我的文档:进程管理与调度
task结构
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack; 指向threadinfo
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
unsigned int policy;
int oncpu //被task_running判断死否运行(SMP),switch_context的时候会修改
struct rq:每个cpu的可运行队列中都有一个root_domain和sched_domain
struct root_domain *rd; //
struct sched_domain *sd;
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
SCHED_LOAD_SCALE == 2048
调度相关API:
sched_get_priority_min 获取实时进程的最小优先级
sched_get_priority_max 获取实时进程的最大优先级
sched_getscheduler 获取进程的调度策略policy
sched_setscheduler 设置进程的调度策略policy
nice 改变当前进程的优先级(nice值)
sched_getparam 获取实时进程的优先级
sched_setparam 设置实时进程的优先级
sched_rr_get_interval 获取进程的默认时间片
sched_getaffinity 获取一个进程的cpu亲和性
sched_setaffinity 设置一个进程的cpu亲和性
进程优先级
int prio, static_prio, normal_prio;
unsigned int rt_priority;
unsigned int policy;
rt_priority是实时进程的配置优先级 , 范围:1 ~ 99 ,越大优先级越高,非实时进程的rt_priority一定是0
static_prio是非实时进程的配置优先级,范围: 100 ~ 139 ,越大优先级越低,实时进程可以有static_prio,nice调用也可以改变static_prio的值,但不起作用。
normal_prio 是根据rt_priority 或者static_prio及调度policy计算得到的(参考函数:normal_prio) ,范围: 0 ~ 139 越大优先级越低
rt_priority static_prio 是用户使用的优先级,将被统一转化为normal_prio 以便操作系统统一处理,用户可以改变rt_prority static_prio的值
prio 是调度器使用的优先级,对于普通进程,prio等于normal_prio;对于实时进程,一般情况下prio也等于noormal_prio,但为解决优先级翻转的问题,prio根据情况被提升
进程的生命周期
进程的表示
进程的相关系统调用
调度器
----------------------------------------------- -------
| --------- ---------- | 上下文切换 | |
| | 主调度器 | | 周期调度器 | |---------------- | CPU |
| --------- ---------- | | |
----------------------------------------------- -------
|
| 选择进程
|
-------------------------------------
| _____ ____ ____ |
| |_____| -> |____| -> |____| | 调度器类
| / / \ |
----/----------/------------\--------
/ ____ /_____ |\
/ / /\ \ | \
__/ __/ __/ \ __ \__ __| \__
|__| |__| |__| |__| |__| |__| |__| 进程
1.主调度器 :schedule
schedule()
{
...
preempt_disable(); /*1.关闭抢占*/
prev = rq->curr;
...
clear_tsk_need_resched(prev); /*2.清除need_sched标志*/
...
deactivate_task /*3.如果主动让出cpu,那么就从可 运行队列中删除*/
...
pre_schedule(rq, prev); /*4.pre_schedule,只对使用SMP的RT调度类有效*/
...
put_prev_task(rq, prev); /*5.put当前任务*/
...
next = pick_next_task(rq); /*6.挑选下一个任务*/
...
context_switch(rq, prev, next); /*7.切换上下文*/
...
post_schedule(rq); /*8.post_schedule,只对SMP的RT调度类有效*/
...
preempt_enable_no_resched(); /*9.打开抢占*/
}
2.周期性调度器:scheduler_tick
task_tick_rt :把SCHED_RR进程的时间片减去1
task_tick_fair: 检查当前进程是否连续运行时间超时(不同优先级的进程超时时限不一样)
3.try_to_wakeup:
try_to_wake_up(struct task_struct *p, unsigned int state,
int wake_flags)
{
this_cpu = get_cpu(); /*当前cpu*/
rq = orig_rq = task_rq_lock(p, &flags); /*被唤醒进程的cpu与rq(上次cpu)*/
cpu = task_cpu(p);
orig_cpu = cpu;
if (p->sched_class->task_waking) /*唤醒进程*/
p->sched_class->task_waking(rq, p);
cpu = select_task_rq(p, SD_BALANCE_WAKE, wake_flags); /*为唤醒进程选择cpu*/
if (cpu != orig_cpu)
set_task_cpu(p, cpu);
activate_task(rq, p, 1); /*把唤醒的进程挂入到队列*/
success = 1;
check_preempt_curr(rq, p, wake_flags); /*唤醒的进程挂入的队列所在的cpu是否需要抢占*/
p->state = TASK_RUNNING; /*设置唤醒进程为RUNNING状态*/
/*唤醒后做点事,如果唤醒进程是rt进程,如果没有尽快调度,push该进程*/
if(p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
put_cpu(); /*这里是一个调度点,如果set_needsched,就会发生一次调度*/
}
check_preempt_curr --> check_preempt_curr_rt :
如果新唤醒的进程优先级高于当前进程,则抢占当前进程。
如果新唤醒进程与当前进程的优先级相等,如果出现其他cpu可以接受当前进程但不可以接受新唤醒的进程,那么就迁移当前进程到目标cpu,并在本cpu上运行新唤醒的进程
3.RT调度类:
每一个优先级都有一个runing_queue,共99个队列:
------------------------------------------ |queue_prio1 | -> task1->task2 ->taskn | ------------------------------------------ |queue_prio2 | ->task1->task2 ->taskn | ------------------------------------------ |... | | ------------------------------------------ |queue_prio98 | ->task1->task2 ->taskn | ------------------------------------------ |queue_prio99 |->task1->task2 ->taskn | ------------------------------------------
RT调度策略比较简单,从当前最高优先级的的队列中取出第一个task即可。
如果有高优先级的RT进程被唤醒,将会抢占当前进程
RT类有2个调度policy: SCHED_FIFO SCHED_RR, SCHED_RR调度策略的进程运行一定的时间片后会被切换出。
队列array中保存着所有的可运行task,包括current
rt_nr_running中保存着所有的可运行task,包括current
pick_next_task_rt 之后不会修改array和rt_nr_running
dequeue_task_rt会从array和rt_nr_running中删除task
cpu的优先级(cpuprio):为了实时进程的调度,该cpu实时队列的最高优先级就是代表该cpu的优先级,在push_task_rt的时候就会把实时进程push到最低优先级的cpu。
select_task_rq_rt:为唤醒进程选择cpu,要考虑到最低优先级的cpu,task上次运行的cpu即cache预热过的cpu,cache距离最近的cpu。
static int select_task_rq_rt(struct task_struct *p, int sd_flag, int flags)
{
struct rq *rq = task_rq(p);
if (sd_flag != SD_BALANCE_WAKE)
return smp_processor_id();
/*rq->curr是rt进程,尽量find_lowest_rq到一个cpu,否则使用原cpu*/
if (unlikely(rt_task(rq->curr)) &&
(p->rt.nr_cpus_allowed > 1)) {
int cpu = find_lowest_rq(p);
return (cpu == -1) ? task_cpu(p) : cpu;
}
return task_cpu(p);
}
find_lowest_rq:找到所有优先级低于被唤醒进程的cpu,如果有多个,首先尽量使用原cpu,再根据sched_domain中距离原cpu最近的cpu,以便使用cache,
RT类的强制调度:
4. CFS调度类:
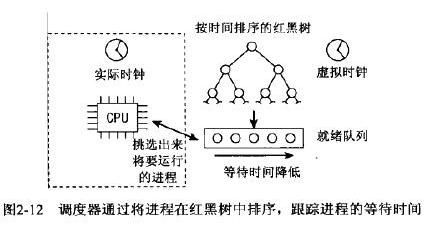
CFS维持一个系统虚拟时钟,红黑树中按照等待时间(降序)存放着可运行进程队列,只需要pick第一个进程让其运行即可。
runtime -> vruntime:物理运行时间到虚拟运行时间的转化是按照方向优先级的,越高的优先级权值越小
NICE0, vruntime = delta_runtime*1
NICE +5, runtime = delta_runtime*1.1
NICE -5 ,runtime = delta_runtime*0.8
tasks_timeline.rb_node:红黑树中挂接着可运行的task,不包括current
nr_running中保存着可运行的进程数,包括current
pick_next_task_fair会从红黑树中删除current,但不会修改nr_running
dequeue_task_fair会从红黑树中删除current,并修改nr_running
select_task_rq_fair:为唤醒进程选择cpu,从smp_processor_id()所在的sched_domain开始,直到找到一个不超载的sched_domain,然后再优先选择原有cpu/原有cpu的兄弟,再其他域的最闲cpu
CFS类的强制调度:
5.idle调度类
调度
- 自愿调度/自愿释放cpu:可随时进行,在内核中,一个进程可以通过调用schedule启动一次调度
- 强制调度(也叫抢占):scheduler_tick可能会set当前进程need_sched标志
内核代码可以根据情况设置(set)t当前进程need_sched标志。比如中断的到来唤醒了某一个比当前进程优先级更高的进程。
need_sched标志不会立马引起调度,只是告诉cpu:现在需要调度啦! 在最近的抢占点才回发生真正的进程切换。
抢占的时机:
- 用户态抢占的时机:从系统调用返回用户空间 schedule()
从中断处理程序(包括异常处理程序)返回到用户空间 schedule()
- 内核态抢占的时机:当从中断处理程序返回到内核空间之前,preempt_schedule_irq
当内核代码再次变成可抢占时,preempt_enable()
当一个task在内核中显示的调用schedule()
当一个task在内核阻塞时(这将导致调用schedule)
内核中不可抢占点:
- 内核正进行中断处理。在Linux内核中进程不能抢占中断(中断只能被其他中断中止、抢占,进程不能中止、抢占中断),在中断例程中不允许进行进程调度。进程调度函数schedule()会对此作出判断,如果是在中断中调用,会打印出错信息。
- 内核正在进行中断上下文的Bottom Half(中断的底半部)处理。硬件中断返回前会执行软中断,此时仍然处于中断上下文中。
- 内核正在执行调度程序Scheduler。抢占的原因就是为了进行新的调度,没有理由将调度程序抢占掉再运行调度程序。
- 内核的代码段正持有spinlock自旋锁、writelock/readlock读写锁等锁,处干这些锁的保护状态中。内核中的这些锁是为了在SMP系统中短时间内保证不同CPU上运行的进程并发执行的正确性。当持有这些锁时,内核不应该被抢占,否则由于抢占将导致其他CPU长期不能获得锁而死等。
- 内核正在对每个CPU“私有”的数据结构操作(Per-CPU date structures)。在SMP中,对于per-CPU数据结构未用spinlocks保护,因为这些数据结构隐含地被保护了(不同的CPU有不一样的per-CPU数据,其他CPU上运行的进程不会用到另一个CPU的per-CPU数据)。但是如果允许抢占,但一个进程被抢占后重新调度,有可能调度到其他的CPU上去,这时定义的Per-CPU变量就会有问题,这时应禁抢占
- (我阅读代码的猜测)有时候系统可能需要临时的关中断,这是也不允许调度,否则就 不能再打开中断
ksofirqd执行do_softirq时候会首先preempt关闭
#define preempt_count() (current_thread_info()->preempt_count) _____________________________________________________ | 1 | 1 | 10 | 8 | 8 | |________________|_____|__________|_________|_________| | PREEMPT_ACTIVE | NMI | HARDIRQ | SOFTIRQ | PREEMPT | |________________|_____|__________|_________|_________|
preempt_schedule 抢占: 检查,preempt_count 不允许抢占/irqs_disabled不允许抢占
SMP调度
- CPU负荷必须尽可能公平地在所有处理器上共享。如果一个cpu负责处理3个并发应用,而另外一个只能处理空闲进程,那是没有意义。
- 进程与cpu之间的affinity必须是可设置的。例如:有4个cpu的系统中,可以将密集型应用程序绑定到前3个cpu,而剩余的(交互式)进程则在第4个cpu上运行。
- 内核必须能够将进程从一个cpu迁移到另外一个。但该选项必须谨慎使用,因为它会严重危害性能。在小型的SMP系统上,CPU上的高速缓存是最大的问题。对于真正的大型系统,cpu与迁移进程此前使用的物理内存距离可能有若干米,因此对该进程内存的访问代价高昂。
SMP之负载均衡
select_task_rq
load_balance
move_one_task
SMP调度之rt类
rt_overloaded:root_domain中的任何一个cpu上有超过2个rt进程
pre_schedule -> pull_task:当rt_overloaded发生时,把其他cpu上等待队列上RT prio高于本cpu等待队列最高优先级pull(拉)到本cpu上运行,当然是其他各个CPU队列中最高的那个。
post_schedule ->push_task:push当前 队列中多余的rt进程,到lowest_rq
select_task_rq 用于决定唤醒进程需要放那个CPU队列,同push_task一样。
定时负载均衡,schedule_tick会触发SCHED_SOFTIRQ软中断,调用run_rebalance_domains->rebalance_domains->load_balance ,对于RT这里不用做什么,RT只是保证实时性不用保证公平
migration_thread与cpu绑定有关
SMP调度之cfs类
定时负载均衡
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
update_rq_clock(rq);
update_cpu_load(rq);
curr->sched_class->task_tick(rq, curr, 0);
raw_spin_unlock(&rq->lock);
perf_event_task_tick(curr, cpu);
#ifdef CONFIG_SMP
rq->idle_at_tick = idle_cpu(cpu);
trigger_load_balance(rq, cpu);
#endif
}
curr->sched_class->task_tick->task_tick_fair->check_preempt_tick:根据delta_exec、sysctl_sched_min_granularity决定是否调度
schedule_tick会触发SCHED_SOFTIRQ软中断,软中断处理中调用run_rebalance_domains->rebalance_domains->load_balance ,找到最忙的cpu,并pull进程到本cpu调度
cpu负载-weight 计算方法:
static void
account_entity_enqueue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_add(&cfs_rq->load, se->load.weight);
if (!parent_entity(se))
inc_cpu_load(rq_of(cfs_rq), se->load.weight);
if (entity_is_task(se)) {
add_cfs_task_weight(cfs_rq, se->load.weight);
list_add(&se->group_node, &cfs_rq->tasks);
}
cfs_rq->nr_running++;
se->on_rq = 1;
}
static inline void inc_cpu_load(struct rq *rq, unsigned long load)
{
update_load_add(&rq->load, load);
}
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
{
lw->weight += inc;
lw->inv_weight = 0;
}
域与控制组
__build_sched_domains初始化调度域 rd
CONFIG_GROUP_SCHED
CONFIG_RT_GROUP_SCHED:默认使用init_task_group(在没有CONFIG_CGROUP_SCHED和CONFIG_USER_SCHED情况下)
CONFIG_GROUP_SCHED
CONFIG_FAIR_GROUP_SCHED
CONFIG_RT_GROUP_SCHED
CONFIG_USER_SCHED
CONFIG_CGROUP_SCHED
struct cgroup_subsys cpu_cgroup_subsys = {
.name = "cpu",
.create = cpu_cgroup_create,
.destroy = cpu_cgroup_destroy,
.can_attach = cpu_cgroup_can_attach,
.attach = cpu_cgroup_attach,
.populate = cpu_cgroup_populate,
.subsys_id = cpu_cgroup_subsys_id,
.early_init = 1,
};
struct cgroup_subsys mem_cgroup_subsys = {
.name = "memory",
.subsys_id = mem_cgroup_subsys_id,
.create = mem_cgroup_create,
.pre_destroy = mem_cgroup_pre_destroy,
.destroy = mem_cgroup_destroy,
.populate = mem_cgroup_populate,
.attach = mem_cgroup_move_task,
.early_init = 0,
.use_id = 1,
};
struct cgroup_subsys ns_subsys = {
.name = "ns",
.can_attach = ns_can_attach,
.create = ns_create,
.destroy = ns_destroy,
.subsys_id = ns_subsys_id,
};
struct cgroup_subsys freezer_subsys = {
.name = "freezer",
.create = freezer_create,
.destroy = freezer_destroy,
.populate = freezer_populate,
.subsys_id = freezer_subsys_id,
.can_attach = freezer_can_attach,
.attach = NULL,
.fork = freezer_fork,
.exit = NULL,
};
struct cgroup_subsys debug_subsys = {
.name = "debug",
.create = debug_create,
.destroy = debug_destroy,
.populate = debug_populate,
.subsys_id = debug_subsys_id,
};
struct cgroup_subsys cpuset_subsys = {
.name = "cpuset",
.create = cpuset_create,
.destroy = cpuset_destroy,
.can_attach = cpuset_can_attach,
.attach = cpuset_attach,
.populate = cpuset_populate,
.post_clone = cpuset_post_clone,
.subsys_id = cpuset_subsys_id,
.early_init = 1,
};
struct cgroup_subsys cpu_cgroup_subsys = {
.name = "cpu" "task_group",
.create = cpu_cgroup_create,
.destroy = cpu_cgroup_destroy,
.can_attach = cpu_cgroup_can_attach,
.attach = cpu_cgroup_attach,
.populate = cpu_cgroup_populate,
.subsys_id = cpu_cgroup_subsys_id,
.early_init = 1,
}
struct cgroup_subsys cpuacct_subsys = {
.name = "cpuacct",
.create = cpuacct_create,
.destroy = cpuacct_destroy,
.populate = cpuacct_populate,
.subsys_id = cpuacct_subsys_id,
};
struct cgroup_subsys blkio_subsys = {
.name = "blkio",
.create = blkiocg_create,
.can_attach = blkiocg_can_attach,
.attach = blkiocg_attach,
.destroy = blkiocg_destroy,
.populate = blkiocg_populate,
.subsys_id = blkio_subsys_id,
.use_id = 1,
};
struct cgroup_subsys net_cls_subsys = {
.name = "net_cls",
.create = cgrp_create,
.destroy = cgrp_destroy,
.populate = cgrp_populate,
.subsys_id = net_cls_subsys_id,
};
init_task_group
cgroup_init_early -> init_task.cgroups = &init_css_set;
list_add(&init_task_group.list, &task_groups);
INIT_LIST_HEAD(&init_task_group.children);
Completely Fair Scheduler完全公平调度(CFS)
http://hi.baidu.com/daxuelangren/item/b71f810928ec0837a2332a72
6)Processor type and features-->SMT (Hyperthreading) scheduler support
该条目为y或者n,为y时定义CONFIG_SCHED_SMT宏。定义它的目的是为了对支持超线程的CPU提供能好的调度功能。我举例说明一下:比如一 个系统有两个CPU,每个CPU又支持超线程,那么系统中有四个逻辑CPU,我们将这个四个CPU记为C00, C01, C10, C11,其中C00与C01是一个物理CPU上的两个硬件线程,而C10与C11则是另一个物理CPU上的两个硬件线程。假设某一个时刻系统中有两个线程 在执行,在没有定义CONFIG_SCHED_SMT宏的情况下内核很可能会将这两个线程分别调度到C00与C01上去,但这是不优化的,因为C00与 C01是一个物理CPU上的两个硬件线程,它们共享了许多硬件资源,导致两个线程运行时并不能充分发挥这个系统的资源优势;而定义了 CONFIG_SCHED_SMT宏的情况下,内核的调度器就会将这两个线程调度到位于不同物理CPU的逻辑CPU上,比如C00与C10上。
乍一看似乎只要你的CPU支持超线程,那么你就应该勾选这一项,但是我认为并不一定这样。比如你的系统是单CPU并且支持超线程,那么这个时候 CONFIG_SCHED_SMT宏对于提高调度效果并没有什么意义(当然前提是我对内核调度器的理解无误的话:)),而且定义 CONFIG_SCHED_SMT宏还会对调度增加额外的开销。
我的建议是:在你的CPU支持超线程的前提下,只有当你的系统有多个CPU或者支持多核的时候才有必要勾选这一项。
7)Processor type and features-->Multi-core scheduler support
该条目为y或者n,为y时定义CONFIG_SCHED_MC宏。它的作用很类似于前面提到的CONFIG_SCHED_SMT,只不过它针对多核 (multi-core)。我的建议是只有你的系统拥有多个物理CPU时才有必要勾选。比如我家里的机器CPU为单AMD Athlon 64 X2 4200+,虽然是双核,但只有一个物理CPU,我就没有必要定义这个宏。
【内核】调度域(Scheduling Domain)
Linux多cpu负载平衡-线程迁移
http://www.linuxidc.com/Linux/2011-04/34728.htm
Linux 调度器发展简述
http://www.ibm.com/developerworks/cn/linux/l-cn-scheduler/
[kernel] linux在多核处理器上的负载均衡原理 from 淘宝核心系统团队博客 by 董昊
http://www.starming.com/index.php?action=plugin&v=wave&tpl=union&ac=viewgrouppost&gid=33263&tid=8042
完全公平调度CFS探索之实现
http://blog.chinaunix.net/uid-25942458-id-3395887.html
context_switch( )上下文切换
http://blog.csdn.net/b02042236/article/details/6076473
优化方向:
OpenMp 多核并发 任务分解 数据分解
网络 gso 光口 udp承载 (最优原则,二层三层特点考虑)
IO 存储读写速度
cpu占用率,调度粒度 负载均衡粒度
多核监听,一般一个cpu开2个监听线程