass; // Instance the class MyClass.Function1(); // Call a class function
为了得到真正的模块化功能(modularity),你的代码必须保护其数据。要做到这一点很容易,因为使用C++,你可以把变量标记为protected。为了获取到这些类变量的访问权,你必须写外部代码可以使用的public函数。这实际上是COM的基础。
瞧一瞧一些代码,它们说明了我正在谈论的东东。这里一个类包含一个计数器。你可以给这个计数器增值(increment)、设定它为某个特定值以及取得当前的计数器数值,这些都是通过使用如下的类:
class cCounter
{
private:
DWORD m_dwCount;
public:
cCounter() { m_dwCount = 0; }
BOOL Increment() { m_dwCount++; returnTRUE; }
BOOL Get(DWORD *Var) { *Var = m_dwCount;return TRUE; }
BOOL Set(DWORD Var) {m_dwCount = Var;return TRUE; }
};
cCounter类将变量m_dwCount设为私有的(private)。这样,即使是派生类都不能够访问它。其他的函数都可以顾名思义。唯一的值得注意的函数是Get,它以指向一个DWORD变量的指针为参数。这个函数将当前的计数器数值存储在那个变量里,并且返回TRUE(正如所有其他的cCounter类函数那样——当然,除了构造函数以外)。
刚才的那个是一个非常基本的modular programming的例子。一个更加复杂的例子是DirectX,它是完全地modular。如果你想仅仅使用DirectX的一个特征,比如说DirectSound,那么你只需要包含适当的DirectSound对象。DirectSound的运行并不依赖于其他的DirectX组件。
在整本书中,我一直在采用modular编码技术,尤其是为了创建一个游戏库核心,这些库彼此不依赖。每一个库都封装了一系列它自己专属的特征——图形库仅仅处理图形,输入库仅仅处理输入,等等。为了使用这些库,只需要在你的项目中包含它们,然后披荆斩棘前进吧!
---------------------------------------------------------------------------------------------------------------------------------
第6部分:States and Processes
下面仍旧是原文翻译部分:
---------------------------------------------------------------------------------------------------------------------------------
努力地优化你的程序流应该成为你从一开始就最优先考虑的事情之一。当应用程序代码比较小的时候,也许你还能够很容易地进行管理。然而,一旦该应用程序变得庞大起来,那么它就会变得越来越难处理了,甚至进行最小的改动都需要重写很多代码。
想想这种情景——你的游戏项目正在进行中,然后你决定在游戏中增加一个新的功能,亦即任何时候用户按下I键时,就会打开一个物品展示界面。这个物品展示界面只会在玩游戏的时候才会出现,而在主菜单界面的时候是不会出现的。这意味着你必须插入一些代码来完成以下的事情:检测什么时候用户按下了I键,并且当按下I键的时候,代码要渲染物品展示界面而不是正常的游戏画面。
如果你把自己限制在这样的思路——使用单独一个函数根据用户正在做什么(例如正在观察主菜单或者正在玩游戏)来渲染每一个显示界面——里的话,你很亏就会意识到渲染函数会变得超级庞大和复杂,因为它必须包括游戏能够处于的所有状态(states)。
1.6.1 应用程序状态
我刚才提到了状态了吗?那么好吧,啥叫状态呢?状态是操作状态(stateof operation)的简称,表示你的应用程序正在着手执行的过程(process)。你的游戏的主菜单是一个状态,而游戏中(in-game-play)状态也是一个状态。而你想在游戏中添加的物品展示也是一个状态。
当你把各种各样的状态添加进你的应用程序的时候,你需要提供一种方法来决定如何根据当前的操作状态(它会随着项目的执行而发生改变)来处理这些状态。在每一帧中决定你的应用程序需要处理哪个状态会导致如下所示的恐怖代码:
switch(CurrentState){
case STATE_TITLESCREEN:
DoTitleScreen();
break;
case STATE_MAINMENU:
DoMainMenu();
break;
case STATE_INGAME:
DoGameFrame();
break;
}
哎呦喂!你可以看出来像上面的那种方法是行不通的,尤其是当你的游戏有巨多的状态来处理时,并且如果你试图在每一帧中处理状态的话,情况还会更糟!相反,你可以使用一种我喜欢称之为state-based programming(基于状态的编程,简称SBP)的技术。本质上,SBP基于一个状态栈对程序的执行进行分流(引导)。(原文:Inessence, SBP branches (directs) execution based on a stack of states.)每一个状态代表一个对象或者一族函数。当你需要函数的时候,你可以把它们添加进这个栈里。当你用完这些函数的时候,将它们从栈中移除。你可以在下图中看到这一点。(觉得有点小问题:图中写的是First In和First Out,但是我觉得既然是stack,应该是Last In和First Out。)
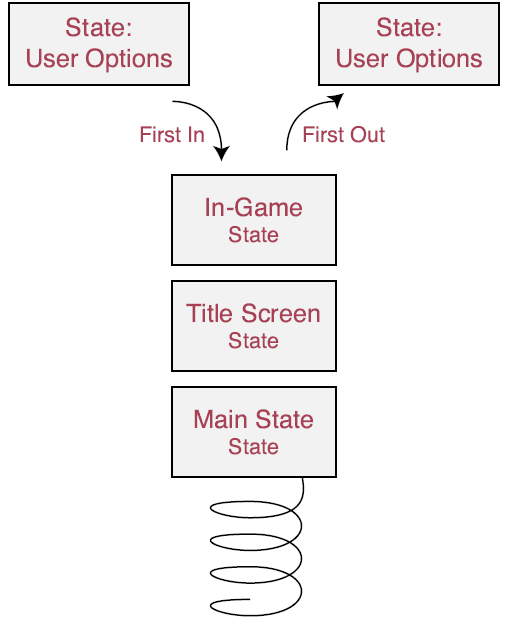
你通过使用一个状态管理器(state manager)来添加、移除以及处理状态。当一个状态被添加进来的时候,它被推进了这个栈,于是当状态管理器运作的时候就有了当前的控制权。一旦弹出来后(Once popped),最顶上的状态被丢弃,使得第二高的状态成为下一个被处理的状态。
由于上述原因,你需要实现一个状态管理器来接受指向函数(它们代表状态)的指针。将一个状态推到栈上(Pushing a state)就是将它的函数指针添加到栈上。调用这个处理栈上的最顶端的状态的状态管理器是你的事情,。状态管理器实际上非常容易实现,所以让我来给你展示一个状态管理器的例子:(下面用到了linked list的知识,学过数据结构的同学应该很熟悉的。)
class cStateManager
{
// A structure that stores a function pointer and linked list
typedef struct sState {
void (*Function)();
sState *Next;
} sState;
protected:
sState *m_StateParent; // The top state in the stack
// (the head of the stack)
public:
cStateManager() { m_StateParent = NULL; }
~cStateManager()
{
sState *StatePtr;
// Remove all states from the stack
while((StatePtr = m_StateParent) != NULL) {
m_StateParent = StatePtr->Next;
delete StatePtr;
}
}
// Push a function on to the stack
void Push(void (*Function)())
{
// Don't push a NULL value
if(Function != NULL) {
// Allocate a new state and push it on stack
sState *StatePtr = new sState;
StatePtr->Next = m_StateParent;
m_StateParent = StatePtr;
StatePtr->Function = Function;
}
}
BOOL Pop()
{
sState *StatePtr = m_StateParent;
// Remove the head of stack (if any)
if(StatePtr != NULL) {
m_StateParent = StatePtr->Next;
delete StatePtr;
}
// return TRUE if more states exist, FALSE otherwise
if(m_StateParent == NULL)
return FALSE;
return TRUE;
}
BOOL Process()
{
// return an error if no more states
if(m_StateParent == NULL)
return FALSE;
// Process the top-most state (if any)
m_StateParent->Function();
return TRUE;
}
};
你可以看到这个类很小,但是不要因此被愚弄了。有了cStateManager对象,你就可以持续地根据需要往里面添加状态,而在帧渲染函数中,你只需要调用Process函数,然后就可以确保正确的函数被调用了。这里是一个例子:
cStateManager SM;
// Macro to ease the use of MessageBox function
#define MB(s) MessageBox(NULL, s, s, MB_OK);
// State function prototypes - must follow this prototype!
void Func1() { MB("1"); g_StateManager.Pop(); }
void Func2() { MB("2"); g_StateManager.Pop(); }
void Func3() { MB("3"); g_StateManager.Pop(); }
int PASCAL WinMain(HINSTANCE hInst, HINSTANCE hPrev, \
LPSTR szCmdLine, int nCmdShow)
{
SM.Push(Func1);
SM.Push(Func2);
SM.Push(Func3);
while(SM.Process() == TRUE);
}
用前面的小程序,你可以跟踪三个状态,每一个状态显示一个带有数字的消息盒子。每一个状态将自己从栈中弹出,并且让下一个状态做好准备,直到最终所有的状态都已经用完,然后程序就退出了。非常简洁,对吧?
将前面的代码想象成是嵌入在每帧的消息泵(message pump)中的。比如说你需要给用户显示一个消息,但是,该死!你正在游戏中界面例程当中(you’re in the middle of the in-game screen routines)。没问题!只需要把消息显示函数放在栈上,然后在你下一次处理游戏的某一帧时调用处理函数就OK了!
1.6.2 Processes
继续前进,请允许我向你介绍另外一个简化每帧的函数调用的技术。如果你正在使用分离的组件来操控中间函数(medial functions)(称为processes),例如输入、网络和声音处理,那么你可以不单独地调用它们,而是可以创建一个对象来一次性操控它们的全部。
class cProcessManager
{
// A structure that stores a function pointer and linked list
typedef struct sProcess {
void (*Function)();
sProcess *Next;
} sProcess;
protected:
sProcess *m_ProcessParent; // The top state in the stack
// (the head of the stack)
public:
cProcessManager() { m_ProcessParent = NULL; }
~cProcessManager()
{
sProcess *ProcessPtr;
// Remove all processes from the stack
while((ProcessPtr = m_ProcessParent) != NULL) {
m_ProcessParent = ProcessPtr->Next;
delete ProcessPtr;
}
}
// Add function on to the stack
void Add(void (*Process)())
{
// Don't push a NULL value
if(Process != NULL) {
// Allocate a new process and push it on stack
sProcess *ProcessPtr = new sProcess;
ProcessPtr->Next = m_ProcessParent;
m_ProcessParent = ProcessPtr;
ProcessPtr->Function = Process;
}
}
// Process all functions
void Process()
{
sProcess *ProcessPtr = m_ProcessParent;
while(ProcessPtr != NULL) {
ProcessPtr->Function();
ProcessPtr = ProcessPtr->Next;
}
}
};
这个简单的对象很像之前的那个cStateManager对象,但是有一个大大的不同。这个cProcessManager对象仅仅增加process;它不会移除它们。这里有一个使用cProcessManager类的例子:
cProcessManager PM;
// Macro to ease the use of MessageBox function
#define MB(s) MessageBox(NULL, s, s, MB_OK);
// Processfunction prototypes - must follow this prototype!
void Func1() { MB("1"); }
void Func2() { MB("2"); }
void Func3() { MB("3"); }
int PASCAL WinMain(HINSTANCE hInst, HINSTANCE hPrev, \
LPSTR szCmdLine, int nCmdShow)
{
PM.Add(Func1);
PM.Add(Func2);
PM.Add(Func3);
PM.Process();
PM.Process();
}
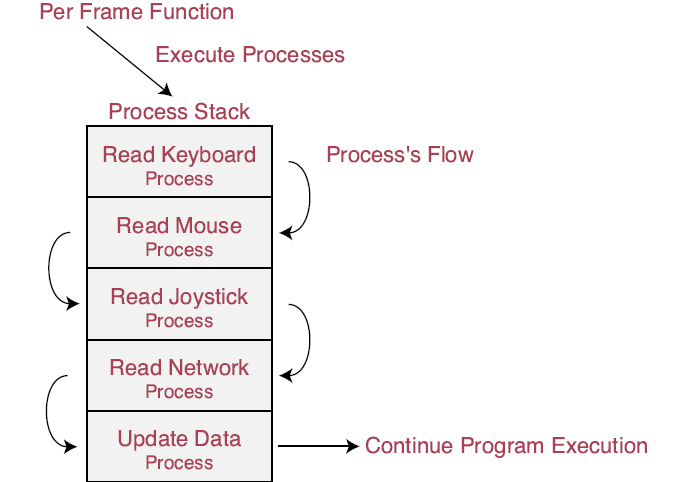
注意到每次Process函数被调用的时候,栈上的所有processes都被调用了(如下图所示)。这对于频繁地调用函数来说非常有用。你可以针对不同的情形设计不同的process manager——例如,一个操控输入和网络处理,而另一个操控输入和声音。
---------------------------------------------------------------------------------------------------------------------------------
好啦,这一期就到此结束啦!内容有点多啊,而且对于没有学过数据结构的同学来说可能有点难。那么大家就好好消化消化吧,咱们下期再见吧!
注意:前面的两个例子实际上是完整的代码,大家建立Win32项目类型的解决方案然后把代码放进去编译就OK了。注意在项目属性中要把字符集改变为Multi-byte类型,否则会出错。