html与xml解析库htmlcxx使用过程中的若干问题及解决方案
1:htmlcxx下载地址
https://github.com/dhoerl/htmlcxx
2:编译出错
下载后采用vs2010进行编译 出错
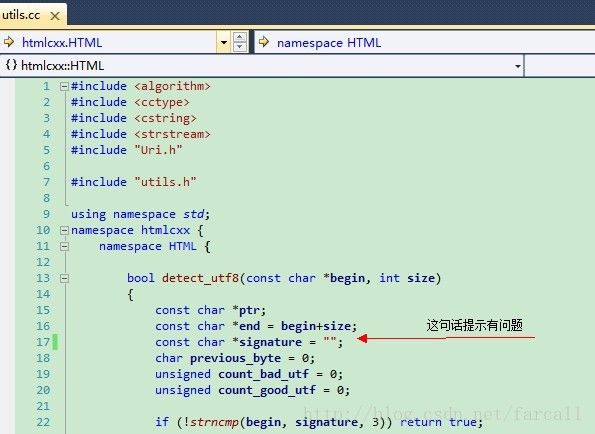
将const char*signature = 右边的""去掉 然后重新打一遍即可
问题3:处理中文报
htmlcxx 0.85的bug,断言_ASSERTE((unsigned)(c + 1) <= 256)错误
解决方案:
转载自http://blog.csdn.net/zhengfuzhe1124/article/details/19154861
方案2经测试可行
htmlcxx是一款很不错的解析html和css的开源库, 但是在解析存在中文的网页时却出现断言_ASSERTE((unsigned)(c + 1) <= 256), 比较烦人, 该问题是由于isspace函数判断非ascii字符是会出现该断言, isspace要求传入的参数必须是小于256的ascii, 而中文的ascii值是大于256的, 针对这一问题, 有两种解决方案.
方案1. 设置编译选项.
右键htmlcxx工程-->属性-->配置属性-->c/c++-->语言-->默认char为无符号选择(是/J).
重新编译该库, 使用时就不会报断言.
方案2. 修改源代码.
打开Node.cc文件,定位到第72,74,81行代码,修改如下:
//72行、 //while (isspace(*begin) && begin < end) ++begin; while ((!((unsigned)*begin > 255) && isspace(*begin)) && begin < end) ++begin; //74行、 //while (isspace(*trimmed_end) && trimmed_end >= begin) --trimmed_end; while ((!((unsigned)*trimmed_end > 255) && isspace(*trimmed_end)) && trimmed_end >= begin) --trimmed_end; //81行. //while (*end && ! isspace(*end) && *end != '>') end++; while (*end &&((unsigned)*end > 255 || !isspace(*end) ) && *end != '>') end++;
然后, 找到第28行,修改如下:
while (!isspace(*ptr))
{
if(*ptr == '>')
return;
++ptr;
}
再然后定位到PaserSax.tcc文件(文件在文件夹中找,vs2010工程上不显示), 找到SkiphtmlComment函数, 修改如下:
template <typename _Iterator>
_Iterator
htmlcxx::HTML::ParserSax::skipHtmlComment(_Iterator c, _Iterator end)
{
while ( c != end ) {
if (*c++ == '-' && c != end && *c == '-')
{
_Iterator d(c);
while (++c != end &&((unsigned)*c > 255 || !isspace(*c) ) && *c != '>');
if (c == end || *c++ == '>') break;
c = d;
}
}
return c;
}
搞定收工.
4:其他重要链接
C++ Html解析器-HtmlCxx用户手册和源代码解析
http://blog.csdn.net/ictextr9/article/details/6893085
另外html中使用的tree.h在解析的时候很重要 链接http://tree.phi-sci.com/documentation.html
5开发实例
1:返回某个节点的Html
tree<HTML::Node>::iterator it = dom.begin() //关于it的其他操作 //...... int nLen = it->length(); int noffset = it->offset(); string substr = str.substr(noffset,nLen);
//遍历it节点下的子节点
//遍历某个节点的子节点
tree<HTML::Node>::iterator it = dom.begin();
//某个节点解析前都要执行parseAttributes函数
it->parseAttributes();
//....对it节点的其他操作
//开始遍历it节点下的子节点
tree<HTML::Node>::iterator sib2=dom.begin(it);
tree<HTML::Node>::iterator end2=dom.end(it);
for (;sib2 != end2; ++sib2)
{
//很重要
sib2->parseAttributes();
//cout << sib2->text() << endl;
//将子节点下标签为a的节点输出
//<a href="29013-0.html">上一页</a>
if (sib2->isTag() && (_stricmp(sib2->tagName().c_str(), "a")== 0))
{
//cout << *sib2 << endl;
//cout << sib2->text() << endl;
cout <<"链接:" << sib2->attribute("href").second ; //29013-0.html
tree<HTML::Node>::iterator sib3=dom.begin(sib2);
sib3->parseAttributes();
cout <<"字段:"<<sib3->text().c_str() << endl;//上一页
}
}
//小结:
//htmlcxx中对结点的定义迥异于IE_Dom
//htmlcxx中的节点分为tag结点和无tag结点
//像<a href="29013-0.html">上一页</a>这种就会产生
//两个结点其中内容为"上一页"的节点是标签"a"结点的子节点
在htmlcxx库中很多的操作都要依靠tree和iter来完成
新问题
在测试某些页面的时候还是会出现((unsigned)(c + 1) <= 256)错误
如图
查看堆栈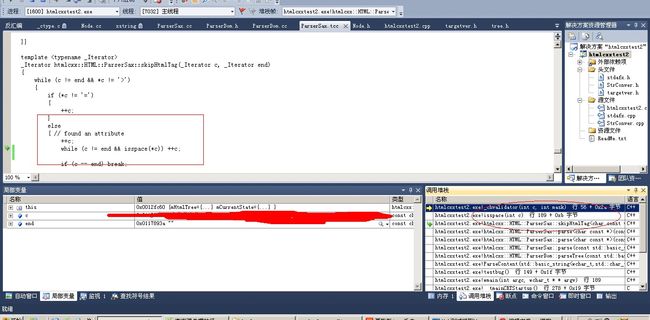
查看isspace函数源码
extern __inline int (__cdecl isspace) (
int c
)
{
if (__locale_changed == 0)
{
return __fast_ch_check(c, _SPACE);//跟到这里
}
else
{
return (_isspace_l)(c, NULL);
}
}
我搜索__fast_ch_check后发现如下文章 vc 2005 sp1下isspace函数对中文处理有问题
链接http://www.cppblog.com/luonjtu/archive/2009/03/13/76332.html
采用文章介绍的办法在工程中添加
//函数中添加
#if defined(WIN32) && defined(_DEBUG) setlocale( LC_ALL, ".OCP" ); #endif
调用isspace函数是逐个字节判断,但是isspace和_chvalidator接受的参数都是int,这样就会产生一个char到int的转型,在vc下,char默认是"signed char",这样char“b8”转型到int后,会变成一个负数,然后在assert的时候,又强制转型为unsigned,它又变成了一个非常巨大的正数,自然assert就失败了。
问题暂时解决