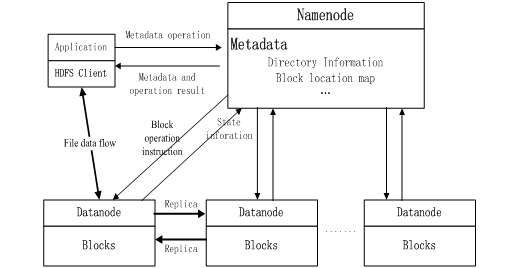
HDFS 的客户端进行读写操作都需要通过 NameNode。在读操作时,客户端需要连接 NameNode,获取数据块所在的 DataNode,再连接 DataNode 进行数据块的读取;在写操作时,客户端需要连接 NameNode,得到 NameNode 分配的数据写入位置后,连接相应的 DataNode 写入数据;在进行元数据操作时,客户端需要连接 NameNode 进行修改(如图 1)。在早前的 Hadoop 集群中,NameNode 只有一个,它是否正常运行,直接决定了整个 Hadoop 集群能否正常运转,进而会影响工作于 Hadoop 集群之上的 HBase、Hive、Pig 等服务的工作。 因此 NameNode 也就成为了系统的一个单一故障点,NameNode 的可用性关系到集群系统的可用性。如果 NameNode 的元信息由于故障损坏,更会导致整个分布式文件系统损坏。
图 1.HDFS 的架构及读写流程
HDFS 高可用性的种类以及优缺点
为了提高整个集群的可靠性与可维护性,各大公司与社区提出了许多改进 HDFS 的方案,主要有如下几种:
NameNode 多目录存储:通过配置 dfs.name.dir,可以將 NameNode 维护的元数据保存到多个目录,进而可以备份一份到远程的 NFS 目录,当 NameNode 故障或停机时,可以通过另外一台 NameNode 读取 NFS 目录中的备份进行恢复工作。不足之处在于写入 NFS 增加了系统开销,不利于 NameNode 高效工作;并且需要管理员手工进行操作。由于在恢复过程中存在一段系统不可用的时间,该方案只是一种备份方案,并不是真正意义上的 HA 方案。
Secondary NameNode:Secondary NameNode 通过定期下载 NameNode 的元数据和日志文件,并进行合并更新,来对 NameNode 进行备份。当 NameNode 故障时,可以通过 Secondary NameNode 进行恢复。不足之处在于 Secondary NameNode 的备份只是 NameNode 的 Checkpoint,并没有与 NameNode 实时同步,恢复后的数据存在一定的元信息丢失。由于在恢复过程中存在一段系统不可用的时间,该方案只是一种备份方案,并不是真正意义上的 HA 方案。
Checkpoint Node:与 Secondary NameNode 的原理基本相同,利用了 HDFS 的 Checkpoint 机制进行备份,通过一个 Checkpoint Node,定期从 Primary NameNode 中下载元数据信息进行合并,形成最新的 Checkpoint,并上传到 NameNode 进行更新不足之处在于 Checkpoint 的备份没有与 NameNode 实时同步,恢复后的数据存在一定的元信息丢失。由于在恢复过程中存在一段系统不可用的时间,该方案只是一种备份方案,并不是真正意义上的 HA 方案。
Backup Node:Backup Node 在内存和磁盘保存了 NameNode 最新的元数据。当 NameNode 发生故障,可用读取 Backup Node 中最新的元数据信息进行恢复。 该方案只是的不足在于当 NameNode 发生故障,目前还只能通过重启 NameNode 的方式来恢复服务,系统会出现一段不可用时间。
FaceBook 的 AvatarNode:存在两个 NameNode,分别为 Active Node 和 Standby Node,Active Node 对外提供服务。Standby Node 处于 Safe mode,在内存中保存 Active Node 最新的元数据信息。Active Node 和 Standby Node 通过共享的 NFS 进行交互,DataNode 同时向 Active Node 和 Standby Node 汇报数据块信息。当 Active Node 故障时,管理员通过一条命令进行切换,Standby Node 转换为 Active Node 后立刻就可以工作,大大减少了系统不可用的时间,是一种真正的 HA 方案。不足之处在于该方案最终没有被社区接受。
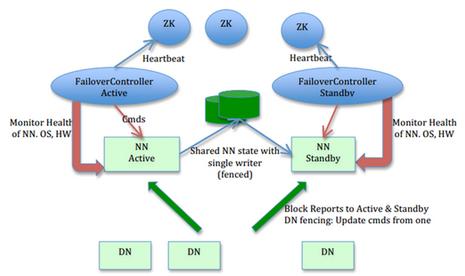
社区开发的 HDFS HA:与 AvatarNode 类似,存在 Active Node 和 Standby Node 两个 NameNode, 管理员通过一条命令进行切换。针对 Active Node 和 Standby Node 的共享日志,社区又提供三种解决方案:
- 两个 Node 共享 NAS 上的 NFS,是社区最初的解决方案,该方案需要专用存储设备,在使用上有一定限制。
- 基于 Bookkeeper 的日志存储方案,该方案主要依靠 Zookeeper 的子项目 Bookkeeper 实现日志的高可靠共享存储,该方案对 Zookeeper 依赖较大,配置比较复杂。
- 基于 QJM(Qurom Journal Manager)的共享日志方案。QJM 的基本原理就是用 2N+1 台 Journal Node 存储日志,每次写数据操作有大多数(W>=N+1)返回成功时,就认为该次写入日志成功。该方案独立性好,配置比较简单,是社区目前主推的方案。在手动切换的基础上,社区又开发了基于 Zookeeper 的 ZKFC(Zookeeper Failover Controller)自动切换解决方案,每个 Active Node 和 Standby Node 各有一个 ZKFC 进程监控 NameNode 的健康状况,当 Active Node 出现问题时,自动將 Standby Node 切换为 Active Node。
PLinux 对于 Hadoop 的支持
随着开源开发平台的迅猛发展,Linux 用户正面临着企业转型升级所带来的 IT 挑战。作为服务器领域创新的引领者,IBM 推出了"Project CAMP"。它通过将 VAD(增值分销商)合作伙伴的软件预装在 PowerLinux 服务器上,帮助用户降低 Power 平台的使用成本以及 PowerVM 虚拟化的技术门槛。
当前 IBM CAMP 服务器上安装 PLinux 操作系统,在 PLinux 上使用 IBM JDK1.6 或者 JDK1.7,开源 Hadoop 对其支持。本文将详细描述基于 PRedhat6.4,IBM JKD1.7 上配置 Hadoop HDFS 的 HA。
PLinux 系统上 Hadoop HDFS HA 的配置
PLinux 的环境准备
硬件信息列表:
| 主机 | 主机名 | 系统 ip 地址 1 | 配置 | 调整后 CPU | 硬盘 | |
| CAMP_1 | CAMP_1_vios | 10.10.10.23 | 8C/64G | 1C | 2*900 | |
| plinux9 | 10.10.10.24 | 3.5C | 2*900 | |||
| plinux10 | 10.10.10.25 | 3.5C | 2*900 | |||
| CAMP_2 | CAMP_2_vios | 10.10.10.26 | 8C/64G | 1C | 2*900 | |
| plinux11 | 10.10.10.27 | 3.5C | 2*900 | |||
| plinux12 | 10.10.10.28 | 3.5C | 2*900 | |||
两台 IBM CAMP 服务器,每台服务器上各有两个 PLinux 分区。
软件信息列表:
| 软件 | 版本号 |
|---|---|
| 操作系统 | Red Hat Enterprise Linux Server release 6.4 (Santiago) |
| Hadoop | Version 2.2.0 |
| Hbase | Version 0.96 |
| JAVA | ibm-java-sdk-7.0-4.2-ppc64-archive |
| ZooKeeper | Version 3.3.0 |
| Hive | Version 0.12 |
图 2 .Hadoop 开源组件结构图

本文使用了以上开源组件: Hadoop、HBase、Hive 以及 ZooKeeper。
图 3.HDFS HA 系统结构图

四个 PLinux 分区分别是 plinux09、plinux10、plinux11、plinux12.
NameNode: plinux09、plinux10
DataNode: plinux09、plinux10、plinux11、plinux12
ZooKeeper: plinux09、plinux10、plinux11
HBase: plinux10
Hive: plinux09
HDFS HA 的配置步骤:
架构图如下:
图 4.HDFS 利用 QJM 实现 HA 的架构图
Hadoop2.2.0 的源码编译
因为使用 IBM 的 JDK,目前需要在 Apache 官方网站上下载hadoop2.2.0的源码包,然后打上补丁进行手动编译。具体编译步骤请参考相关文档,这里不在详细描述。编译成功后,会自动生成 ./hadoop-dist/target/hadoop-2.2.0.tar.gz 文件。
安装配置 Hadoop2.2.0 之前,进行环境设置
在 PLinux 系统上创建一个普通用户,本文创建一个用户名"hadoop"的用户。
[root@plinux09 ~]# id hadoop uid=500(hadoop) gid=501(hadoop) groups=501(hadoop)
创建目录/bigdata 与/hadoopdata,并且使用 chown -R 命令把这两个目录属性设置成 hadoop 用户和组。其中/bigdata 目录下存放所有的开源组件,/hadoopdata 用于存放 hdfs 的 NameNode 与 DataNode 数据。
[root@plinux09 ~]# chown -R hadoop:hadoop /bigdata /hadoopdata/ [root@plinux09 ~]# ll / total 110 drwxr-xr-x. 9 hadoop hadoop 4096 Jan 9 22:17 bigdata drwxr-xr-x. 5 hadoop hadoop 4096 Jan 9 23:05 hadoopdata
关闭所有分区上的 SELinux 与 Iptables,关闭 Selinux 后需要重启系统才能生效。
[root@rhel226 ~]# vim /etc/selinux/config SELINUX=disabled [root@rhel226 ~]# service iptables stop [root@rhel226 ~]# chkconfig --level 345 iptables off
SSH 无密码验证配置
配置/etc/hosts 文件
[root@plinux09 ~]# cat /etc/hosts 10.10.10.24 plinux09 10.10.10.25 plinux10 10.10.10.27 plinux11 10.10.10.28 plinux12
在四个 plinux 系统上分别使用命令 ssh-keygen 生成的密钥对 id_rsa 和 id_rsa.pub,默认存放在"/home/hadoop/.ssh"目录下。
[hadoop@plinux09 ~]$ ssh-keygen -t rsa -P '' Generating public/private rsa key pair. Enter file in which to save the key (/home/test/.ssh/id_rsa): Created directory '/home/test/.ssh'. Your identification has been saved in /home/test/.ssh/id_rsa. Your public key has been saved in /home/test/.ssh/id_rsa.pub. The key fingerprint is: 89:23:48:5b:f9:e5:6b:9b:32:b5:66:81:24:b4:e6:3b test@plinux09 The key's randomart image is: +--[ RSA 2048]----+ | | | .. | | ..o. . | | . ++..+ . | | oo.o+.S | | ....o. | | . .oo | | E o.+o | | . =o | +-----------------+ [hadoop@plinux09 .ssh]$ ls -al /home/hadoop/.ssh -rw------- 1 hadoop hadoop 1675 Dec 23 13:36 id_rsa -rw-r--r-- 1 hadoop hadoop 395 Dec 23 13:36 id_rsa.pub
然后把所有的公钥的内容添加 authorized_keys 文件里,再把这个文件分别拷贝到每台机器的相同目录下。
[hadoop@plinux09 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
设置 authorized_keys 文件属性为 600,否则 ssh 无密码验证不能生效。
[hadoop@plinux09 ~]$ chmod 600 ~/.ssh/authorized_keys [hadoop@plinux09 ~]$ ll .ssh/ -rw-------. 1 hadoop hadoop 1193 Jan 9 21:06 authorized_keys -rw-------. 1 hadoop hadoop 1675 Jan 9 21:00 id_rsa -rw-r--r--. 1 hadoop hadoop 397 Jan 9 21:00 id_rsa.pub
配置/etc/security/limits.conf 文件,添加以下内容:
[hadoop@plinux09 ~]$ vim /etc/security/limits.conf hadoop soft nproc -1 hadoop hard nproc -1 hadoop soft nofile -1 hadoop hard nofile 65536 hadoop soft memlock -1 hadoop hard memlock -1 hadoop soft sigpending -1 hadoop hard sigpending -1
安装配置 Hadoop2.2.0,实现手动方式 NameNode HA 的切换
首先对编译生成的 hadoop-2.2.0.tar.gz 文件进行解压。
[hadoop@plinux09 bigdata]$ tar -zxvf hadoop-2.2.0.tar.gz
然后设置系统环境变量,修改~/.bash_profile 文件,添加以下内容:
export JAVA_HOME=/bigdata/ibm-java-ppc64-70 export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export HADOOP_HOME=/bigdata/hadoop export ZOOKEEPER=/bigdata/zookeeper export ZOO_LOG_DIR=/bigdata/zookeeper/data/logs export HBASE_HOME=/bigdata/hbase export HIVE_HOME=/bigdata/hive export PATH=$ZOOKEEPER/bin:$PROTOBUF/bin:$HBASE_HOME/bin:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME:\ $HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME:$HIVE_HOME/bin:$PATH export HADOOP_HOME_WARN_SUPPRESS=1
运行以下命令使之生效:
[hadoop@plinux09 bigdata]$ . ~/.bash_profile
配置 hdfs-site.xml 文件,以便实现手动方式的 NameNode HA 切换
[hadoop@plinux09 bigdata]$ vim /bigdata/hadoop/etc/hadoop/hdfs-site.xml
<!-- "dfs.nameservices"来定义 nameservices 的名字,这个名字可以任意定义,这里定义成"mycluster"。-->
<property> <name>dfs.nameservices</name> <value>mycluster</value> </property>
<!-- "dfs.ha.namenodes.[nameservice ID]" 来标识每个 NameNode,每个 NameNode 的标识必须唯一,并且最多有两个 NameNode。这里将两个 NameNode 分别取名为 nn1,nn2。-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- "dfs.namenode.rpc-address. [nameservice ID].[name node ID]" 来定义每个 NameNode 的 IP 或 Hostname 以及端口号。-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>plinux09:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>plinux10:8020</value>
</property>
<!-- "dfs.namenode.http-address. [nameservice ID].[name node ID]" 来定义 HTTP 服务的端口号。-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>plinux09:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>plinux10:50070</value>
</property>
<!-- "dfs.namenode.shared.edits.dir" 共享存储目录的位置。这是配置备份节点需要随时保持同步活动节点所作更改的远程共享目录,只能配置一个目录,这个目录挂载到两个 NameNode 上都必须是可读写的,且必须是绝对路径。-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://plinux09:8485;plinux10:8485;plinux11:8485/mycluster</value>
</property>
<!-- "dfs.client.failover.proxy.provider.[nameservice ID]" HDFS 客户端用来和活动的 namenode 进行联系的 Java 类。配置的 Java 类是用来给 HDFS 客户端判断哪个 NameNode 节点是活动的,当前是哪个 NameNode 处理客户端的请求。目前 Hadoop 唯一的实现类是 ConfiguredFailoverProxyProvider。-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<!-- "dfs.ha.fencing.methods" 用于停止活动 NameNode 节点的故障转移期间的脚本或 Java 类的列表。在任何时候只有一个 NameNode 处于活动状态,对于 HA 集群的操作是至关重要的,因此,在故障转移期间,启动备份节点前,首先需要确保活动节点处于等待状态,或者进程被中止,为了达到这个目的,您至少要配置一个强行中止的方法,或者回车分隔的列表,这是为了一个一个的尝试中止,直到其中一个返回成功,表明活动节点已停止。Hadoop 提供了两个方法:shell 和 sshfence,要实现您自己的方法,请看 org.apache.hadoop.ha.NodeFencer 类。-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(hdfs)
shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- "dfs.journalnode.edits.dir" 用来定义 journaldata 的存储路径。-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/journalnode</value>
</property>
*注意: sshfence(hdfs)后是"回车",这是源代码里定义成这种格式,否则使用其它符号 HA 将不能正常切换。
然后编辑core-site.xml 文件。
[hadoop@plinux09 bigdata]$ vim /bigdata/hadoop/etc/hadoop/core-site.xml
<!-- "fs.defaultFS " 定义 HDFS 的名称为 mycluster,即命名空间。-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- "fs.default.name" 指定 NameNode 的 IP 地址和端口号。-->
<property>
<name>fs.default.name</name>
<value>hdfs://mycluster</value>
</property>
配置完 hdfs-site.xml 与 core-site.xml 文件后,启动 plinux09,plinux10,plinux11 上 journalnode。
[hadoop@plinux09 bigdata]$ hadoop/sbin/hadoop-daemons.sh --hostnames 'plinux09 plinux10 plinux11'
start jouralnode
starting journalnode, logging to /bigdata/hadoop/logs/hadoop-hadoop-journalnode-plinux09.out
starting journalnode, logging to /bigdata/hadoop/logs/hadoop-hadoop-journalnode-plinux10.out
starting journalnode, logging to /bigdata/hadoop/logs/hadoop-hadoop-journalnode-plinux11.out
然后对 plinux09 的 NameNode 进行格式化.
[hadoop@plinux09 ~]$ hadoop namenode –format *** 14/01/12 22:25:05 INFO util.ExitUtil: Exiting with status 0 14/01/12 22:25:05 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at plinux09/9.110.75.104 ************************************************************/
在返回的结果中,显示 Exiting with status 0 表示格式化成功,否则表示格式化失败,如果失败,请查看 NameNode 的日志文件 hadoop/logs/hadoop-hadoop-namenode-plinux09.log
NameNode 格式化完成后,启动主节点 plinux09 的 NameNode
[hadoop@plinux09 bigdata]$ hadoop-daemon.sh start namenode starting namenode, logging to /bigdata/hadoop/logs/hadoop-hadoop-namenode-plinux09.out
然后对 standby 节点 plinux10 的 NameNode 上进行元数据同步。
[hadoop@plinux10 ~]$ hdfs namenode -bootstrapStandby
接着启动 standby 节点 plinux10 上的 NameNode。
[hadoop@plinux10 ~]$ hadoop-daemon.sh start namenode starting namenode, logging to /bigdata/hadoop/logs/hadoop-hadoop-namenode-plinux10.out
最后分别在所有节点(plinux09, plinux10, plinux11, plinux12)上启动 DataNode。
[hadoop@plinux09 bigdata]$ hadoop-daemon.sh start datanode starting datanode, logging to /bigdata/hadoop/logs/hadoop-hadoop-datanode-plinux09.out ***
可以使用 hdfs haadmin 帮助命令来查看 HA 的状态或者配置 HA 的节点。
[hadoop@plinux09 bigdata]$ hdfs haadmin
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|jobtracker:port> specify a job tracker
-files <comma separated list of files>specify comma separated files to be copied to the \
map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include
in the classpath.
-archives <comma separated list of archives>specify comma separated archives to
be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
激活 plinux09 节点上的 NameNode。
[hadoop@plinux09 bigdata]$ hdfs haadmin -transitionToActive nn1
查看两个节点上 NamNode 的状态。
[hadoop@plinux09 conf]$ hdfs haadmin -getServiceState nn1 Active [hadoop@plinux09 conf]$ hdfs haadmin -getServiceState nn2 Standby
进行手动 NameNode 的切换测试。
[hadoop@plinux09 bigdata]$ hdfs haadmin -failover nn1 nn2 Failover to NameNode at plinux10/9.110.75.105:8020 successful [hadoop@plinux09 bigdata]$ hdfs haadmin -getServiceState nn1 Standby [hadoop@plinux09 bigdata]$ hdfs haadmin -getServiceState nn2 active
下图为 Web 上查看 NameNode 的状态
图 5 .Web 上查看 plinux09 的 NameNode 状态
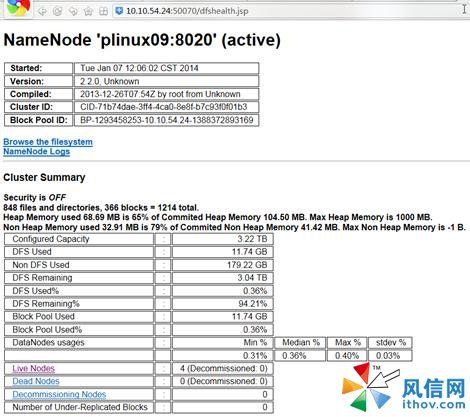
图 6 .Web 上查看 plinux10 的 NameNode 状态
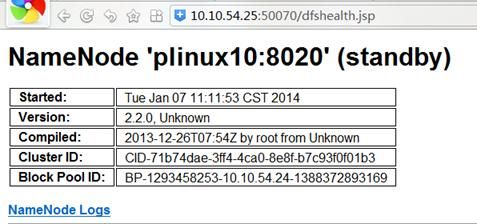
通过上面的配置与测试,可以成功实现 PLinux 上 HDFS 的 NameNode 手动切换。
安装配置 Hadoop2.2.0,实现自动方式 NameNode HA 的切换
下面进行自动切换配置。
在 hdfs-site.xml 里添加:
<!-- "ha.zookeeper.quorum" 打开自动切换 NameNode 的功能。-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在 core-site.xml 里添加:
<!-- "ha.zookeeper.quorum" 指定用于 HA 的 ZooKeeper 集群机器列表,并且列表数目一定是奇数。-->
<property>
<name>ha.zookeeper.quorum</name>
<value>plinux09:2181,plinux10:2181,plinux11:2181</value>
</property>
配置完上面两个文件,分别在 plinux09、plinux10、plinux11 上启动 ZooKeeper Server。
[hadoop@plinux09 hadoop]$ zkServer.sh start JMX enabled by default Using config: /bigdata/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [hadoop@plinux10 ~]$ zkServer.sh start JMX enabled by default Using config: /bigdata/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [hadoop@plinux11 ~]$ zkServer.sh start JMX enabled by default Using config: /bigdata/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
然后格式化 ZKFC
[hadoop@plinux09 hadoop]$ hdfs zkfc -formatZK =============================================== The configured parent znode /hadoop-ha/mycluster already exists. Are you sure you want to clear all failover information from ZooKeeper? WARNING: Before proceeding, ensure that all HDFS services and failover controllers are stopped! =============================================== Proceed formatting /hadoop-ha/mycluster? (Y or N) Y 14/01/13 02:19:24 INFO ha.ActiveStandbyElector: Recursively deleting /hadoop-ha/mycluster from ZK... 14/01/13 02:19:24 INFO ha.ActiveStandbyElector: Successfully deleted /hadoop-ha/mycluster from ZK. 14/01/13 02:19:24 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK. 14/01/13 02:19:24 INFO zookeeper.ZooKeeper: Session: 0x2438a6d6f0a0000 closed 14/01/13 02:19:24 INFO zookeeper.ClientCnxn: EventThread shut down
* 注意:格式化 ZooKeeper 之前必须先关闭 HDFS Services。运行用 dfs-stop.sh 命令来关闭。
格式化完毕后启动 NameNode,DataNode, journalnode 和 zkfc。
[hadoop@plinux09 hadoop]$ start-dfs.sh Starting namenodes on [plinux09 plinux10] plinux10: starting namenode, logging to /bigdata/hadoop/logs/hadoop-hadoop-namenode-plinux10.out plinux09: starting namenode, logging to /bigdata/hadoop/logs/hadoop-hadoop-namenode-plinux09.out plinux11: starting datanode, logging to /bigdata/hadoop/logs/hadoop-hadoop-datanode-plinux11.out plinux09: starting datanode, logging to /bigdata/hadoop/logs/hadoop-hadoop-datanode-plinux09.out plinux10: starting datanode, logging to /bigdata/hadoop/logs/hadoop-hadoop-datanode-plinux10.out Starting journal nodes [plinux09 plinux10 plinux11] plinux11: starting journalnode, logging to /bigdata/hadoop/logs/hadoop-hadoop-journalnode-plinux11.out plinux10: starting journalnode, logging to /bigdata/hadoop/logs/hadoop-hadoop-journalnode-plinux10.out plinux09: starting journalnode, logging to /bigdata/hadoop/logs/hadoop-hadoop-journalnode-plinux09.out Starting ZK Failover Controllers on NN hosts [plinux09 plinux10] plinux10: starting zkfc, logging to /bigdata/hadoop/logs/hadoop-hadoop-zkfc-plinux10.out plinux09: starting zkfc, logging to /bigdata/hadoop/logs/hadoop-hadoop-zkfc-plinux09.out
启动好后,其中一台 NameNode 会自动被激活成 active,另一台是 standby 状态。
[hadoop@plinux09 hadoop]$ hdfs haadmin -getServiceState nn1 Standby [hadoop@plinux09 hadoop]$ hdfs haadmin -getServiceState nn2 Active
通过 Kill NameNode 的进程来进行 NameNode HA 的自动切换测试。
[hadoop@plinux10 ~]$ ps -ef|grep -i namenode
hadoop 9378 1 1 02:23 ? 00:00:18 /bigdata/ibm-java-ppc64-70/bin/java –
***
org.apache.hadoop.hdfs.server.namenode.NameNode
[hadoop@plinux10 ~]$ kill -9 9378
[hadoop@plinux09 conf]$ hdfs haadmin -getServiceState nn1
Active
[hadoop@plinux09 conf]$ hdfs haadmin -getServiceState nn2
14/01/13 02:56:09 INFO ipc.Client: Retrying connect to server: plinux10/9.110.75.105:8020.
Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(
maxRetries=1, sleepTime=1 SECONDS)
Operation failed: Call From plinux09/9.110.75.104 to plinux10:8020 failed on connection exception:
java.net.ConnectException: Connection refused; For more details see:
http://wiki.apache.org/hadoop/ConnectionRefused
当 kill plinux10 上 active NameNode 的进程后,在短时间内 NameNode 自动切换到 plinux09 上。
基于 HDFS HA 来配置 Hbase
基于 HDFS HA 来配置 Hbase 的方法如下:
配置 hbase-site.xml 文件,添加如下内容
[hadoop@plinux09 bigdata]$ vim /bigdata/hbase/conf/hbase-site.xml
<!-- "hbase.rootdir"用于 HA 节点的 NameService 来配置 HBase。-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://mycluster:60000</value>
</property>
配置好后启动 Hbase 服务。
[hadoop@plinux10 ~]$ start-hbase.sh starting master, logging to /bigdata/hbase/logs/hbase-hadoop-master-plinux10.out plinux12: starting regionserver, logging to /bigdata/hbase/logs/hbase-hadoop-regionserver-plinux12.out plinux11: starting regionserver, logging to /bigdata/hbase/logs/hbase-hadoop-regionserver-plinux11.out plinux09: starting regionserver, logging to /bigdata/hbase/logs/hbase-hadoop-regionserver-plinux09.out plinux10: starting regionserver, logging to /bigdata/hbase/logs/hbase-hadoop-regionserver-plinux10.out
图 7.登录 plinux10 的 Web 查看 HBase 的状态

通过以上配置,Hbase 可以在 HDFS HA 的环境中正常工作。这样一套基本的 Hadoop HDFS 的 HA 解决方案配置完成。
总结
随着 Hadoop 日渐成熟,越来越多的企业使用它来分析处理日常大量的数据。随之而来的安全性,可靠性和性能问题被提出。本文使用开源的软件结合 IBM CAMP 服务器的强大性能实现高可用性来满足客户的需求。